







 超级会员免费看
超级会员免费看
 本文探讨了强化学习中的Trajectory概念,它是一系列状态动作序列,其奖励总和构成目标。为了最大化期望回报,文章介绍了使用梯度上升法优化参数的策略,并讨论了在实际计算中如何通过选取部分轨迹(m个)来有效更新模型参数。
本文探讨了强化学习中的Trajectory概念,它是一系列状态动作序列,其奖励总和构成目标。为了最大化期望回报,文章介绍了使用梯度上升法优化参数的策略,并讨论了在实际计算中如何通过选取部分轨迹(m个)来有效更新模型参数。
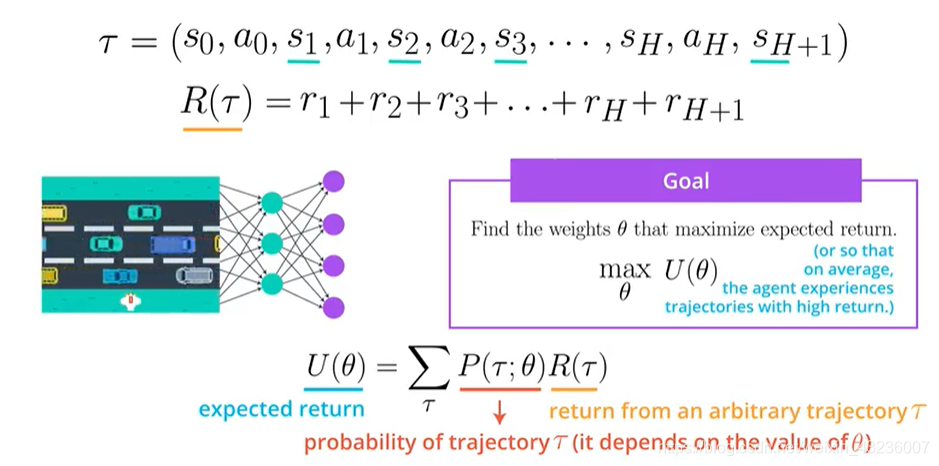
Trajectory是一段状态动作序列,没有对长度的限制,R是一段Trajectory的奖励之合

