







 本文介绍如何在BERT模型中添加特殊标记(special tokens),包括在tokenizer中加入这些标记以避免分词,并调整模型的词嵌入矩阵大小以适配新增加的标记。
本文介绍如何在BERT模型中添加特殊标记(special tokens),包括在tokenizer中加入这些标记以避免分词,并调整模型的词嵌入矩阵大小以适配新增加的标记。
有时候想要在bert里面加入一些special token, 以huggingFace transformer为例,需要做两个操作:
- 在tokenizer里面加入special token, 防止tokenizer将special token分词。
- resize embedding, 需要为special token初始化新的word embedding。
可以使用下面代码:
special_tokens_dict = {'additional_special_tokens': ['[C1]','[C2]','[C3]','[C4]']}
num_added_toks = tokenizer.add_special_tokens(special_tokens_dict)
model.resize_token_embeddings(len(tokenizer))
tokenizer.add_special_tokens可以让tokenizer不给’[C1]’,’[C2]’,’[C3]’,’[C4]'进行分词 (这个tokenizer就可以用于后续的数据预处理使用)
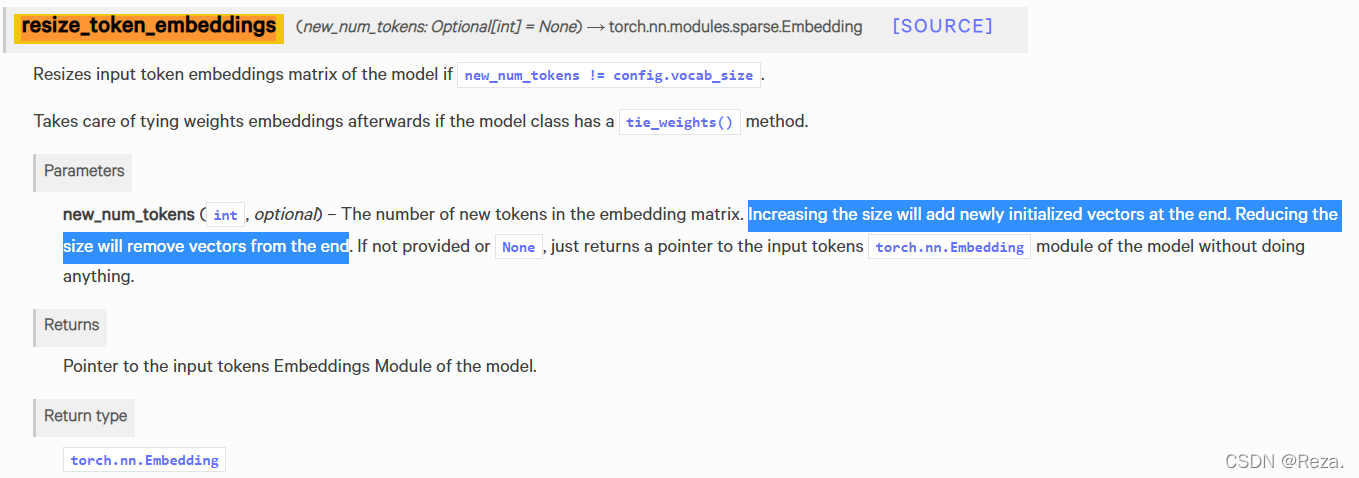
而resize_token_embeddings可以将bert的word embedding进行形状变换。new_num_tokens大于原先的max word的话,会在末尾pad新随机初始化的vector ; 小于原先的max word的话,会把末尾的word embedding vector删掉。不传参数的话,什么也不变,只是return原先的embedding回来。而且这个操作只是pad 新的token或cut已有的token,其他位置token的预训练词向量不会被重新初始化。
额外要提醒的是,加入specail token的话要注意fine-yune的训练量是不是足以训练这些新加入的specail token的embedding (尤其是做few-shot的)。如果训练的数据量不够,能够用已有的special token就别用新加入的([SEP],etc.)

















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









