






题目:Accurate and Energy-Efficient Bit-Slicingfor RRAM-Based Neural Networks
期刊:IEEE TRANSACTIONS ON EMERGING TOPICS IN COMPUTATIONAL INTELLIGENCE, VOL. 7, NO. 1, FEBRUARY 2023
摘要
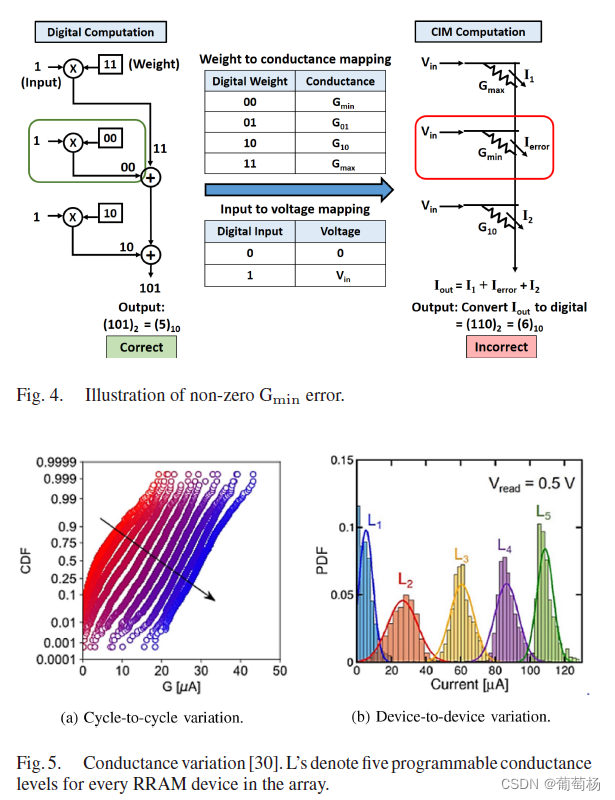
基于RRAM的存内计算架构利用多个RRAM器件表示1个多bit数。RRAM中的 G m i n G_{min} Gmin(HRS, high resistance state = 1 G m i n \frac{1}{G_{min}} Gmin1)过高(HRS较低)造成精度损失。本文提出一个非平衡的bit-slice机制来减轻 G m i n G_{min} Gmin的影响。通过基于二值的位置分配不同的感知余量来实现。感知余量的分配通过2的补码来实现,进一步降低非0 G m i n G_{min} Gmin的错误。
引言
ISAAC和PUMA采用平衡的bit-slicing(BBS,balanced bit slicing)机制,但由于 G m i n G_{min} Gmin的存在使得读出精度损失严重。
A. Ankit et al., “PUMA: A. programmable ultra-efficient memristorbased accelerator for machine learning inference,” in Proc. Twenty-Fourth Int. Conf. Architectural Support Program. Lang. Operating Syst., 2019, pp. 715–731.
