






蓄锐行:我深耕于低空经济领域,同时对IOT技术有着深入的理解,而在AI的探索性研究上,我也已迈出坚实的步伐,虽起步不久,却满怀热情与憧憬。平日里,我热衷于撰写关于低空经济的文章,分享我的见解与思考。对于AI领域,我亦蓄势待发,计划逐步推出相关文章,与众人共探智能之奥秘。
近期,我身处深圳这座创新之城,正积极寻觅低空经济相关的职业机遇,渴望在这片热土上大展拳脚,施展我的才华与抱负。然而,至今仍未遇那识马的“伯乐”,但我并未因此气馁。我将继续坚持撰写博客,用文字记录我的探索与成长,直到那一天,那位能赏识我、与我并肩同行的“伯乐”出现。
DeepSeek-R1 7B、32B、671B差距有多大?先说结论,相比“满血版”671B的DeepSeek-R1,蒸馏版差不多就是“牛肉风味肉卷”和“牛肉卷”的差距…
最近Deepseek成为了AI圈中最火爆的话题,一方面通过稀疏激活的MoE架构、MLA注意力机制优化及混合专家分配策略等创新手段,实现了高效的训练和推理能力,同时大幅降低了API调用成本,达到了行业领先水平。另一方面,Deepseek更是以7天实现用户数破亿的速度,一举超越了OpenAI的ChatGPT(ChatGPT为2个月)
网上关于本地部署Deepseek-R1的教程,更是如同雨后春笋般出现在各个网络平台上。然而,这些本地部署教程往往会告诉你Deepseek-R1有多强大,但不会告诉你本地部署的“蒸馏版”Deepseek-R1相比“满血版”究竟有多差。
值得注意的是,目前公开发布的小尺寸的DeepSeek-R1模型,均是通过Qwen或Llama从R1中蒸馏过来,尺寸有所缩小,以适应不同性能设备调用DeepSeek-R1模型。
换句话说,无论是7B还是32B的DeepSeek-R1,本质上更像是“R1味儿”的Qwen模型,差不多是“牛肉风味肉卷”和“牛肉卷”的差距。虽然拥有前者部分特性,但更多是后者照猫画虎实现类似的推理功能。
毋庸置疑的是,随着模型尺寸的缩小,其性能也会变得更差,与“满血版”R1的差距也会更大。而今天,大模型之家就带你来看看,不同尺寸的DeepSeek-R1与“满血版”差距究竟有多大?
一、语言能力测试
在语言能力测试环节,大模型之家让7B、32B、671B的DeepSeek-R1,分别用“新年快乐万事如意”写一首藏头诗。
在这个似乎已经被各大模型“玩烂了”的场景下,在很多人看来是LLM最小儿科的场景。
然而正如那句“如果不出意外的话,就要出意外了”。在这一环节中,7B版本的R1竟然率先出现了bug!
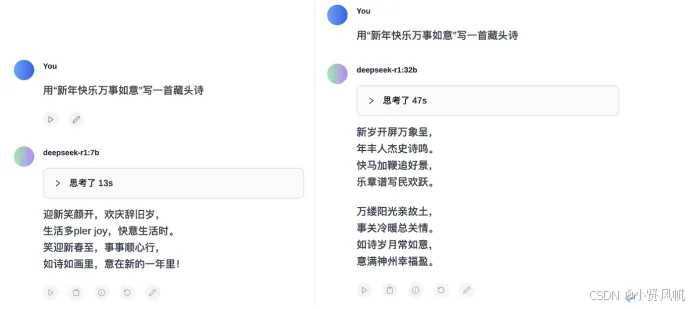
可以看到,左边的7B版本R1的输出结果既没能“藏头”,也不像一首“诗”,甚至还在文中开始说起了英语。显然,在最基础的文字生成能力上,7B并没有达到“及格线”。
相比之下,32B的R1可以正常输出文本内容,成功完成了“藏头诗”的创作。虽然从押韵方面存在些许瑕疵,但胜在七言律诗对仗工整,内容上也没有逻辑错误。

