







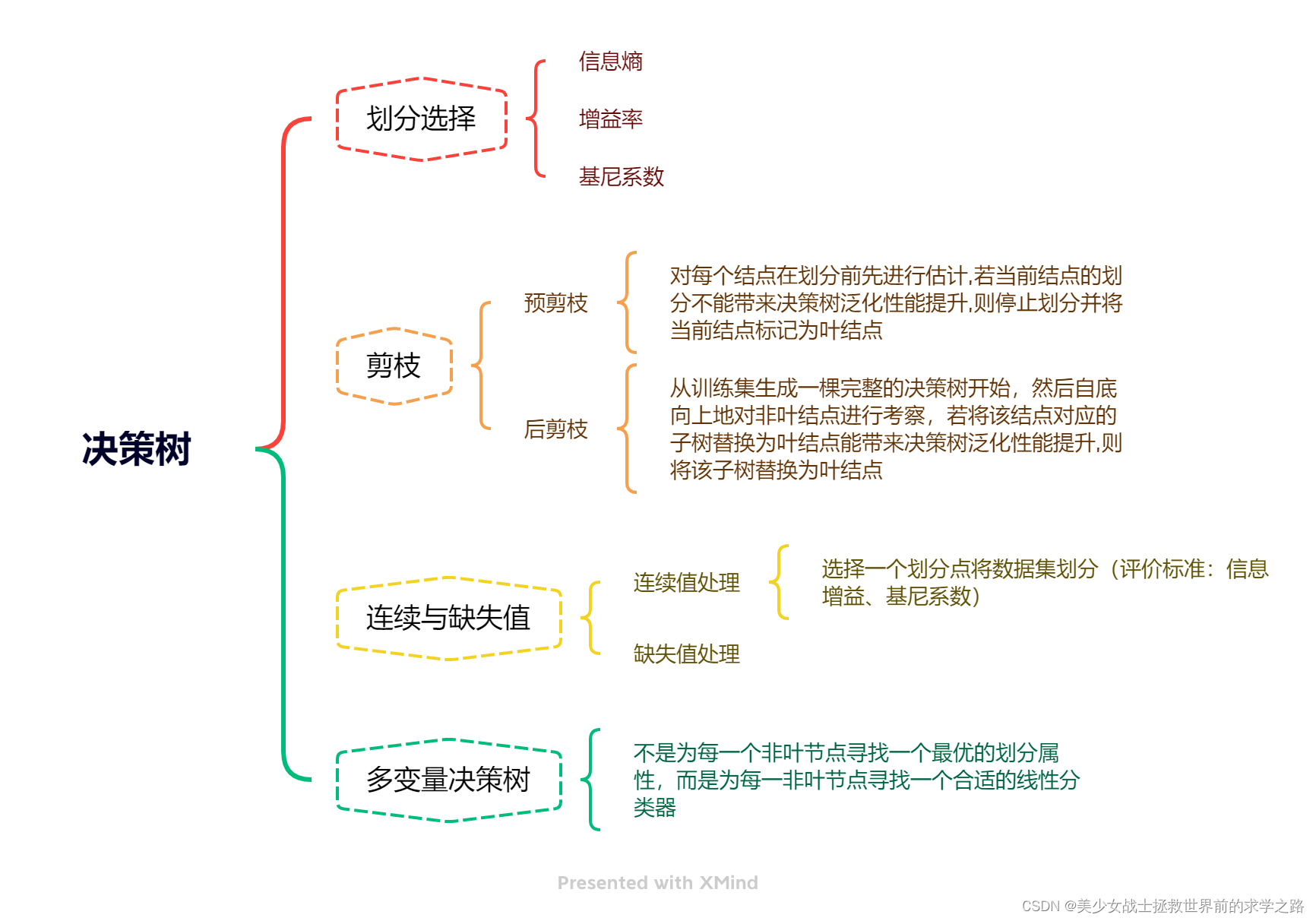
知识导图
实例练习
案例实战:员工离职预测模型搭建-决策树
1 模型搭建
1.数据读取与预处理
首先读取员工信息以及其交易离职表现,即是否离职记录,代码如下:
import pandas as pd
df = pd.read_excel('D:\机器学习\源代码汇总-2020-06-04\第5章 决策树模型\源代码汇总_Jupyter Notebook格式(推荐)\员工离职预测模型.xlsx')
df.head()
| 工资 | 满意度 | 考核得分 | 工程数量 | 月工时 | 工龄 | 离职 | |
|---|---|---|---|---|---|---|---|
| 0 | 低 | 3.8 | 0.53 | 2 | 157 | 3 | 1 |
| 1 | 中 | 8.0 | 0.86 | 5 | 262 | 6 | 1 |
| 2 | 中 | 1.1 | 0.88 | 7 | 272 | 4 | 1 |
| 3 | 低 | 7.2 | 0.87 | 5 | 223 | 5 | 1 |
| 4 | 低 | 3.7 | 0.52 | 2 | 159 | 3 | 1 |
对工资列进行数值化处理,代码如下:
df = df.replace({'工资': {'低': 0, '中': 1, '高': 2}})
df.head()
| 工资 | 满意度 | 考核得分 | 工程数量 | 月工时 | 工龄 | 离职 | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 3.8 | 0.53 | 2 | 157 | 3 | 1 |
| 1 | 1 | 8.0 | 0.86 | 5 | 262 | 6 | 1 |
| 2 | 1 | 1.1 | 0.88 | 7 | 272 | 4 | 1 |
| 3 | 0 | 7.2 | 0.87 | 5 | 223 | 5 | 1 |
| 4 | 0 | 3.7 | 0.52 | 2 | 159 | 3 | 1 |
2.提取特征变量和目标变量
X = df.drop(columns='离职')
y = df['离职']
3.划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)#参数X和y分别代表提取的特征变量和目标变量;test_size是测试集数据所占的比例
4.模型训练及搭建
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=3, random_state=123)#将决策树模型赋给变量model,同时设置树的最大深度参数max_depth为3
model.fit(X_train, y_train)#用fit()函数进行模型训练,传入的参数为训练集数据。
DecisionTreeClassifier(max_depth=3, random_state=123)
2 模型预测及评估
2.1直接预测是否离职
y_pred = model.predict(X_test)
# 通过构造DataFrame进行对比
a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
a.head()
# 如果要查看整体的预测准确度,可以采用如下代码:
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score)
# 或者用模型自带的score函数查看预测准确度
model.score(X_test, y_test)
0.9573333333333334
0.9573333333333334
2.2预测不离职&离职概率
其实分类决策树模型本质预测的并不是准确的0或1的分类,而是预测其属于某一分类的概率,可以通过如下代码查看预测属于各个分类的概率:
y_pred_proba = model.predict_proba(X_test)
b = pd.DataFrame(y_pred_proba, columns=['不离职概率', '离职概率'])
b.head()
| 不离职概率 | 离职概率 | |
|---|---|---|
| 0 | 0.985261 | 0.014739 |
| 1 | 0.985261 | 0.014739 |
| 2 | 0.286006 | 0.713994 |
| 3 | 0.985261 | 0.014739 |
