







深度学习基础_过拟合
蓝色线是训练数据的损失函数,橙色线是测试数据的损失函数
如下图测试数据集上loss没有随着训练而下降反而上升了,这是因为产生了过拟合
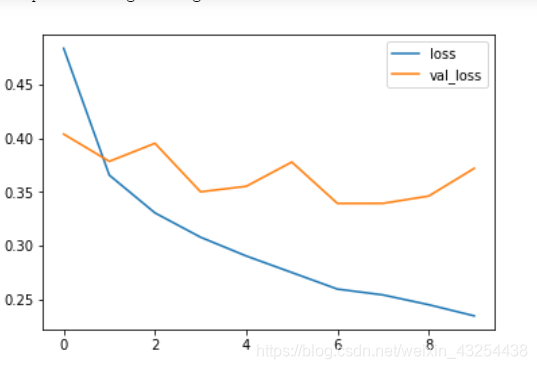
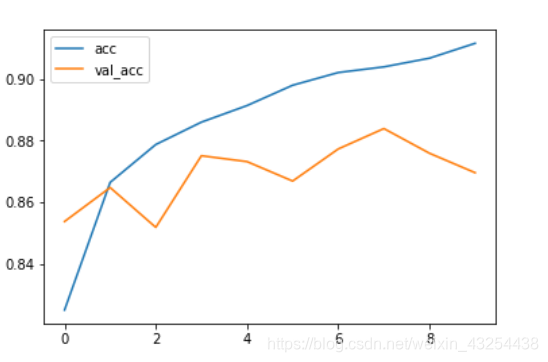
解决方法
过拟合:在训练数据上得分很高,在测试数据上得分相对较低
欠拟合:在训练数据上得分较低,在测试数据上得分相对较低
解决欠拟合的办法,增加隐藏单元个数,增加网络层深度
解决过拟合的办法,通过dropout层解决过拟合问题
dropout层:在神经网络中人为地随机丢弃一些层
为什么说Dropout可以解决过拟合?
(1)取平均的作用:先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用“5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一 个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况。
(3) Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝
参数选择原则
理想的模型是刚好在欠拟合和过拟合的界线上,也就是正好拟合数据。
首先开发一个过拟合的模型:
(1)添加更多的层。
(2)让每一层变得更大。
(3)训练更多的轮次
然后,抑制过拟合:
(1) dropout
(2)正则化
(3)图像增强
抑制过拟合地最好办法是增加训练数据,训练数据不变地情况下才用上面的办法
再次,调节超参数:
学习速率,
隐藏层单元数
训练轮次
超参数的选择是一 个经验与不断测试的结果。
经典机器学习的方法,如特征工程、增加训练数据也要做
交叉验证(调参的时候很可能将信息泄露给测试数据,所以最好将数据分为三部分进行交叉验证)
构建网络的总原则
总的原则是:保证神经网络容量足够拟合数据
一、增大网络容量,直到过拟合
二、采取措施抑制过拟合I
三、继续增大网络容量,直到过拟合














 1658
1658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









