







Adaptive Mobile Manipulation for Articulated Objects In the Open World
在开放世界中的自适应关节对象移动操作
文章目录

Fig. 1: Open-World Mobile Manipulation System: We use a full-stack approach to operate articulated objects such as real-world doors, cabinets, drawers, and refrigerators in open-ended unstructured environments.
图1:开放世界移动操作系统:我们采用全栈方法来操作关节物体,如真实门、橱柜、抽屉和冰箱等真实物体,这些物体位于开放式非结构化环境中。
Abstract— Deploying robots in open-ended unstructured environments such as homes has been a long-standing research problem. However, robots are often studied only in closed-off lab settings, and prior mobile manipulation work is restricted to pick-move-place, which is arguably just the tip of the iceberg in this area. In this paper, we introduce Open-World Mobile Manipulation System, a full-stack approach to tackle realistic articulated object operation, e.g. real-world doors, cabinets, drawers, and refrigerators in open-ended unstructured environments. The robot utilizes an adaptive learning framework to initially learns from a small set of data through behavior cloning, followed by learning from online practice on novel objects that fall outside the training distribution. We also develop a low-cost mobile manipulation hardware platform capable of safe and autonomous online adaptation in unstructured environments with a cost of around 20,000 USD. In our experiments we utilize 20 articulate objects across 4 buildings in the CMU campus. With less than an hour of online learning for each object, the system is able to increase success rate from 50% of BC pre-training to 95% using online adaptation. Video results at https://open-world-mobilemanip.github.io/.
摘要—在家庭等开放式非结构化环境中部署机器人一直是一个长期存在的研究问题。然而,机器人通常只在封闭的实验室环境中进行研究,以及先前的移动操作工作仅限于拾取-移动-放置,这在该领域可能只是冰山一角。在本文中,我们介绍了开放式移动操作系统,这是一个全栈方法,旨在处理在开放式非结构化环境中操作真实关节对象,如实际门、橱柜、抽屉和冰箱。机器人采用自适应学习框架,通过行为克隆从少量数据中进行初始学习,然后通过在线实践学习新对象,这些对象超出了训练分布。我们还开发了一个低成本的移动操作硬件平台,能够在成本约为20,000美元的非结构化环境中进行安全和自主的在线适应。在我们的实验中,我们使用了CMU校园内的4栋建筑中的20个关节对象。对于每个对象的不到一个小时的在线学习,系统能够将成功率从BC预训练的50%提高到95%。视频结果请参见https://open-world-mobilemanip.github.io/。
I. INTRODUCTION
I. 引言
Deploying robotic systems in unstructured environments such as homes has been a long-standing research problem. In recent years, significant progress has been made in deploying learning-based approaches [1]–[4] towards this goal. However, this progress has been largely made independently either in mobility or in manipulation, while a wide range of practical robotic tasks require dealing with both aspects [5]– [8]. The joint study of mobile manipulation paves the way for generalist robots which can perform useful tasks in open-ended unstructured environments, as opposed to being restricted to controlled laboratory settings focused primarily on tabletop manipulation.
在非结构化环境,如家庭中部署机器人系统一直是一个长期存在的研究问题。近年来,在实现这一目标方面,通过采用基于学习的方法 [1]–[4] 已经取得了显著进展。然而,这一进展在机动性和操作性之间主要是独立进行的,而许多实际的机器人任务需要同时处理这两个方面 [5]–[8]。对移动操作的联合研究为通用型机器人铺平了道路,这种机器人可以在开放式非结构化环境中执行有用的任务,而不仅仅局限于主要集中在桌面操作的受控实验室环境。
However, developing and deploying such robot systems in the open-world with the capability of handling unseen objects is challenging for a variety of reasons, ranging from the lack of capable mobile manipulator hardware systems to the difficulty of operating in diverse scenarios. Consequently, most of the recent mobile manipulation results end up being limited to pick-move-place tasks [9]–[11], which is arguably representative of only a small fraction of problems in this space. Since learning for general-purpose mobile manipulation is challenging, we focus on a restricted class of problems, involving the operation of articulated objects, such as doors, drawers, refrigerators, or cabinets in open-world environments. This is a common and essential task encountered in everyday life, and is a long-standing problem in the community [12]–[18]. The primary challenge is generalizing effectively across the diverse variety of such objects in unstructured real-world environments rather than manipulating a single object in a constrained lab setup. Furthermore, we also need capable hardware, as opening a door not only requires a powerful and dexterous manipulator, but the base has to be stable enough to balance while the door is being opened and agile enough to walk through.
然而,在开放世界中开发和部署具有处理未见过对象能力的机器人系统,出于各种原因具有挑战性,从缺乏能力强大的移动操作硬件系统到在各种情境中操作的困难。因此,大多数最近的移动操作结果最终局限于拾取-移动-放置任务 [9]–[11],这可以说只代表了该领域问题的一小部分。由于通用移动操作的学习具有挑战性,我们专注于一类受限问题,涉及在开放式世界环境中操作关节对象,如门、抽屉、冰箱或橱柜。这是生活中常见且重要的任务,在社区中已经是一个长期存在的问题 [12]–[18]。主要挑战在于在非结构化的现实环境中有效地推广各种此类对象,而不是在受限的实验室设置中操作单个对象。此外,我们还需要有能力的硬件,因为打开一扇门不仅需要强大且灵巧的操作器,而且底座必须足够稳定以在打开门时保持平衡,并且足够灵活以通过。
We take a full-stack approach to address the above challenges. In order to effectively manipulate objects in open-world settings, we adopt a adaptive learning approach, where the robot keeps learning from online samples collected during interaction. Hence even if the robot encounters a new door with a different mode of articulation, or with different physical parameters like weight or friction, it can keep adapting by learning from its interactions. For such a system to be effective, it is critical to be able to learn efficiently, since it is expensive to collect real world samples. The mobile manipulator we use as shown in Figure. 3 has a very large number of degrees of freedom, corresponding to the base as well as the arm. A conventional approach for the action space of the robot could be regular end-effector control for the arm and SE2 control for the base to move in the plane. While this is very expressive and can cover many potential behaviors for the robot to perform, we will need to collect a very large amount of data to learn control policies in this space. Given that our focus is on operating articulated objects, can we structure the action space so that we can get away with needing fewer samples for learning?
我们采用了全栈方法来解决上述挑战。为了在开放世界环境中有效操纵物体,我们采用自适应学习方法,机器人通过与环境的互动不断学习在线样本。因此,即使机器人遇到具有不同关节运动方式或不同物理参数(如重量或摩擦)的新门,它可以通过从互动中学习来不断适应。对于这样的系统要有效,能够高效学习至关重要,因为收集真实世界样本是昂贵的。我们所使用的移动操作器如图3所示,具有非常多的自由度,对应于底座和机械臂。机器人的行动空间的传统方法可能是对机械臂采用常规的末端执行器控制,对底座采用SE2控制以在平面中移动。虽然这非常灵活,可以涵盖机器人执行许多潜在行为的可能性,但我们需要收集大量数据来学习在这个空间中的控制策略。鉴于我们的重点是操作关节对象,我们是否可以结构化行动空间,以便在学习过程中需要更少的样本?

