







很多时候,我们需要把模型copy一份,两份模型用于不同的用途(e.g., 分别训练、teacher / student model)。虽然torch并没有提供类似于model.clone()这种接口,但是这个功能可以简单通过copy.deepcopy()实现。如下图所示:
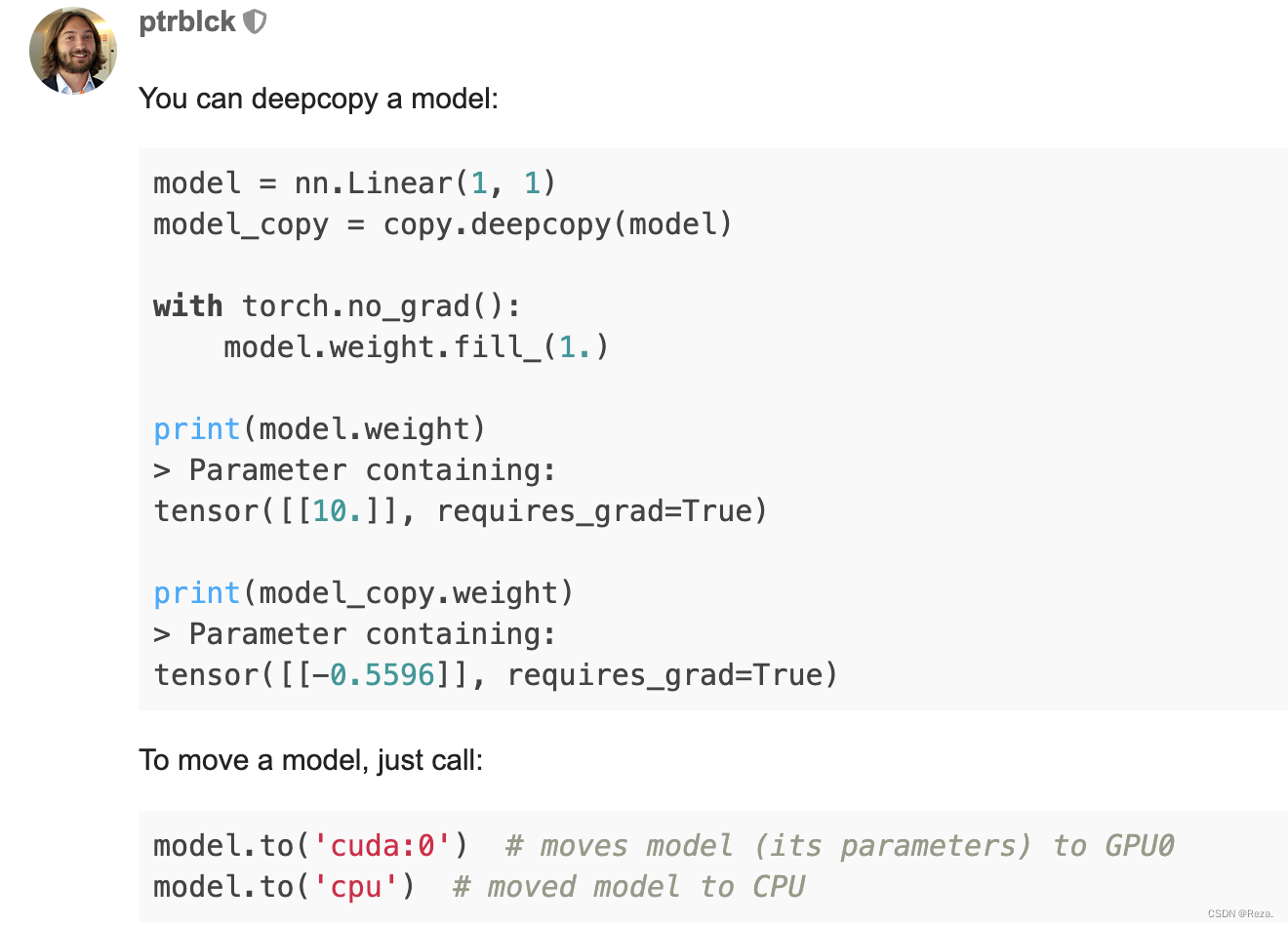
copy.deepcopy()不仅可以把原先的模型的所有参数,原模原样复制一份,连device也照样能够复制。并且各自优化,互不干扰。
验证如下:
>>> import torch
>>> import copy
>>> m=torch.nn.Linear(3,3).to("cuda:4")
>>> mc=copy.deepcopy(m) ## deepcopy original model parameters
>>> t1=torch.randn(3,3) # for model 'm'
>>> t1=t1.to("cuda:4")
>>> t1
tensor([[-0.6198, 0.2503, 0.9287],
[ 0.6553, -0.6422, -2.0498],
[-0.7867, -0.6862, 1.9102]], device='cuda:4')
>>> t2=torch.randn(3,3) # for model 'mc'
>>> t2=t2.to("cuda:4")
>>> t2
tensor([[ 0.9616, 1.1679, -0.3201],
[ 0.6383, -0.4115, -1.5540],
[ 0.6649, 0.8439, -1.3090]], device='cuda:4')
>>> out1=m(t1)
>>> loss1=torch.sum(out1)
# we can find that the loss1 can backpropogate to m
>>> torch.autograd.grad(loss1,list(m.parameters())[0],retain_graph=True)
(tensor([[-0.7512, -1.0782, 0.7891],
[-0.7512, -1.0782, 0.7891],
[-0.7512, -1.0782, 0.7891]], device='cuda:4'),)
# but it can not bw backpropogated to mc
>>> torch.autograd.grad(loss1,list(mc.parameters())[0],retain_graph=True)
Traceback (most recent call last):
RuntimeError: One of the differentiated Tensors appears to not have been used in the graph. Set allow_unused=True if this is the desired behavior.
# the following results are similar to the conclusions above
>>> out2=mc(t2)
>>> loss2=torch.sum(out2)
>>> torch.autograd.grad(loss2,list(m.parameters())[0],retain_graph=True)
Traceback (most recent call last):
RuntimeError: One of the differentiated Tensors appears to not have been used in the graph. Set allow_unused=True if this is the desired behavior.
>>> torch.autograd.grad(loss2,list(mc.parameters())[0],retain_graph=True)
(tensor([[ 2.2648, 1.6003, -3.1831],
[ 2.2648, 1.6003, -3.1831],
[ 2.2648, 1.6003, -3.1831]], device='cuda:4'),)

















 1478
1478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









