







任务
将昨天完成的已进行词性标注的摘要列进行组块分析,并将两个结果放到Excel中进行的对比分析
代码
import nltk
from nltk.tokenize import sent_tokenize
from stanfordcorenlp import StanfordCoreNLP
from nltk.tree import Tree
import numpy as np
import pandas as pd
import re
nlp = StanfordCoreNLP(r'E:\网页下载\stanford-corenlp-4.2.2')#程序内调用
def chunking(word_broken):
# 写一个匹配名词的模式
pattern = """
NP: {<DT><VBG|VBN>*<JJ.*>*<VBG|VBN>*<NN.*>*<VBG|VBN>*<JJ.*>*<VBG|VBN>*<NN.*>+}#必有定词修饰,包含前置定语与后置定语两种情形
{<VBG|VBN>*<JJ.*>*<VBG|VBN>*<NN.*>*<VBG|VBN>*<JJ.*>*<VBG|VBN>*<NN.*>+}#无定词修饰
"""
# 定义组块分析器
chunker=nltk.RegexpParser(pattern)
result=chunker.parse(word_broken)
return result
path='E://网页下载/20210915-ASML-高被引专利.csv'
path_end='E://网页下载/0-500_processed_1.csv'
with open(path,encoding="utf-8") as file:
d = pd.read_csv(file)
df1=pd.DataFrame(d["摘要"])
value_1=[]
value_2=[]
data={"摘要分词":value_1,"组块分析":value_2}
for row in df1['摘要']:
text = re.sub('%','',row)
text = re.sub('[\d]','',text)
text = re.sub(r'\-','_',text)
sents=sent_tokenize(text)
words=[]
chunk=[]
for sent in sents:
word=nlp.pos_tag(sent)#词性标注,列表内元素为元组
result=chunking(word)
words.append(word)
chunk.append(result)
tree=nltk.Tree('SS',chunk)
value_1.append(words)
value_2.append(tree)
df2=pd.DataFrame(data)
df2.to_csv(path_end,columns=["摘要分词","组块分析"])
nlp.close()
#35秒
#33秒
总结
一、组块分析——CHUNKING
1、Noun Phrase Chunking(名词短语词块划分)
grammar = "NP:{<DT>?<JJ>*<NN>}"
补充概念:
词缝:一个不包含在词块中的一个词符序列。以下划线部分就是一个词缝
来自 https://blog.csdn.net/Q_s_qiu/article/details/107198638

2、Exploring Text Corpora(用正则表达式进行词块划分)
一个正则表达式字符串中,可以写多个正则表达式,词块划分器轮流应用其规则,依次的更新词块结构,直到所有规则都被调用完,返回划分完的词块结构。当匹配重叠时,最左边的匹配优先。
二、数据输出
学到了如何同时将两列导入到Excel中
三、分块后结构
chunking分块之后,为一个树结构,比如:
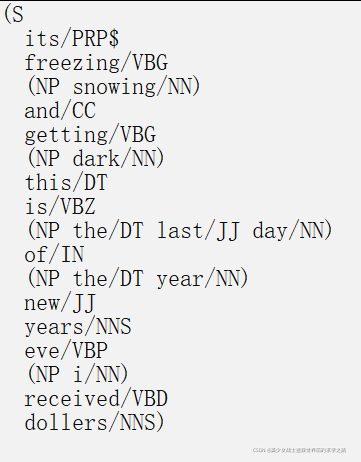
其中,s为根节点,而其余词语NP结构为其子节点,为同级关系,如下图所示:

但若将一段话以一句一句的形式进行分块,可以写成:
words=[]
for sent in sents:
word_1=wo_broken(sent)#分词
word_2=chunking(word_1)#分块,返回结果为树结构
words.append(word_2)
tree=nltk.Tree('SS',words)
可参照:https://blog.csdn.net/wangsiji_buaa/article/details/79973578
处理完结果为:
















 398
398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