Fig. 3: Mobile Manipulation Hardware Platform: Different components in the mobile manipulator hardware system. Our design is low-cost and easy-to-build with off-the-shelf components
图3:移动操作硬件平台:移动操作器硬件系统中的不同组件。我们的设计成本低,使用现成的组件易于构建。
Consider the manner in which people typically approach operating articulated objects such as doors. This generally first involves reaching towards a part of the object (such as a handle) and establishing a grasp. We then execute constrained manipulation like rotating, unlatching, or unhooking, where we apply arm or body movement to manipulate the object. In addition to this high-level strategy, there are also lower-level decisions made at each step regarding exact direction of movement, extent of perturbation and amount of force applied. Inspired by this, we use a hierarchical action space for our controller, where the high-level action sequence follows the grasp, constrained manipulation strategy. These primitives are parameterized by learned low-level continuous values, which needs to be adapted to operate diverse articulated objects. To further bias the exploration of the system towards reasonable actions and avoid unsafe actions during online sampling, we collect a dataset of expert demonstrations on 12 training objects, including doors, drawers and cabinets to train an initial policy via behavior cloning. While this is not very performant on new unseen doors (getting around 50% accuracy), starting from this policy allows subsequent learning to be faster and safer.
考虑人们通常如何操作关节对象,例如门。通常首先涉及到伸手触摸对象的某个部分(如把手)并建立抓握。然后我们执行受限制的操纵,如旋转、解锁或解挂,我们应用机械臂或身体运动来操纵对象。除了这个高级策略,每个步骤还涉及对运动方向、扰动程度和施加力量的确切决策。受此启发,我们为我们的控制器使用分层行动空间,其中高级行动序列遵循抓握、受限操纵策略。这些基本动作由学习的低级连续值参数化,需要适应操作各种关节对象。为了在在线采样过程中进一步偏向系统探索合理的动作并避免不安全的动作,我们收集了12个训练对象的专家演示数据集,包括门、抽屉和橱柜,以通过行为克隆训练初始策略。尽管这在新的未见过的门上表现不是很好(准确率约为50%),但从这个策略开始可以使后续学习更快、更安全。
Learning via repeated online interaction also requires capable hardware. As shown in Figure 3, we provide a simple and intuitive solution to build a mobile manipulation hardware platform, followed by two main principles: (1) Versatility and agility - this is essential to effectively operate diverse objects with different physical properties in potentially challenging environments, for instance a cluttered office. (2) Affordabiluty and Rapid-prototyping - Assembled with off the shelf components, the system is accessible and can be readily be used by most research labs.
通过反复的在线互动学习也需要有能力的硬件。如图3所示,我们提供了一个简单而直观的解决方案来构建一个移动操作硬件平台,遵循两个主要原则:
(1)多功能和灵活性 - 这对于在潜在具有挑战性的环境中,有效操纵具有不同物理属性的各种对象是至关重要的,例如杂乱的办公室。
(2)经济性和快速原型设计 - 由现成的组件组装而成,该系统是可访问的,并且大多数研究实验室可以方便地使用。
In this paper, we present Open-World Mobile Manipulation System, a full stack approach to tackle the problem of mobile manipulation of realistic articulated objects in the open world. Efficient learning is enabled by a structured action space with parametric primitives, and by pretraining the policy on a demonstration dataset using imitation learning. Adaptive learning allows the robot to keep learning from self-practice data via online RL. Repeated interaction for autonomous learning requires capable hardware, for which we propose a versatile, agile, low-cost easy to build system. We introduce a low-cost mobile manipulation hardware platform that offers a high payload, making it capable of repeated interaction with objects, e.g. a heavy, spring-loaded door, and a human-size, capable of maneuvering across various doors and navigating around narrow and cluttered spaces in the open world. We conducted a field test of 8 novel objects ranging across 4 buildings on a university campus to test the effectiveness of our system, and found adaptive earning boosts success rate from 50% from the pre-trained policy to 95% after adaptation.
在本文中,我们介绍了开放式移动操作系统,这是一个全栈方法,旨在解决在开放世界中对实际关节对象进行移动操作的问题。通过使用参数化基本动作的结构化行动空间,和在演示数据集上使用模仿学习预训练策略,我们实现了有效学习。自适应学习使机器人能够通过在线强化学习从自我实践数据中不断学习。为了进行自主学习的反复互动,需要有能力的硬件,因此我们提出了一个多功能、灵活、低成本且易于构建的系统。我们引入了一个低成本的移动操作硬件平台,具有较大的负载能力,使其能够与对象进行反复互动,例如重的弹簧门。并且尺寸与人体一样,能够穿过各种门,并在开放世界中狭窄而杂乱的空间中导航。我们在大学校园内的4座建筑中进行了包含8个新对象的实地测试,以测试我们系统的有效性,并发现自适应学习将成功率从预训练策略的50%提高到95%。
II. RELATED WORK
II. 相关工作
a) Adaptive Real-world Robot Learning: There has been a lot of prior work that studies how robots can acquire new behavior by directly using real-world interaction samples via reinforcement learning using reward [19]–[22] and even via unsupervised exploration [23], [24]. More recently there have been approaches that use RL to fine-tune policies that have been initialized via other sources of data - either using offline robot datasets [25], simulation [26] or human video [27], [28] or a combination of these approaches [10]. There works do not use any demonstrations on the test environment, and learn behavior via reinforcement as opposed to imitation. We operate in a similar setting, and focus on demonstrating RL adaptation on mobile manipulation systems that can be deployed in open-world environments. While prior large-scale industry efforts also investigate this [10], we seek to be able to learn much more efficiently with fewer data samples.
a) 自适应现实世界机器人学习:有许多先前的工作研究了机器人如何通过使用强化学习的奖励[19]–[22],直接利用真实世界的互动样本,甚至通过无监督探索[23],[24]获得新行为的问题。最近有一些方法使用强化学习来微调通过其他数据源初始化的策略,无论是使用离线机器人数据集[25]、模拟[26]还是人类视频[27],[28],或这些方法的组合[10]。这些工作没有在测试环境中使用任何演示,而是通过强化而不是模仿来学习行为。我们使用类似的设置,并专注于展示可部署在开放式世界环境中的移动操作系统的强化学习适应性。尽管先前的大规模工业工作也在研究这个问题[10],但我们希望能够以更少的数据样本更有效地学习。
b) Learning-based Mobile Manipulation Systems. : In recent years, the setup for mobile manipulation tasks in both simulated and real-world environments has been a prominent topic of research [5], [29]–[37]. Notably, several studies have explored the potential of integrating Large Language Models into personalized home robots, signifying a trend towards more interactive and user-friendly robotic systems [37]– [39]. While these systems display impressive long horizon capabilities using language for planning, these assume fixed low-level primitives for control. In our work we seek to learn low-level control parameters via interaction. Furthermore, unlike the majority of prior research which predominantly focuses on pick-move-place tasks [9], we consider operating articulated objects in unstructured environments, which present an increased level of difficulty.
