






各位技术爱好者们,大家好!今天我要向大家隆重介绍一个我自己开发的项目:一个使用 Streamlit 搭建的通用自适应 RAG (Retrieval-Augmented Generation,检索增强生成) Demo 应用。受到 fareedkhan-dev/all-rag-techniques 项目的启发,我希望通过一个简洁的(不依赖于langchain和其他复杂库函数)实用的、可交互的应用,让大家更直观地理解 Adaptive RAG 的魅力,并体验更智能、更精准的问答系统。
如果不了解fareedkhan-dev/all-rag-techniques 项目的可以查看我之前的文章:
告别 LangChain 和 FAISS?手把手教你玩转 21 种 RAG 技术,这个硬核项目不容错过!
告别“一招鲜”,迎接“自适应”的 RAG
传统的 RAG 系统,往往采用固定的检索和生成策略,面对各种各样的问题,难免显得有些“力不从心”。例如,对于事实性问题,我们可能希望系统快速定位到关键信息;而对于分析性问题,则需要系统进行更深度的语义理解和推理。
Adaptive RAG 的核心思想在于 “因材施教” —— 根据用户问题的类型,动态调整检索策略和生成方式,从而提供更贴合需求、质量更高的答案。我的这个 Streamlit Demo App,正是为了展示这一理念而生。
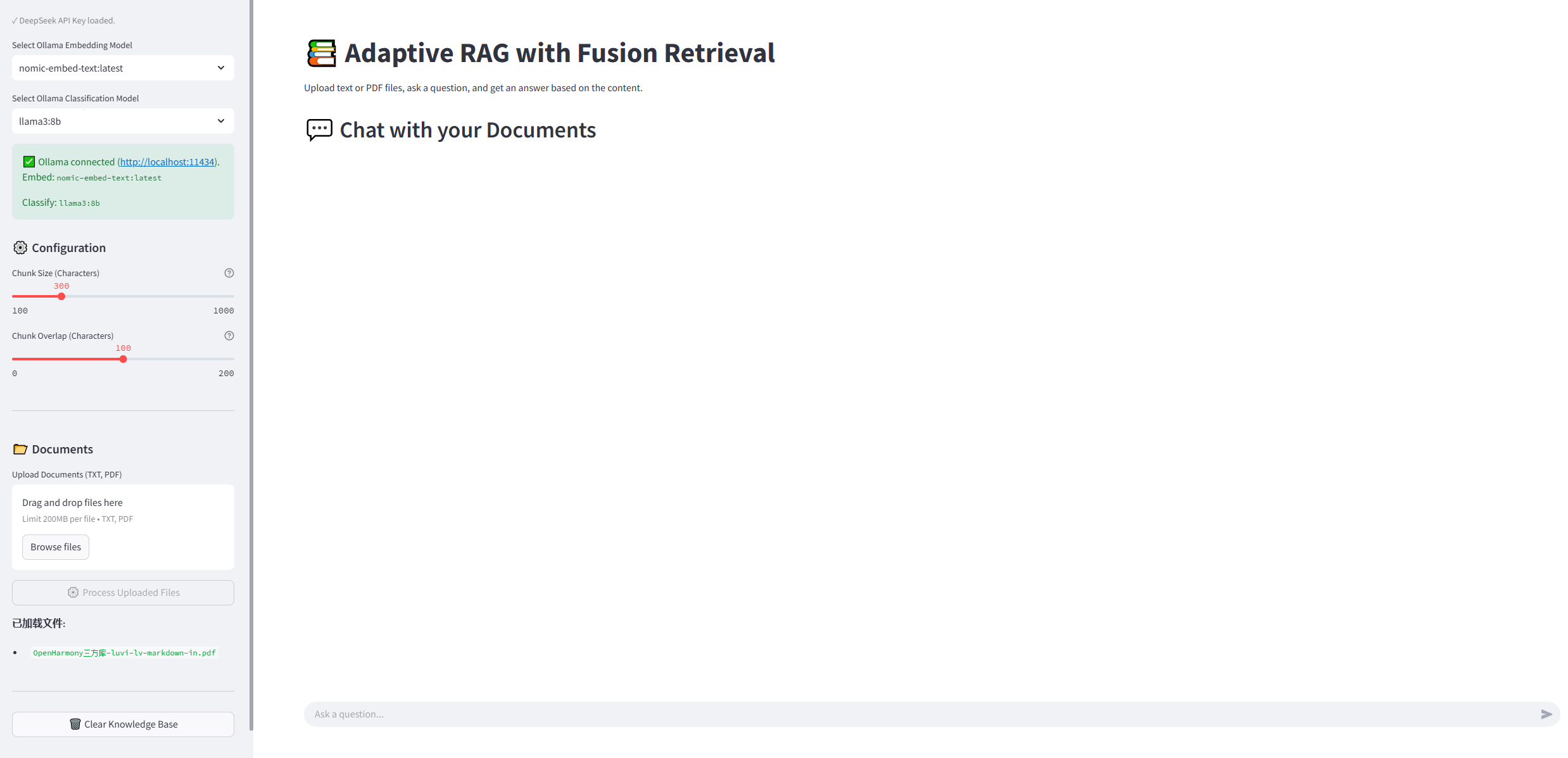
项目亮点: 从“分类”到“自适应”的 RAG 流程
我的 Demo App 也致力于揭示 RAG 技术的内在逻辑,不依赖于复杂的python库,如LangChain 和 FAISS。我使用了 Streamlit 框架来构建用户界面,专注于RAG逻辑的实现,在 RAG 的核心实现上,我尽量保持了代码的清晰性和可读性,以及前端的过程处理的直观和详细。下面我们看看核心代码:
-
智能 Query 分类 (Intelligent Query Classification): 这是自适应 RAG 的“大脑”。App 首先会对用户提出的问题进行分类,判断其属于 事实性 (Factual)、分析性 (Analytical)、观点性 (Opinion) 还是 情境性 (Contextual) 等类型。
def classify_query_ollama(query: str, model: str = OLLAMA_CLASSIFY_MODEL) -> str: """Classifies the query using a local Ollama model.""" # ... (与 Ollama 连接和错误处理代码) ... system_prompt = f"""You are a query classification expert. ... (分类指令) ...""" user_prompt = f"User Query: \"{query}\"\n\nClassify this query." try: response = ollama_client.chat( model=model, messages=[ {'role': 'system', 'content': system_prompt}, {'role': 'user', 'content': user_prompt} ], options={'temperature': 0.1} # 低温度,保证分类的确定性 ) raw_category = response['message']['content'].strip() # ... (类别提取和验证代码) ... return extracted_category except Exception as e: # ... (错误处理代码) ... return "Factual" # 分类失败时,默认使用事实性策略代码特点与优势: 我使用了 Ollama 本地模型比如qwen2.5:7b来进行 Query 分类。相较于远程 API,本地模型具有 更高的隐私性 和 更低的延迟。 以及使用了deepseek api来进行检索生成。
classify_query_ollama函数的核心逻辑在于构建合适的 System Prompt, 指导 Ollama 模型准确地将用户问题划分类别。低温度 (temperature=0.1) 的设置,保证了分类结果的 一致性和可靠性。 -
自适应检索策略路由 (Adaptive Retrieval Strategy Routing): 根据 Query 分类结果,App 会选择不同的检索策略。目前,我定义了四种基本的检索策略,分别对应四种 Query 类型:
factual_retrieval_strategy,analytical_retrieval_strategy,opinion_retrieval_strategy, 和contextual_retrieval_strategy。def adaptive_retrieval( query: str, query_type: str, vector_store: SimpleVectorStore, bm25: Optional[BM25Okapi], all_chunks: List[Dict[str, Any]], k_vector: int, k_bm25: int, k_final: int, user_context: Optional[str] = None ) -> List[Dict[str, Any]]: """Selects and executes the retrieval strategy based on query type.""" strategy_map = { "Factual": factual_retrieval_strategy, "Analytical": analytical_retrieval_strategy, "Opinion": opinion_retrieval_strategy, "Contextual": contextual_retrieval_strategy, } retrieval_function = strategy_map.get(query_type, factual_retrieval_strategy) try: results = retrieval_function( query=query, vector_store=vector_store, bm25=bm25, all_chunks=all_chunks, k_vector=k_vector, k_bm25=k_bm25, k_final=k_final, user_context=user_context ) return results except Exception as e: # ... (错误处理代码) ... return []代码特点与优势:
adaptive_retrieval函数充当了 策略路由器的角色。它根据query_type动态地调用不同的检索函数。虽然目前 Demo App 中的factual_retrieval_strategy等函数还仅仅是简单的 Hybrid Search,但这个框架已经为未来 更复杂的自适应检索逻辑 预留了扩展空间。例如,针对分析性问题,我们可以设计更精细的子查询分解或关系抽取策略;针对观点性问题,可以引入情感分析来提升检索效果。 -
Hybrid Search (融合检索): 在检索层面,我采用了 Hybrid Search 策略,融合了 向量检索 (Vector Search) 和 关键词检索 (BM25)。
def hybrid_search( query: str, vector_store: SimpleVectorStore, bm25: Optional[BM25Okapi], all_chunks: List[Dict[str, Any]], k_vector: int, k_bm25: int, k_final: int ) -> List[Dict[str, Any]]: """Performs hybrid search using vector similarity and BM25, with Reciprocal Rank Fusion.""" # ... (获取 Query Embedding 代码) ... vector_results = vector_store.search(query_embedding, k=k_vector) # 向量检索 bm25_results = search_bm25(bm25, query, all_chunks, k=k_bm25) # BM25 关键词检索 fused_scores = reciprocal_rank_fusion([vector_results, bm25_results], k_param=RRF_K) # 互惠排名融合 fused_ranked_ids = sorted(fused_scores.keys(), key=lambda x: fused_scores[x], reverse=True) # ... (根据融合排名选择最终 Chunk 代码) ... return final_chunks代码特点与优势: Hybrid Search 结合了语义向量检索和关键词检索的优点,提升了检索的召回率和准确率。