我们的的目标是找到参数最大化期望回报,用的是每个概率下的Trajectory乘以它的总的reward
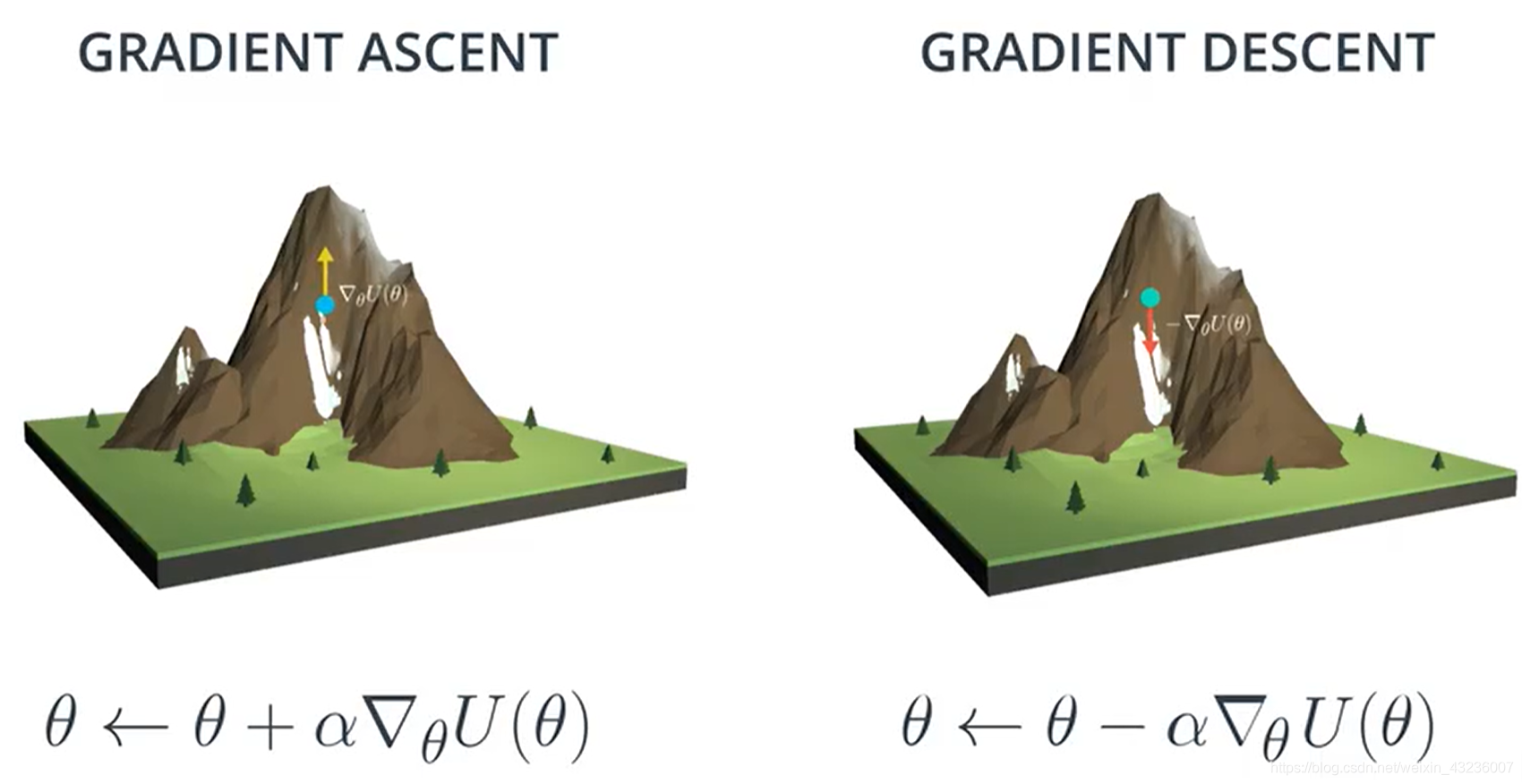
为了最大化expected return,我们使用梯度上升的方法,来找到到参数sita。
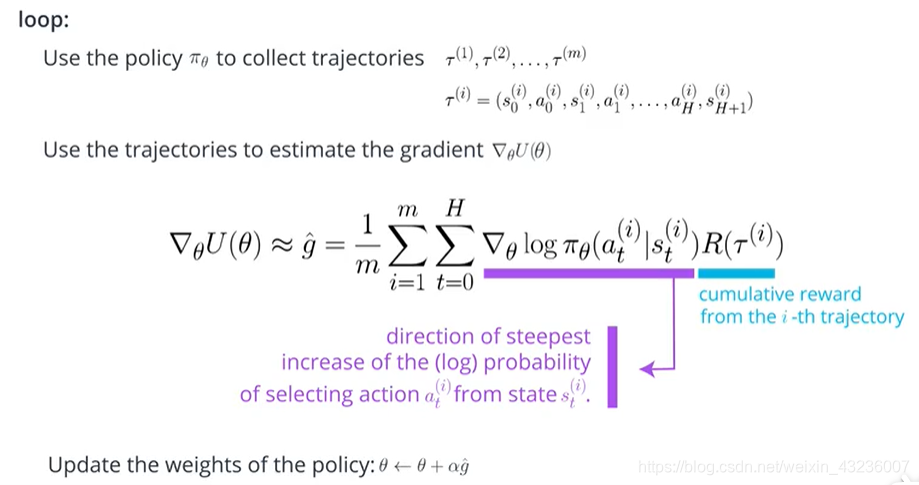
如果使用每个trajectory的话计算量会很大,所以只选取其中m个进行计算,那么如何用收集到m个trajectory来更新参数呢?i是代表第几个trajectory


















05-27
 8399
8399
8399
10-15
833
833
06-12
2161
2161
11-03
1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