b) 基于学习的移动操作系统:近年来,模拟和实际环境中的移动操作任务设置一直是研究的突出主题[5],[29]–[37]。值得注意的是,一些研究探讨了将大型语言模型整合到个性化家庭机器人中的潜力,标志着朝着更互动和用户友好的机器人系统的趋势[37]–[39]。虽然这些系统使用语言进行规划显示了令人印象深刻的长期能力,但这些系统假设了固定的低级基元用于控制。在我们的工作中,我们试图通过互动,学习低级控制参数。此外,与大多数先前研究主要集中在拾取-移动-放置任务[9]的情况不同,我们考虑在非结构化环境中操作关节对象,这提高了难度水平。
c) Door Manipulation: The research area of door opening has a rich history in the robotics community [15]–[18], [40]. A significant milestone in the domain was the DARPA Robotics Challenge (DRC) finals in 2015. The accomplishment of the WPI-CMU team in door opening illustrated not only advances in robotic manipulation and control but also the potential of humanoid robots to carry out intricate tasks in real-world environments [12]–[14]. Nevertheless, prior to the deep learning era, the primary impediment was the robots’ perception capabilities, which faltered when confronted with tasks necessitating visual comprehension of complex and unstructured environments. Approaches using deep learning to address vision challenges include Wang et al. [41], which leverages synthetic data to train keypoint representation for the grasping pose estimation, and Qin et, al. [42], which proposed an end-end point cloud RL framework for sim2real transfer. Another approach is to use simulation to learn policies, using environments such as Doorgym [43], which provides a simulation benchmark for door opening tasks. The prospect of large-scale RL combined with sim-to-real transfer holds great promise for generalizing to a diverse range of doors in real-world settings [42]–[44]. However, one major drawback is that the system can only generalize to the space of assets already present while training in the simulation. Such policies might struggle when faced with a new unseen door with physical properties, texture or shape different from the training distribution. Our approach can keep on learning via real-world samples, and hence can learn to adapt to difficulties faced when operating new unseen doors.
c) 门操作:门开启的研究领域在机器人社区中有着丰富的历史[15]–[18],[40]。该领域的一个重要里程碑是2015年的DARPA机器人挑战(DRC)决赛。 WPI-CMU团队在门开启方面的成就不仅展示了机器人操作和控制的进展,也展示了人形机器人在现实环境中执行复杂任务的潜力[12]–[14]。然而,在深度学习时代之前,主要障碍是机器人的感知能力,当面临需要对复杂和非结构化环境进行视觉理解的任务时,这种能力会受到影响。使用深度学习来解决视觉挑战的方法包括Wang等人[41],该方法利用合成数据训练关键点表示进行抓握姿态估计,以及Qin等人[42],他们提出了一个端到端点云RL框架,进行从模拟到真实的转移。另一种方法是使用仿真来学习策略,使用Doorgym等环境,该环境为门开启任务提供了仿真基准。大规模强化学习结合模拟到真实的转移的前景对于在现实世界环境中概括到各种门形式[42]–[44]具有很大的潜力。然而,一个主要的缺点是该系统只能概括到模拟训练中已经存在的资产空间。当面对与训练分布不同的新未见门时,这样的策略可能会遇到困难。我们的方法可以通过真实世界样本不断学习,因此可以学会适应在操作新未见门时面临的困难。
III. ADAPTIVE LEARNING FRAMEWORK
III. 自适应学习框架
In this section, we describe our algorithmic framework for training robots for adaptive mobile manipulation of everyday articulated objects. To achieve efficient learning, we use a structured hierarchical action space. This uses a fixed highlevel action strategy and learnable low-level control parameters. Using this action space, we initialize our policy via behavior cloning (BC) with a diverse dataset of teleoperated demonstrations. This provides a strong prior for exploration and decreases the likelihood of executing unsafe actions. However, the initialized BC policy might not generalize to every unseen object that the robot might encounter due to the large scope of variation of objects in open-world environments. To address this, we enable the robot to learn from the online samples it collects to continually learn and adapt. We describe the continual learning process as well as design considerations for online learning.
在本节中,我们描述了用于训练机器人进行适应性移动操纵日常关节对象的算法框架。为了实现高效学习,我们使用了一个结构化的分层行动空间。这个行动空间使用了一个固定的高级行动策略和可学习的低级控制参数。利用这个行动空间,我们通过行为克隆(BC)和一个多样化的远程操作演示数据集初始化我们的策略。这为探索提供了强大的先验,并降低了执行不安全动作的可能性。然而,初始化的BC策略可能无法概括到机器人可能在开放世界环境中遇到的每个未见过的对象,因为对象在这种环境中的变化范围很大。为了解决这个问题,我们使机器人能够从它收集的在线样本中不断学习和适应。我们描述了持续学习过程以及在线学习的设计考虑。

Fig. 2: Adaptive Learning Framework: The policy outputs low-level parameters for the grasping primitive, and chooses a sequence of manipulation primitives and their parameters.
图2:自适应学习框架:策略输出抓握基元的低级参数,并选择一系列操纵基元及其参数。
A. Action Space
A. 行动空间
For greater learning efficiency, we use a parameterized primitive action space. Concretely, we assume access to a grasping primitive G(.) parameterized by g. We also have a constrained mobile-manipulation primitives M(.), where primitive M(.) takes two parameters, a discrete parameter C and a continuous parameter c. Trajectories are executed in an open-loop manner, a grasping primitive followed by a sequence of N constrained mobile-manipulation primitives:
为了提高学习效率,我们使用参数化的基元行动空间。具体而言,我们假设可以访问一个由g参数化的抓握基元G(.)。我们还有一个受限移动操纵基元M(.),其中基元M(.)有两个参数,一个是离散参数C,另一个是连续参数c。轨迹以开环方式执行,首先是一个由参数化的抓握基元,然后是一系列N个受限移动操纵基元:
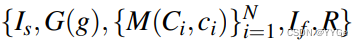
where Is is the initial observed image, G(g), M(Ci , ci)) denote the parameterized grasp and constrained manipulation primitives respectively, If is the final observed image, and r is the reward for the trajectory. While this structured space is less expressive than the full action space, it is large enough to learn effective strategies for the everyday articulated objects we encountered, covering 20 different doors, drawers, and fridges in open-world environments. The key benefit of the structure is that it allows us to learn from very few samples, using only on the order of 20-30 trajectories. We describe the implementation details of the primitives in section IV-B.