当然,效果最好的还要数“满血版”的R1,不仅对仗工整,韵脚得体,同时还给出了诗词的赏析内容。明确了“新年快乐万事如意”的“藏头诗”背后,寄寓了对新岁万事顺遂的美好祝愿。

为了探究是否是因为小尺寸导致语言能力下降,大模型之家还采用了尺寸相近的9B的GLM4用同样的提示词进行测试。结果发现在语言表达能力方面,GLM4并不输给DeepSeek-R1,可见,当R1规模小到一定程度时,其基本的文本能力方面也会受到严重影响。
二、联网总结测试
在测试完语言能力之后,我们在将R1与网络搜索相结合,测试一下不同尺寸下,对于网络内容的汇总能力。
以一首杜甫的《登高》来测试一下R1大模型在联网状态下的表现。
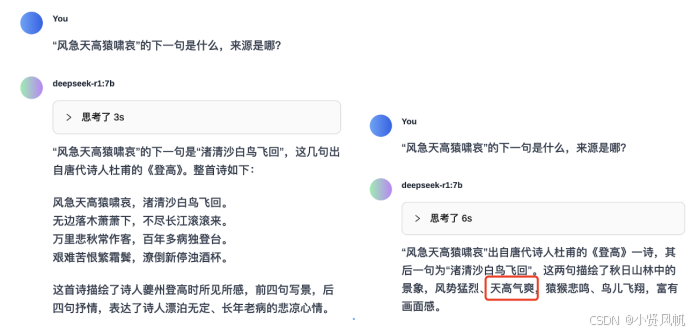
乍一看7B模型输出的表现足够优秀(左),但是实际测试中,大模型之家发现7B模型的输出结果并不稳定。偶尔会出现右边对于诗词理解出现偏差的场景,由此也能够看出,在同等的网络搜索情况下,R1模型因为尺寸缩小,在语言理解与生成能力方面受到了较大的影响。
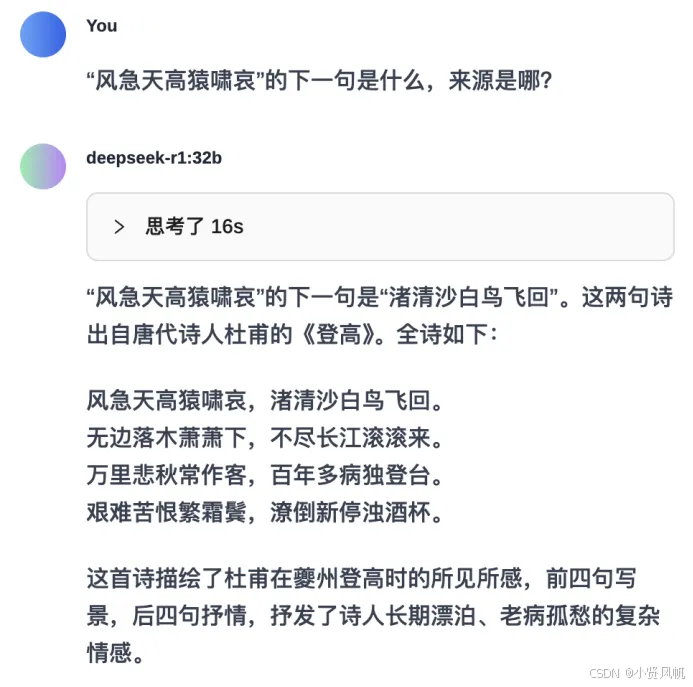
相比之下,32B的R1输出就相对稳定,虽然在输出结果上会存在显示“整首诗”和“一句诗”的左右横跳,但对于诗词内容理解的准确性有了较大提高。