| 4 | 0.922832 | 0.077168 |
如果想查看离职概率,即查看y_pred_proba的第二列,可以采用如下代码,这个是二维数组选取列的方法,其中逗号前的“:”表示所有行,逗号后面的数字1则表示第二列,如果把数字1改成数字0,则提取第一列不离职概率。
y_pred_proba[:,1]
array([0.01473923, 0.01473923, 0.71399387, ..., 0.01473923, 0.94594595,
0.01473923])
2.3模型预测效果评估
在Python实现上,通过4.3节讲过的代码就可以求出在不同阈值下的命中率(TPR)以及假警报率(FPR)的值,从而可以绘制ROC曲线。
from sklearn.metrics import roc_curve
fpr, tpr, thres = roc_curve(y_test, y_pred_proba[:,1])#传入测试集目标变量y_test及预测的离职概率,计算出不同阈值下的命中率和假警报率,并将三者分别赋给变量fpr(假警报率)、tpr(命中率)、thres(阈值)
#查看不同阈值下的假警报率和命中率
a = pd.DataFrame() # 创建一个空DataFrame
a['阈值'] = list(thres)
a['假警报率'] = list(fpr)
a['命中率'] = list(tpr)
a
| 阈值 | 假警报率 | 命中率 | |
|---|---|---|---|
| 0 | 2.000000 | 0.000000 | 0.000000 |
| 1 | 1.000000 | 0.000000 | 0.247110 |
| 2 | 0.945946 | 0.008232 | 0.677746 |
| 3 | 0.713994 | 0.038128 | 0.942197 |
| 4 | 0.077168 | 0.159879 | 0.969653 |
| 5 | 0.059406 | 0.171577 | 0.972543 |
| 6 | 0.045763 | 0.240035 | 0.976879 |
| 7 | 0.014739 | 1.000000 | 1.000000 |
已知了不同阈值下的假警报率和命中率,可通过matplotlib库可绘制ROC曲线,代码如下:
import matplotlib.pyplot as plt
plt.plot(fpr, tpr)
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YgvZyWbx-1672809538203)(output_24_0.png)]](https://img-blog.csdnimg.cn/8d88ee323b4847d59e2faee52089a9eb.png)
通过如下代码则可以快速求出模型的AUC值:
from sklearn.metrics import roc_auc_score
score = roc_auc_score(y_test, y_pred_proba[:,1])
print(score)
0.9736722483245008
2.4特征重要性评估
在决策树模型中,一个特征变量对模型整体的基尼系数下降的贡献越大,它的特征重要性就越大
# 通过DataFrame进行展示,并根据重要性进行倒序排列
features = X.columns # 获取特征名称
importances = model.feature_importances_ # 决策树模型中各特征变量的特征重要性
# 通过二维表格形式显示
importances_df = pd.DataFrame()
importances_df['特征名称'] = features
importances_df['特征重要性'] = importances
importances_df.sort_values('特征重要性', ascending=False)
| 特征名称 | 特征重要性 | |
|---|---|---|
| 1 | 满意度 | 0.598109 |
| 5 | 工龄 | 0.150866 |
| 2 | 考核得分 | 0.140074 |
| 3 | 工程数量 | 0.106387 |
| 4 | 月工时 | 0.004565 |
| 0 | 工资 | 0.000000 |














 2393
2393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