其中Is是初始观察到的图像,G(g)和M(Ci,ci))分别表示参数化的抓握和受限移动操纵基元,If是最终观察到的图像,r是轨迹的奖励。虽然这个结构化的空间不如完整的行动空间表达丰富,但它足够大,可以学到在我们遇到的日常关节对象上的有效策略,涵盖了在开放世界环境中的20个不同门、抽屉和冰箱。这个结构的关键好处是它允许我们从非常少量的样本中学习,只需要大约20-30个轨迹。我们在第 IV-B 节中描述了基元的实现细节。
B. Adaptive Learning
B. 自适应学习
Given an initial observation image Is , we use a classifier πφ ({Ci} N i=1 |I) to predict the a sequence of N discrete parameters {Ci} N i=1 for constrained mobile-manipulation, and a conditional policy network πθ (g,{ci} N i=1 |I,{Ci} N i=1 ) which produces the continuous parameters of the grasping primitive and a sequence of N constrained mobile-manipulation primitives. The robot executes the parameterized primitives one by one in an open-loop manner.
给定初始观察图像 Is,我们使用一个分类器 πφ ({Ci} N i=1 |I) 来预测 N 个受限移动操纵的离散参数{Ci} N i=1,以及一个条件策略网络 πθ (g,{ci} N i=1 |I,{Ci} N i=1 ),该网络生成抓握基元的连续参数和一系列 N 个受限移动操纵基元。机器人以开环方式依次执行参数化基元。
-
Imitation: We start by initializing our policy using a small set of expert demonstrations via behavior cloning. The details of this dataset are described in section IVC. The imitation learning objective is to learn policy parameters πθ,φ that maximize the likelihood of the expert actions. Specifically, given a dataset of image observations Is , and corresponding actions {g,{Ci} N i=1 ,{ci} N i=1 }, the imitation learning objective is:
模仿学习:我们首先通过行为克隆使用一小组专家演示来初始化我们的策略。该数据集的详细信息在第 IV-C 节中描述。模仿学习的目标是学习策略参数πθ,φ,使得该策略在专家动作的可能性最大化。具体来说,给定一个图像观察数据集 Is,以及相应的动作 {g,{Ci} N i=1 ,{ci} N i=1 },模仿学习的目标是:

-
Online RL: The central challenge we face is operating new articulated objects that fall outside the behavior cloning training data distribution. To address this, we enable the policy to keep improving using the online samples collected by the robot. This corresponds to maximizing the expected sum of rewards under the policy :
在线强化学习:我们面临的主要挑战是操作新的关节对象,这些对象不在行为克隆的训练数据分布之内。为了解决这个问题,我们使策略能够使用机器人收集的在线样本不断改进。这对应于最大化在策略下的奖励总和:
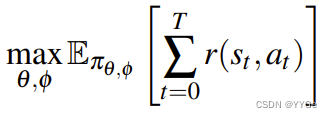
Since we utilize a highly structured action space as described previously, we can optimize this objective using a fairly simple RL algorithm. Specifically we use the REINFORCE objective [45]:
由于我们使用了如前所述高度结构化的行动空间,我们可以使用相当简单的强化学习算法来优化这个目标。具体来说,我们使用 REINFORCE 目标 [45]:
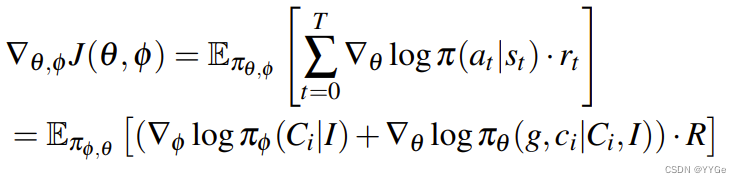
where R is the reward provided at the end of trajectory execution. Note that we only have a single time-step transition, all actions are determined from the observed image Is , and executed in an open-loop manner. Further details for online adaptation such as rewards, resets and safety are detailed in section IV-D.
其中 R 是在轨迹执行结束时提供的奖励。请注意,我们只有一个时间步的转换,所有的动作都是从观察到的图像 Is 决定的,并以开环方式执行。有关在线适应的详细信息,如奖励、重置和安全性,详见第 IV-D 节。
- Overall Finetuning Objective: To ensure that the policy doesn’t deviate too far from the initialization of the imitation dataset, we use a weighted objective while finetuning, where the overall loss is :
总体微调目标:为了确保策略在微调过程中不偏离模仿数据集的初始化,我们在微调过程中使用加权目标,其中总体损失为:
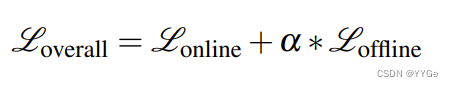
where loss on online sampled data is optimized via Eq.4 and loss on the batch of offline data is optimized via BC as in Eq.2. We use equal sized batches for online and offline data while performing the update
其中在线采样数据的损失通过公式4进行优化,离线数据批次的损失通过公式2进行模仿学习时进行优化。在执行更新时,我们使用相等大小的批次进行在线和离线数据。
IV. OPEN-WORLD MOBILE MANIPULATION SYSTEMS
IV. 开放世界移动操纵系统
In this section, we describe details of our full-stack approach encompassing hardware, action space for efficient learning, the demonstration dataset for initialization of the policy and crucially details of autonomous, safe execution with rewards. This enables our mobile manipulation system to adaptively learn in open-world environments, to manipulate everyday articulated objects like cabinets, drawers, refrigerators, and doors.
在本节中,我们详细描述了我们的全栈方法,包括硬件、用于高效学习的行动空间、策略初始化的演示数据集以及关于自主、安全执行和奖励的关键细节。这使得我们的移动操纵系统能够在开放世界环境中适应性地学习,以操作日常的关节对象,如橱柜、抽屉、冰箱和门。
A. Hardware
A. 硬件
The transition from tabletop manipulation to mobile manipulation is challenging not only from algorithmic studies but also from the perspective of hardware. In this project, we provide a simple and intuitive solution to build a mobile manipulation the hardware platform. Specifically, our design addresses the following challenges
从算法研究的角度来看,从桌面操纵过渡到移动操纵不仅具有挑战性,而且从硬件的角度来看也是如此。在这个项目中,我们提供了一个构建移动操纵硬件平台的简单而直观的解决方案。具体而言,我们的设计解决了以下挑战:
Versatility and agility: Everyday articulated objects like doors have a wide degree of variation of physical properties, including weight, friction and resistance. To successfully operate these, the platform must offer high payload capabilities via a strong arm and base. Additionally, we sought to develop a human-sized, agile platform capable of maneuvering across various realworld doors and navigating unstructured and narrow environments, such as cluttered office spaces
多功能和灵活性:日常的关节对象,如门,其物理属性具有很大的变化,包括重量、摩擦和阻力。为了成功操作这些对象,平台必须通过强大的机械臂和底盘提供高有效载荷能力。此外,我们努力开发一种人类大小的、灵活的平台,能够在各种实际门和非结构化狭窄环境中机动,比如拥挤的办公空间。
Affordability and Rapid-Prototyping: The platform is designed to be low-cost for most robotics labs and employs off-the-shelf components. This allows researchers to quickly assemble the system with ease, allowing the possibility of large-scale open-world data collection in the future.