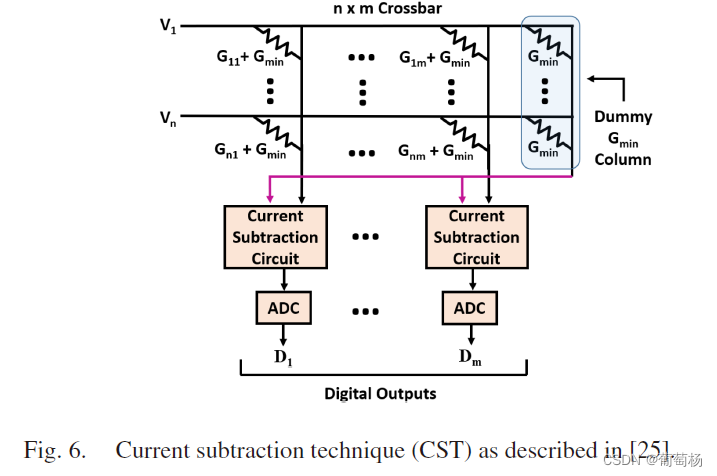
PANTHER 提出了异构的bit sliceing机制(HBS,heterogeneous bit slicing)。作为BBS机制的延伸,可显著降低 G m i n G_{min} Gmin带来的影响。电流减法技术CST(Current substraction technology)可降低Gmin的影响,但当Gmin的偏差较大时并非特别有效。
本文提出非均衡的bit-slice机制UBS(Unbalanced bit slicing)用于存内计算架构。在UBS中合理的感知余量被分配到不同的slice中,通过调整bit-size来降低Gmin的影响。本文此前的工作更高位的bit获得更大的感知余量,但消耗更高的外围电路代价。在本文中,UBS给slice分配足够的感知精度来提升能效。此外,本文提供了算法级别的高能效slice size的选择,利用了精度与能效之间的折中。在不同的数据集与神经网络上证明了其有效性。贡献如下:
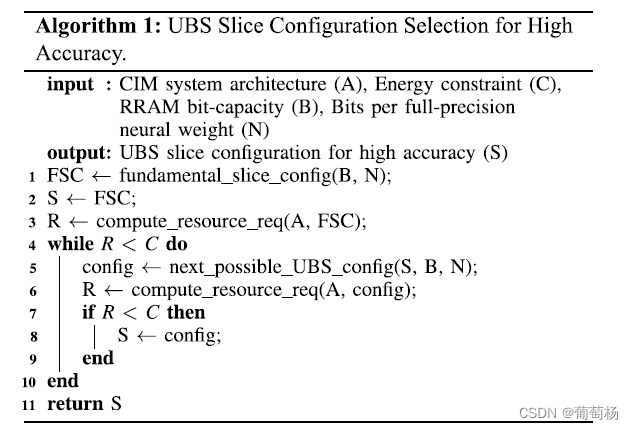
- UBS。更重要的slice有更高的感知余量。提出一种算法,在给定资源开销的情况下找到slice的大小实现最优的精度
- 设计了精度一定时降低资源开销的方法。通过限制slices的感知余量发展了tailor UBS机制的方法。
- 在电导偏差存在的情况下展示了一种整体的解决方案,包含UBS和2的补码算术计算,减轻的Gmin的影响。
- 验证了有效性。
电导偏差
RRAM中的电导偏差,时间上称为cycle-to-cycle的偏差,空间上称为device-to-device的偏差。
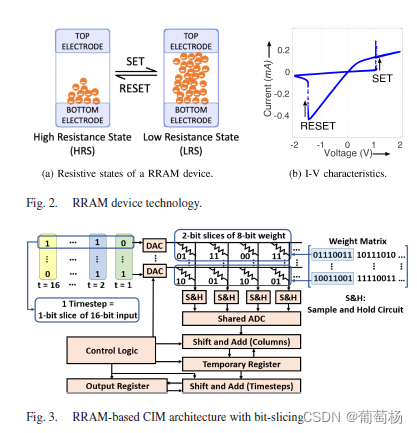