reciprocal_rank_fusion(互惠排名融合) 算法被用于有效地融合两种检索结果,确保排名靠前的结果既具有语义相关性,又兼顾关键词匹配度。 -
自适应 Response 生成 (Adaptive Response Generation): 类似于检索策略,Response 生成阶段也根据 Query 类型,采用了不同的 System Prompt。
def generate_adaptive_response( query: str, query_type: str, context_chunks: List[Dict[str, Any]], generation_model: str = "deepseek-chat", use_ollama_for_generation: bool = False ) -> Tuple[Optional[str], Optional[str]]: """Generates response using a selected prompt based on query type.""" # ... (准备 Context 代码) ... prompts = { "Factual": f"{base_instruction} Focus on extracting the specific fact requested.", "Analytical": f"{base_instruction} Provide a reasoned analysis, comparison, or summary ...", "Opinion": f"{base_instruction} Identify and report the opinions or sentiments expressed ...", "Contextual": f"{base_instruction} Use the provided context to answer the question, considering it might relate to previous interactions ...", } system_prompt = prompts.get(query_type, prompts["Factual"]) # 根据 Query 类型选择 System Prompt final_prompt_content = f"""{system_prompt} Context: {context} {'... (context truncated)' if truncated else ''} Question: {query} Answer:""" # ... (调用 LLM 生成 Response 代码 - DeepSeek 或 Ollama) ... return generated_text, source_info代码特点与优势: 针对不同类型的 Query,定制 System Prompt,指导 LLM 更好地理解用户意图,并生成更符合预期的答案。例如,对于事实性问题,Prompt 强调 “提取事实”;对于分析性问题,则引导 LLM 进行 “分析和总结”。 用户可以灵活选择使用 DeepSeek API (默认) 或 本地 Ollama 模型 进行 Response 生成。
Demo App 亮点总结:
- 自适应 RAG 流程: 完整演示了从 Query 分类到自适应检索和生成的 RAG 流程。
- 本地 Ollama 支持: Query 分类和 Embedding 生成都可使用本地 Ollama 模型,保障隐私和低延迟。
- Hybrid Search 融合检索: 结合向量检索和关键词检索,提升检索效果。
- 可扩展的架构: 策略路由和自适应 Prompt 的框架,为未来更复杂的自适应 RAG 策略预留了空间。
- Streamlit 交互界面: 简洁易用,方便用户上传文档、提问和查看结果。
适用人群与应用场景
我认为这个 Demo App 特别适合以下人群:
- RAG 技术学习者: 希望通过实践理解 Adaptive RAG 原理的开发者。
- AI 应用开发者: 希望探索如何构建更智能、更灵活的 RAG 系统的工程师。
- LLM 爱好者: 对 RAG 技术和 LLM 应用感兴趣的技术爱好者。
快速上手,体验 Adaptive RAG
如果你也想亲身体验 Adaptive RAG 的魅力,或者想深入了解代码实现细节,欢迎联系作者并亲自运行这个 Demo App!