负担得起和快速原型设计:该平台设计成对大多数机器人实验室来说成本较低,并采用现成的组件。这使得研究人员能够轻松快速地组装系统,为未来可能的大规模开放世界数据收集提供了可能性。
We show the different components of the hardware system in Figure 3. Among the commercially available options, we found the Ranger Mini 2 from AgileX to be an ideal choice for robot base due to its stability, omni-directional velocity control, and high payload capacity. The system uses an xArm for manipulation, which is an effective low-cost arm with a high payload (5kg), and is widely accessible for research labs. The system uses a Jetson computer to support real-time communication between sensors, the base, the arm, as well as a server that hosts large models. We use a D435 Intel Realsense camera mounted on the frame to collect RGBD images as ego-centric observations and a T265 Intel Realsense camera to provide visual odometry which is critical for resetting the robot when performing trials for RL. The gripper is equipped with a 3d-printed hooker and an antislip tape to ensure a secure and stable grip. The overall cost of the entire system is around 20,000 USD, making it an affordable solution for most robotics labs.
我们在图3中展示了硬件系统的不同组件。在商业可用的选项中,我们发现AgileX的Ranger Mini 2是机器人底盘的理想选择,因为它具有稳定性、全向速度控制和高有效载荷容量。系统使用xArm进行操作,这是一款有效的低成本机械臂,具有高有效载荷(5kg),并且广泛可用于研究实验室。系统使用Jetson计算机支持传感器、底盘、机械臂之间的实时通信,以及托管大型模型的服务器。我们使用安装在框架上的Intel Realsense D435相机来收集RGBD图像作为自我感知的观察,并使用Intel Realsense T265相机提供视觉里程计,对于在进行强化学习试验时重置机器人至关重要。夹爪配备了一个3D打印的勾子和防滑胶带,以确保牢固而稳定的夹持。整个系统的总成本约为20,000美元,这使得它对于大多数机器人实验室来说是一个负担得起的解决方案。
Fig. 3: Mobile Manipulation Hardware Platform: Different components in the mobile manipulator hardware system. Our design is low-cost and easy-to-build with off-the-shelf components
We compare key aspects of our modular platform with that of other mobile manipulation platforms in Table I.This comparison highlights advantages of our system such as cost effectiveness, reactivity, ability to support a high-payload arm, and a base with omnidirectional drive.
我们将我们的模块化平台与其他移动操纵平台的关键方面进行了比较,如表I所示。这个比较突显了我们系统的优势,如成本效益、反应速度、支持高有效载荷机械臂以及具有全向驱动的底盘。

TABLE I: Comparison of different aspects of popular hardware systems for mobile manipulation
表I:对于移动操纵的流行硬件系统的不同方面进行比较
B. Primitive Implementation
B. 基本操作的实现
In this subsection, we describe the implementation details of our parameterized primitive action space.
在这一小节中,我们描述了我们参数化的基本操作空间的实现细节。
- Grasping: Given the RGBD image of the scene obtained from the realsense camera, we use off-the-shelf visual models [46], [47] to obtain the mask of the door and handle given just text prompts. Furthermore, since the door is a flat plane, we can estimate the surface normals of the door using the corresponding mask and the depth image. This is used to move the base close to the door and align it to be perpendicular, and also to set the orientation angle for grasping the handle. The center of the 2d mask of the handle is projected into 3d coordinates using camera calibration, and this is the nominal grasp position. The low-level control parameters to the grasping primitive indicate an offset for this position at which to grasp. This is beneficial since depending on the type of handle the robot might need to reach a slightly different position which can be learned via the low-level continuous valued parameters.
抓取:给定从Realsense相机获取的场景的RGBD图像,我们使用现成的视觉模型[46],[47]来获得门和把手的掩模,只需使用文本提示。此外,由于门是一个平面,我们可以使用相应的掩模和深度图像来估算门的表面法线。这用于将底座移动到门附近并使其垂直对齐,还用于设置抓取把手的方向角度。把手的2D掩模的中心通过相机校准投影到3D坐标中,这是标准抓取位置。对于抓取基元的低级控制参数指示了此位置的偏移,用于抓取。这是有益的,因为根据把手的类型,机器人可能需要到达略有不同的位置,这可以通过学习低级连续值参数来实现。
2)Constrained Mobile-Manipulation: We use velocity control for the robot arm end-effector and the robot base. With a 6dof arm and 3dof motion for the base (in the SE2 plane), we have a 9-dimensional vector
有约束的移动操纵:我们使用速度控制来控制机器人臂末端执行器和机器人底座。通过6自由度的机械臂和底座的3自由度运动(在SE2平面上),我们得到一个9维向量:
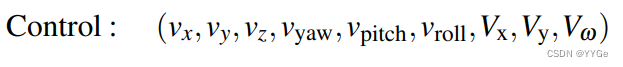
Where the first 6 dimensions correspond to control for the arm, and the last three are for the base. The primitives we use impose contraints on this space as follows -
其中前6个维度对应于机械臂的控制,最后三个维度对应于底座。我们使用的基本操作对此空间施加了以下约束 -

For control, the policy outputs an index corresponding to which primitive is to executed, as well as the corresponding low-level parameters for the motion. The low-level control command is continuous valued from -1 to 1 and executed for a fixed duration of time. The sign of the parameters dictates the direction of the velocity control, either clockwise or counter-clockwise for unlock and rotate, and forward or backward for open.
对于控制,策略输出一个对应于要执行的基元的索引,以及运动的相应低级参数。低级控制命令的值在-1到1之间,并在固定的时间内执行。参数的符号决定了速度控制的方向,无论是顺时针还是逆时针用于解锁和旋转,还是向前还是向后用于打开。
C. Pretraining Dataset
C. 预训练数据集
The articulated objects we consider in this project consist of three rigid parts: a base part, a frame part, and a handle part. This covers objects such as doors, cabinets, drawers and fridges. The base and frame are connected by either a revolute joint (as in a cabinet) or a prismatic joint (as in a drawer). The frame is connected to the handle by either a revolute joint or a fixed joint. We identify four major types of the articulated objects, which relate to the type of handle, and the joint mechanisms. Handle articulations commonly include levers (Type A) and knobs (Type B). For cases where handles are not articulated, the body-frame can revolve about a hinge using a revolute joint (Type C), or slide back and forth along a prismatic joint, for example, drawers (Type D). While not exhaustive, this categorization covers a wide variety of everyday articulated objects a robot system might encounter. To provide generalization benefits in operating unseen novel articulated objects, we first collect a offline demonstration dataset. We include 3 objects from each category in the BC training dataset, collecting 10 demonstrations for each object, producing a total of 120 trajectories.