Bit-Slice架构的挑战
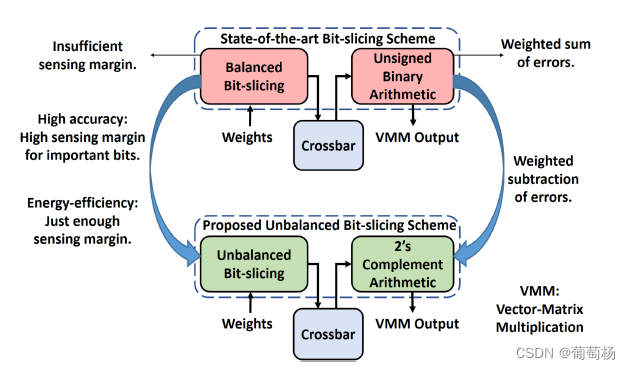
所提出的非平衡Bit-Slicing
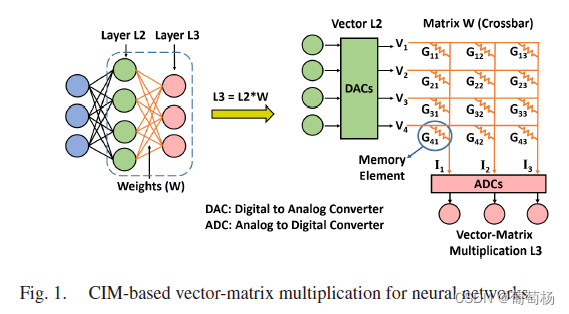
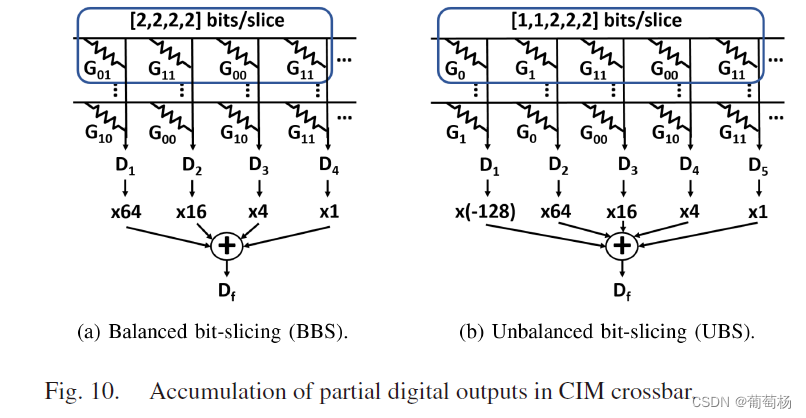
bit slicing机制包含bit-slicing逻辑和相应的交叉阵列算术计算单元。bit-slicing逻辑决定一个全精度的神经网络权重如何被分为更小的slice,交叉阵列算术逻辑将从交叉阵列中获取的部分和组合成最终的全精度输出。我们将全精度的神经网络权重分为等尺寸的slice和不等尺寸的slice。感知余量的分配策略基于是否可实现高精度和高能效来进行适应性分配。
Dacc表示全精度的输出,Di和Si分别表示按列输出的部分和与缩放因子。
D a c c = : ∑ i = 1 n S i D i ( 1 a ) D_{acc}= :\sum_{i=1}^{n}S_iD_i \ (1a) Dacc=:∑i=1nSiDi (1a)
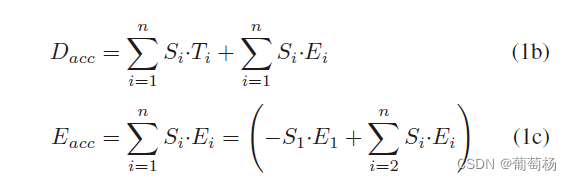
Ti表示理想的列输出(Gmin=0),Ei是由于Gmin导致的错误。
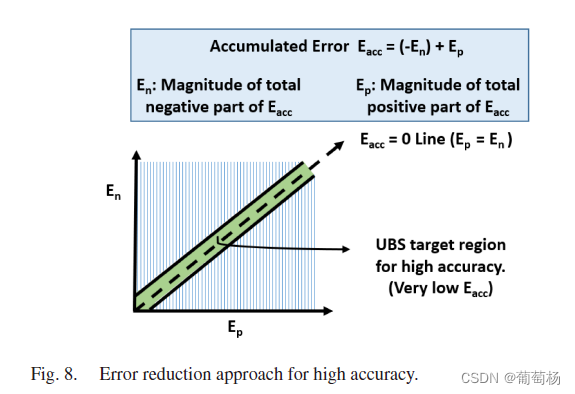
针对高精度的非平衡Bit-Slicing机制
- Bit-Slicing逻辑:
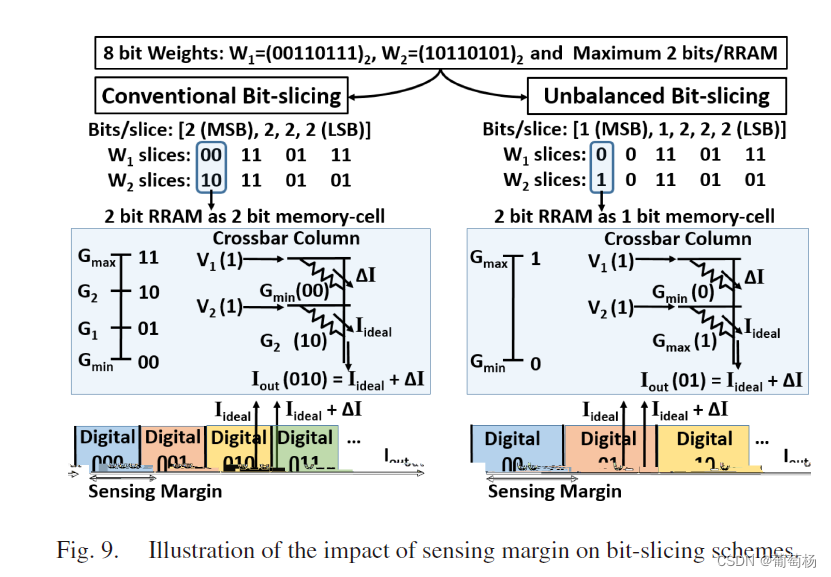
看到这里发现是根据精度选择权重的单值映射还是双值映射。
no ending















 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