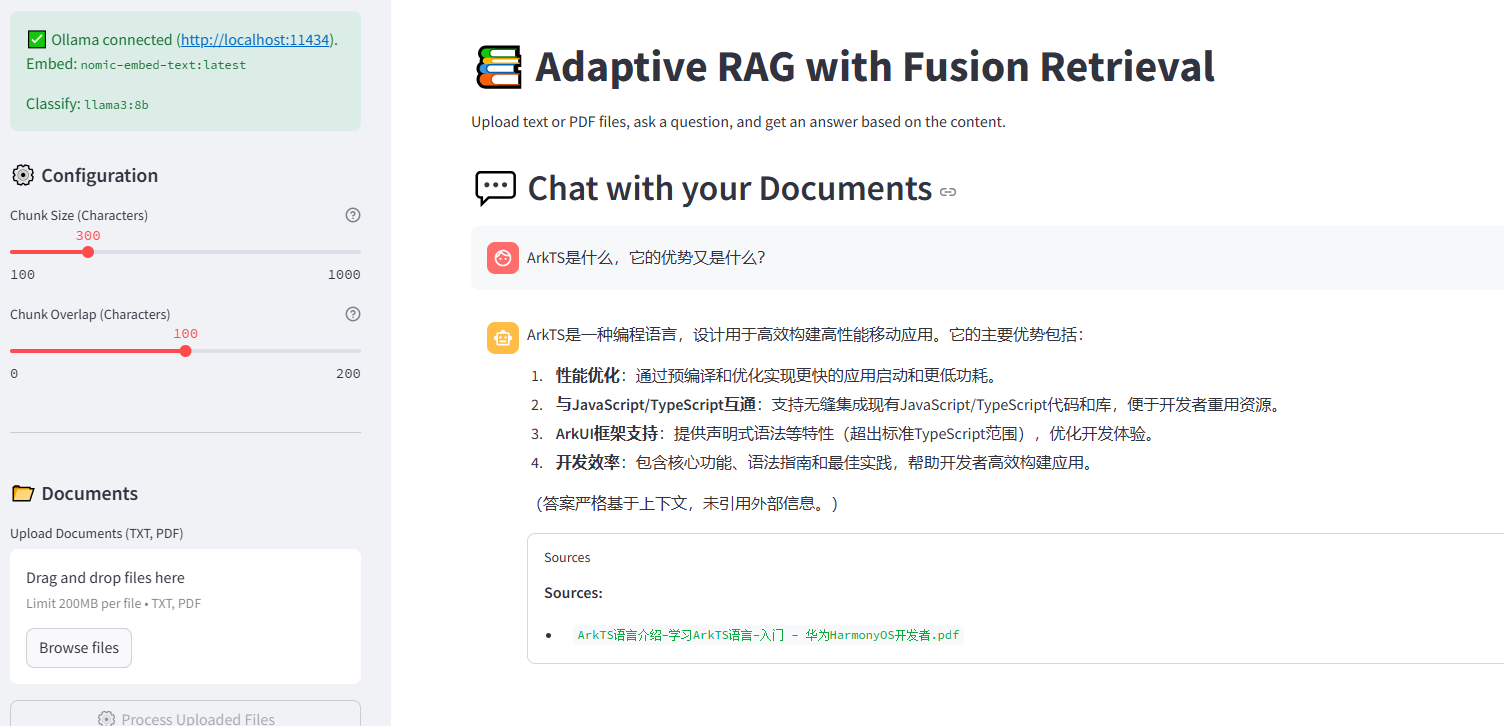
未来展望
虽然目前的 Demo App 还比较基础,但我计划在未来继续完善它,例如:
- 更精细的检索策略: 针对不同 Query 类型,实现更高级的检索算法。
- 对话历史支持: 引入对话上下文理解,实现真正的 Contextual RAG。
- 更多模型集成: 支持更多的本地 LLM 和 Embedding 模型。
- 更完善的评估指标: 加入客观评估指标,量化 Adaptive RAG 的性能提升。
我希望这个 Demo App 能够成为大家学习和探索 Adaptive RAG 的一个起点。 欢迎大家 关注这个项目,提出宝贵的意见和建议,一起推动AI技术的发展!
如果大家比较感兴趣,后期考虑将优化后的完整代码进行开源。
如果有想尝鲜的朋友可以后台私信或者点击喜欢作者。
希望这篇博文草稿对您有所帮助!
相关文章:
告别繁琐配置!这款免费开源的 AsrTools,让语音转文字效率飞起!
Auto-Deep-Research:告别昂贵的Deep Research,拥抱开源的AI助手!
MCP,你的大模型USB通用接口 - 向来如此便对吗的文章 - 知乎
Crawl4AI进阶:AI 时代的智能网页信息提取利器 - 向来如此便对吗的文章 - 知乎
Crawl4AI: 赋能AI用户的开源智能网页爬虫与数据提取 - 向来如此便对吗的文章 - 知乎

















 1683
1683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