在这个项目中,我们考虑的关节对象包括三个刚性部分:底座部分、框架部分和把手部分。这涵盖了诸如门、柜子、抽屉和冰箱等对象。底座和框架通过旋转关节(如柜子中)或平移关节(如抽屉中)相连接。框架与把手之间通过旋转关节或固定关节相连接。我们识别了四种主要类型的关节对象,这些对象与把手的类型和关节机制有关。把手的关节通常包括杠杆(A型)和旋钮(B型)。对于把手不是关节化的情况,机体框架可以围绕铰链旋转,使用旋转关节(C型),或者沿着平移关节来回滑动,例如抽屉(D型)。虽然这不是穷尽一切,但这种分类涵盖了机器人系统可能遇到的各种日常关节对象。为了在操作未见过的新关节对象时提供泛化效益,我们首先收集了一个离线演示数据集。我们在BC训练数据集中包含了每个类别的3个对象,为每个对象收集了10个演示,总共产生了120条轨迹。
We also have 2 held-out testing objects from each category for generalization experiments. The training and testing objects differ significantly in visual appearance (eg. texture, color), physical dynamics (eg. if spring-loaded), and actuation (e.g. the handle joint might be clockwise or counterclockwise). We include visualizations of all objects used in train and test sets in Fig. 4, along with which part of campus they are from as visualized in Fig. 5.

Fig. 4: Articulated Objects: Visualization of the 12 training and 8 testing objects used, with location indicators corresponding to the buildings in the map below. The training and testing objects are significantly different from each other, in terms of different visual appearances, different modes of articulation, or different physical parameters, e.g. weight or friction.
Fig. 4: 关节对象:展示了用于训练和测试的12个对象的可视化,其中位置指示符对应下图地图中的建筑物。在视觉外观、关节模式或物理参数(如重量或摩擦)方面,训练和测试对象在很大程度上不同。
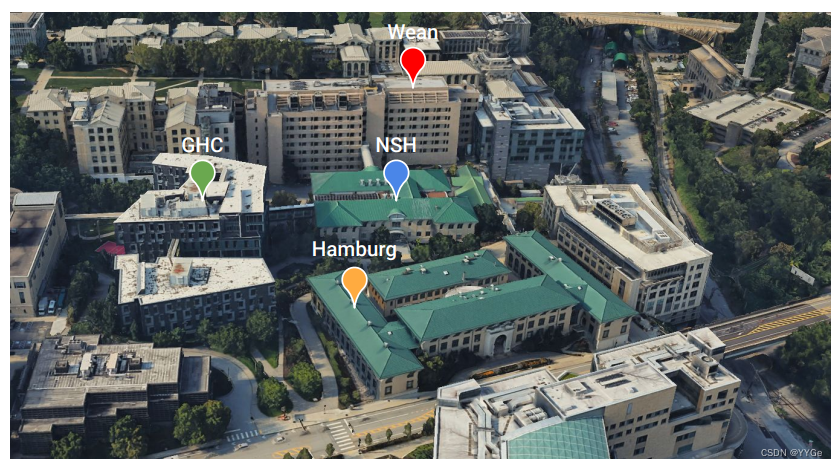
Fig. 5: Field Test on CMU Campus: The system was evaluated on articulated objects from across four distinct buildings on the Carnegie Mellon University campus.
Fig. 5: 在CMU校园的现场测试:系统在卡内基梅隆大学校园的四个不同建筑物上的关节对象上进行了评估。
D. Autonomous and Safe Online Adaptation
D. 自主和安全的在线适应
The key challenge we face is operating with new objects that fall outside the BC training domain. To address this, we develop a system capable of fully autonomous Reinforcement Learning (RL) online adaptation. In this subsection, we demonstrate the details of the autonomy and safety of our system.
我们面临的主要挑战是操作新的对象,这些对象超出了BC训练领域。为了解决这个问题,我们开发了一个能够完全自主进行强化学习(RL)在线适应的系统。在这个小节中,我们展示了我们系统的自主性和安全性的细节。
- Safety Aware Exploration: It is crucial to ensure that the actions the robot takes for exploring are safe for its hardware, especially since it is interacting with objects under articulation constraints. Ideally, this could be addressed for dynamic tasks like door opening using force control. However, low-cost arms like the xarm-6 we use do not support precise force sensing. For deploying our system, we use a safety mechanism based which reads the joint current during online sampling. If the robot samples an action that causes the joint current to meet its threshold, we terminate the episode and reset the robot, to prevent the arm from potentially damaging itself, and also provide negative reward to disincentivize such actions.
安全感知的探索:确保机器人进行探索的动作对其硬件是安全的至关重要,特别是因为它正在与关节约束下的物体进行交互。理想情况下,对于像开门这样的动态任务,可以使用力控制来解决这个问题。然而,我们使用的xarm-6等低成本机械臂不支持精确的力传感。在部署我们的系统时,我们使用一种基于在线采样期间读取关节电流的安全机制。如果机器人对一个导致关节电流达到其阈值的动作进行采样,我们会终止该episode并重置机器人,以防止机械臂潜在地损坏自身,并提供负面奖励以阻止这样的行为。
- Reward Specification: In our main experiments, a human operator provides rewards- with +1 if the robot succesfully opens the doors, 0 if it fails, and -1 if there is a safety violation. This is feasible since the system requires very few samples for learning. For autonomous learning however, we would like to remove the bottleneck of relying on humans to be present in the loop. We investigate using large vision language models as a source of reward. Specifically, we use CLIP [50] to compute the similarity score between two text prompts and the image observed after robot execution. The two prompts we use are - ”door that is closed” and ”door that is open”. We compute the similarity score of the final observed image and each of these prompts and assign a reward of +1 if the image is closer to the prompt indicating the door is open, and 0 in the other case. If a safety protection is triggered the reward is -1.
奖励规范:在我们的主要实验中,人类操作员提供奖励,如果机器人成功打开门,则为+1,如果失败则为0,如果存在安全违规则为-1。这是可行的,因为系统对于学习只需要很少的样本。然而,对于自主学习,我们希望消除依赖人类存在的瓶颈。我们研究使用大型视觉语言模型作为奖励的来源。具体而言,我们使用CLIP [50]计算两个文本提示和机器人执行后观察到的图像之间的相似性分数。我们使用的两个提示是 - “门是关闭的” 和 “门是打开的”。我们计算最终观察到的图像与这些提示之一的相似性分数,并在图像更接近指示门打开的提示时分配+1的奖励,在其他情况下为0。如果触发了安全保护,奖励为-1。
- Reset Mechanism: The robot employs visual odometry, utilizing the T265 tracking camera mounted on its base, enabling it to navigate back to its initial position. At the end of every episode, the robot releases its gripper, and moves back to the original SE2 base position, and takes an image of If for computing reward. We then apply a random perturbation to the SE2 position of the base so that the policy learns to be more robust. Furthermore, if the reward is 1, where the door is opened, the robot has a scripted routine to close the door.