而“满血版”R1依旧是表现最为优秀,不仅能够完整展示诗句内容,同时还会在答案中增加一些点评与背景陈述,增加回答的知识性与专业性。
另一组测试,选用目前游戏中某角色的配队,来测试7B与32B的语言理解能力。
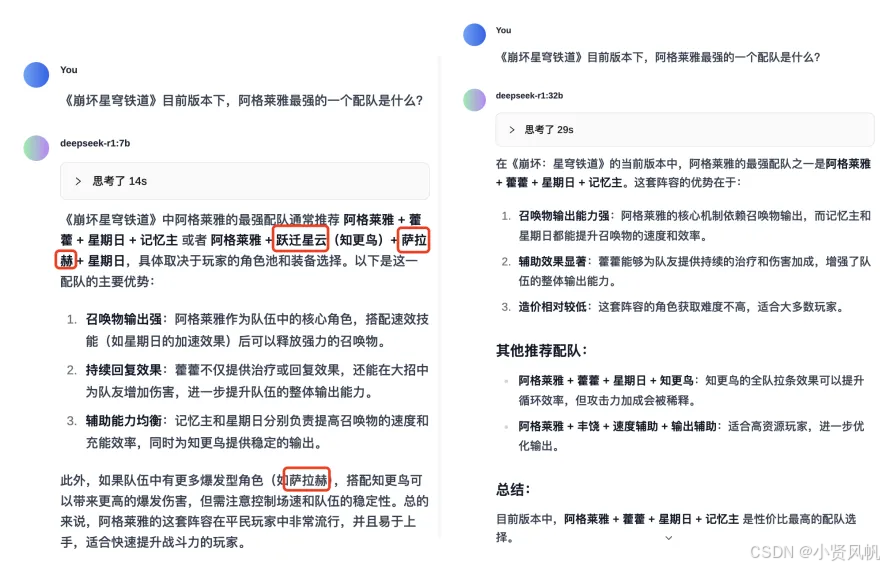
在这一组测试中,7B模型出现了游戏中不存在的角色,而32B则能够准确把握角色名称,同时,在配队的推荐理由方面,32B模型给出的内容也更加科学合理。
三、逻辑推理测试
而在测试的第二个环节,我们用一道经典的“鸡兔同笼”问题来考考不同尺寸的R1模型。提示词为:一个笼子,里头有鸡和兔子,一共有25个头和76只脚,请问笼子里边鸡和兔子各有多少只?

也许是“鸡兔同笼”的问题对于R1而言过于简单,那么换一道更难的“一个三棱柱的上底和下底为两个等腰直角三角形,每个等腰三角形的直角边长为16。直棱柱的高度等于等腰直角三角形的斜边长度。求直棱柱的表面积。”

比较令人惊讶的是,无论是7B还是32B的模型,都可以输出正确的答案。可见,在数学运算能力方面,蒸馏尽可能保留了R1模型的数学能力。
四、代码能力测试
最后,让我们再来对比一下7B与32B的代码能力。这个环节,大模型之家要求R1编写一个“可以在浏览器上打开的贪吃蛇游戏”。
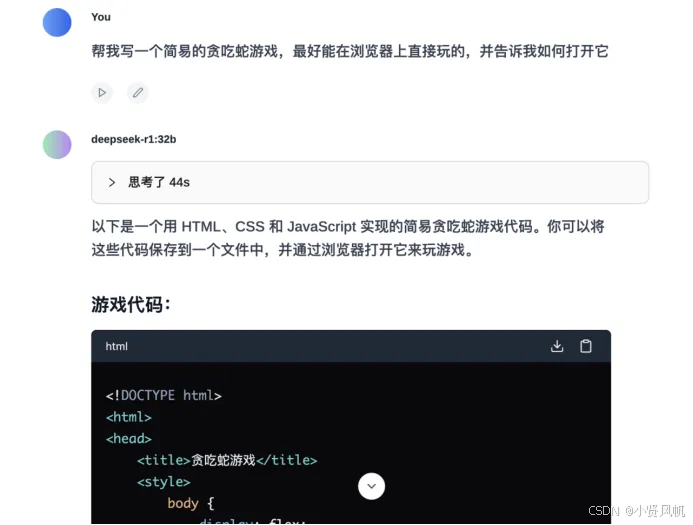
代码太长,让我们直接来看生成好的结果:

Deepseek-R1 7B的生成的游戏程序存在bug,只是一张静态的图片,蛇无法移动。

而Deepseek-R1 32B的生成的游戏程序可以正常运行,可以通过键盘方向键控制蛇的正常移动,同时面板可以正常计分。
五、本地部署门槛高,普通用户慎尝试
从一系列的测试看来,DeepSeek-R1的7B、32B,都与“满血版”671B存在比较明显的差距,因此本地部署更多是用来搭建私有数据库,或让有能力的开发者进行微调与部署使用。对于一般用户而言,无论从技术还是设备门槛都比较高。
官方测试结论也显示,32B的DeepSeek-R1大约能够实现90%的671B的性能,且在AIME 2024、GPQA Daimond、MATH-500等部分场景之下效果略优于OpenAI的o1-mini。
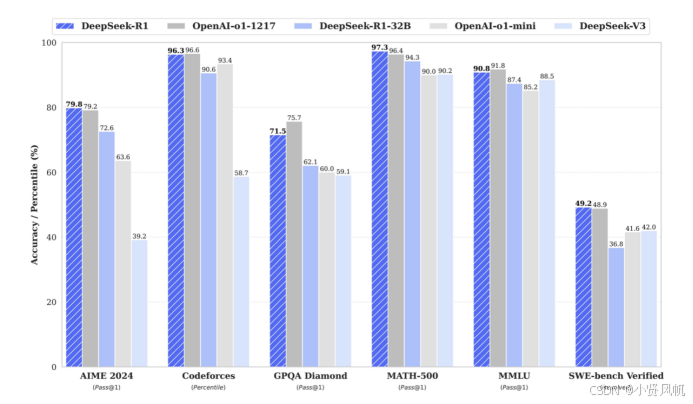
而在实际体验中,也能够看到与官方测试结论基本吻合,32B以上模型勉强尚有本地化部署的可用性,而再小尺寸的模型在基础能力方面有些过于薄弱,甚至输出结果不敌同尺寸其他模型。尤其是网络上大量的本地部署教程所推荐的1.5B、7B、8B尺寸模型,还是忘了它们吧……除了配置需求低、速度快,用起来并不理想。
所以,从结论上来说,如果你真想本地部署一个DeepSeek-R1模型,那么大模型之家建议从32B起步开始搭建,才有相对完整的大模型体验。
那么,部署32B模型的代价是什么呢?
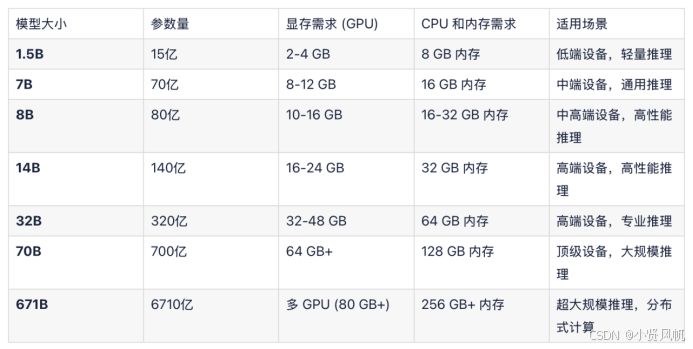
运行32B的R1模型,官方建议是64GB内存和32-48GB显存,再配合对应的CPU,一台电脑主机的价格大约在20000元以上。如果以最低配置运行,(20GB内存+24GB显存),价格也要超过万元。(除非你买API)
对于大多数普通用户而言,你费劲心力搭建的本地大模型,可能真的未必有市面上主流的免费大模型产品来得简单、方便、效果好,更多只是让你过一把部署本地大模型的瘾。

DeepSeek系列模型的成功不仅改变了中美之间的技术竞争格局,更对全球范围内的科技创新生态产生了深远影响。据统计,已经有超过50个国家与DeepSeek达成了不同程度的合作协议,在技术应用和场景开发方面展开深度合作。
从DeepSeek引发的全球关注可以看出,人工智能已经成为重塑国际格局的重要力量。面对这场前所未有的科技变革,如何将技术创新优势转化为持续的竞争能力,同时构建开放包容的合作网络,将是未来面临的关键挑战。对于中国而言,这不仅是一场技术实力的较量,更是一场科技创新话语权的争夺。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