重置机制:机器人使用视觉测距,利用安装在其底座上的T265跟踪相机,使其能够导航回初始位置。在每个episode结束时,机器人释放其夹爪,返回到原始的SE2底座位置,并拍摄If的图像以计算奖励。然后,我们对基座的SE2位置施加随机扰动,以使策略学会更加鲁棒。此外,如果奖励为1,表示门已打开,机器人会执行脚本例程来关闭门。
V. RESULTS
V. 结果
We conduct an extensive field study involving 12 training objects and 8 testing objects across four distinct buildings on the Carnegie Mellon University campus to test the efficacy of our system. In our experiments, we seek to answer the following questions:
我们进行了一项广泛的实地研究,涉及卡内基梅隆大学校园四个独立建筑中的12个训练对象和8个测试对象,以测试我们系统的有效性。在我们的实验中,我们试图回答以下问题:
- Can the system improve performance on unseen objects via online adaptation across diverse object categories? 2) How does this compare to simply using imitation learning on provided demonstrations? 3) Can we automate providing rewards using off-the-shelf vision-language models? 4) How does the hardware design compare with other platforms?
1)系统是否能通过在线适应改善对未见过对象的性能,跨越不同的物体类别?
2) 这与仅使用提供的演示,进行模仿学习相比如何?
3) 我们是否可以使用现成的视觉语言模型自动提供奖励?
4) 硬件设计与其他平台相比如何?
A. Online Improvement
A. 在线改善
- Diverse Object Category Evaluation: : We evaluate our approach on 4 categories of held-out articulated objects. As described in section IV-C, these are determined by handle articulation and joint mechanisms. This categorization is based on types of handles, including levers (type A) and knobs (type B), as well as joint mechanisms including revolute (type C) and prismatic (type D) joints. We have two test objects from each category. We report continual adaptation performance in Fig. 6 over 5 iterations of finetuning using online interactions, starting from the behavior cloned initial policy. Each iteration of improvement consists of 5 policy rollouts, after which the model is updated using the loss in Equation 5.
不同对象类别的评估:我们在4个被保留的关节对象类别上评估我们的方法。如第IV-C节所述,这些类别是由手柄关节和关节机制决定的。此分类基于手柄类型,包括杆(类型A)和旋钮(类型B),以及关节机制,包括旋转(类型C)和棱柱(类型D)关节。我们每个类别有两个测试对象。我们在图6中报告了通过在线交互进行5次微调的持续适应性表现,从克隆行为的初始策略开始。改进的每个迭代包括5次策略展开,之后使用方程5中的损失更新模型。
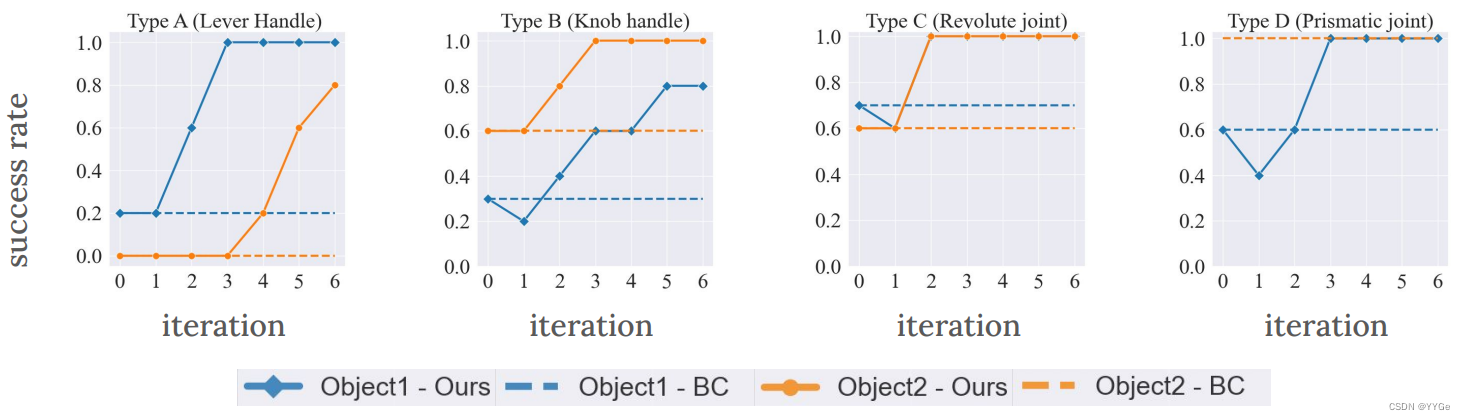
Fig. 6: Online Improvement: Comparison of our approach to the imitation policy on 4 different categories of articulated objects, each consisting of two different objects. Our adaptive approach is able to improve in performance, while the imitation policy has limited generalization.
图6:在线改进:比较我们的方法与模仿策略在四个不同类别的关节对象上的表现,每个类别包括两个不同的对象。我们的自适应方法能够在性能上取得改进,而模仿策略的泛化能力有限。
From Fig. 6, we see that our approach improves the average success rate across all objects from 50 to 95 percent. Hence, continually learning via online interaction samples is able to overcome the limited generalization ability of the initial behavior cloned policy. The adaptive learning procedure is able to learn from trajectories that get high reward, and then change its behavior to get higher reward more often. In cases where the BC policy is reasonably performant, such as Type C and D objects with an average success rate of around 70 percent, RL is able to perfect the policy to 100 percent performance. Furthermore, RL is also able to learn how to operate objects even when the initial policy is mostly unable to perform the task. This can be seen from the Type A experiments, where the imitation learning policy has a very low success rate of only 10 percent, and completely fails to open one of the two doors. With continual practice, RL is able to achieve an average success of 90 percent. This shows that RL can explore to take actions that are potentially out of distribution from the imitation dataset, and learn from them, allowing the robot to learn how to operate novel unseen articulated objects.
从图6中,我们可以看到我们的方法将所有对象的平均成功率从50%提高到95%。因此,通过在线交互样本持续学习,能够克服初始克隆行为策略的有限泛化能力。自适应学习过程能够从获得高奖励的轨迹中学习,然后改变其行为以更经常地获得更高的奖励。在BC策略相当有效的情况下,例如类型C和D对象,平均成功率约为70%,RL能够将策略完善到100%的性能。此外,RL还能够学习如何操作对象,即使初始策略在执行任务方面基本无法完成。这可以从类型A的实验中看出,其中模仿学习策略的成功率仅为10%,并且完全无法打开其中的一个门。通过不断的练习,RL能够实现90%的平均成功率。这表明RL可以探索采取潜在分布之外的行动,并从中学习,使机器人能够学习如何操作新的未见过的关节对象。
- Action-replay baseline: : There is also another very simple approach for utilizing a dataset of demonstrations for performing a task on a new object. This involves replaying trajectories from the closest object in the training set. This closest object can be found using k-nearest neighbors with some distance metric. This approach is likely to perform well especially if the distribution gap between training and test objects is small, allowing the same actions to be effective. We run this baseline for two objects that are particularly hard for behavior cloning, one each from Type A and B categories (lever and knob handles respectively). The distance metric we use to find the nearest neighbor in the training set is euclidean distance of the the CLIP encoding of observed images. We evaluate this baseline both in an openloop and closed-loop manner. In the former case, only the first observed image is used for comparison and the entire retrieved action sequence is executed, and in the latter we search for the closest neighbor after every step of execution and perform the corresponding action. From Table III we see that this approach is quite ineffective, further underscoring the distribution gap between the training and test objects in our experiments.
动作重放基线:还有另一种非常简单的方法可以利用演示数据集来执行一个新对象的任务。这涉及从训练集中最接近的对象中重放轨迹。可以使用k最近邻和一些距离度量来找到最接近的对象。如果训练和测试对象之间的分布差距较小,允许相同的动作是有效的,那么这种方法可能表现得很好。我们对两个特别难以进行行为克隆的对象运行了此基线,分别来自A和B类别(分别为杆和旋钮手柄)。我们用观察图像的CLIP编码的欧几里得距离作为找到训练集中最近邻的距离度量。我们以开环和闭环方式评估此基线。在前一种情况下,仅使用第一个观察到的图像进行比较,并执行整个检索到的动作序列,在后一种情况下,在每个执行步骤之后搜索最近邻,并执行相应的动作。从表III中,我们可以看出这种方法效果不佳,进一步强调了我们实验中训练和测试对象之间的分布差距。

TABLE III: We compare the performance of our adaptation policies and initialized BC policies with KNN baselines.
表III:我们将自适应策略和初始化的BC策略与KNN基线进行比较,显示了它们的性能。
- Autonomous reward via VLMs: We investigate whether we can replace the human operator with an automated procedure to provide rewards. The reward is given by computing the similarity score between the observed image at the end of execution, and two text prompts, one of which indicate that the door is open, and the other that says the doors is closed, as described in section IV-D.
通过VLM自主奖励:我们调查是否可以用自动化程序替换人类操作员来提供奖励。奖励是通过计算执行结束时观察到的图像与两个文本提示之间的相似性得分来给定的,其中一个提示表示门是打开的,另一个提示表示门是关闭的,如第IV-D节所述。
As with the actionreplay baseline, we evalute this on two test doors, on each from the handle and knob categories. From Table II, we see that online adaptation with VLM reward achieves a similar performance as using groundtruth human-labeled reward, with an average of 80 percent compared to 90 percent. We also report the performance after every iteration of training in Fig. 7. Removing the need for a human operator to be present in the learning loop opens up the possiblity for autonomous training and improvement.
与动作重放基线一样,我们在两个测试门上进行评估,每个门分别来自手柄和旋钮类别。从表II中,我们看到使用VLM奖励的在线适应与使用地面真实人工标注的奖励实现了类似的性能,平均为80%,而地面真实人工标注的性能为90%。我们还在图7中报告了每次训练迭代后的性能。不需要人类操作员在学习循环中出现的可能性为自主训练和改进打开了可能性。

TABLE II: In this table, we present improvements in online adaptation with CLIP reward.
表II:在这个表格中,我们展示了使用CLIP奖励的在线自适应的改进。
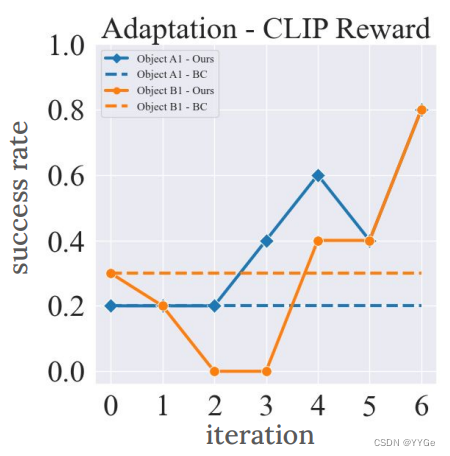
Fig. 7: Online Adaptation with CLIP reward. Adaptive learning using rewards from CLIP, instead of a human operator, showing our system can operate autonomously
图7:使用CLIP奖励的在线适应。采用来自CLIP的奖励而不是人类操作员,显示我们的系统可以自主运行。
B. Hardware Teleop Strength
B:硬件遥控强度
In order to successfully operate various doors the robot needs to be strong enough to open and move through them. We empirically compare against a different popular mobile manipulation system, namely the Stretch RE1 (Hello Robot). We test the ability of the robots to be teleoperated by a human expert to open two doors from different categories, specifically lever and knob doors. Each object was subjected to five trials. As shown is Table IV, the outcomes of these trials revealed a significant limitation of the Stretch RE1: its payload capacity is inadequate for opening a real door, even when operated by an expert, while our system succeeds in all trials.
为了成功操作各种门,机器人需要足够强大,能够打开并通过它们。我们与另一种流行的移动操作系统进行了实证比较,即Stretch RE1(Hello Robot)。我们测试了人类专家遥控机器人打开两扇不同类型的门(杠杆门和旋钮门)的能力。每个对象都经历了五次试验。如表IV所示,这些试验的结果揭示了Stretch RE1的一个显著局限性:即使由专家操作,其有效载荷能力不足以打开真正的门,而我们的系统在所有试验中都成功了。

TABLE IV: Human expert teleoperation success rate using stretch and our system for opening doors
VI. CONCLUSION
VI. 结论
We present a full-stack system for adaptive learning in open world environments to operate various articulated objects, such as doors, fridges, cabinets and drawers. The system is able to learn from very few online samples since it uses a highly structured action space, which consists of a parametric grasp primitive, followed by a sequence of parametric constrained mobile manipulation primitives. The exploration space is further structured via a demonstration dataset on some training objects. Our approach is able to improve performance from about 50 to 95 percent across 8 unseen objects from 4 different object categories, selected from buildings across the CMU campus. The system can also learn using rewards from VLMs without human intervention, allowing for autonomous learning. We hope to deploy such mobile manipulators to continuously learn a broader variety of tasks via repeated practice.
我们提出了一个在开放环境中进行自适应学习的全栈系统,以操作各种关节对象,如门、冰箱、橱柜和抽屉。该系统能够从极少的在线样本中学习,因为它使用了一个高度结构化的动作空间,其中包括一个参数化的抓取基元,后跟一系列参数化的受限移动操纵基元。探索空间通过一些训练对象的演示数据集进一步结构化。我们的方法能够在4个不同的对象类别中的8个看不见的对象上将性能从约50%提高到95%。这些对象来自卡内基梅隆大学校园各处的建筑物。该系统还可以使用VLM的奖励进行学习,无需人为干预,实现了自主学习。我们希望能够部署这样的移动操纵器,通过反复实践不断学习更广泛的任务。
ACKNOWLEDGMENT
致谢
感谢Shikhar Bahl、Tianyi Zhang、Xuxin Cheng、Shagun Uppal和Shivam Duggal的有益讨论。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









