






自适应 RAG 是一种结合查询分析与自我纠正机制的检索增强生成技术。它通过智能分析用户的查询需求和查询复杂度,动态调整检索和生成策略,提供更为精准和高效的响应。这种方法不仅提升了生成的准确性,还增强了系统的灵活性,使其能够适应多变的数据环境和用户需求。

论文地址:https://arxiv.org/pdf/2403.14403
论文项目源码:https://github.com/starsuzi/Adaptive-RAG
在查询分析过程中,自适应 RAG 使用一个轻量级的大型语言模型(LLM)分类器来评估查询的复杂性。这种分类器可以判断查询是简单的事实性问题、需要更深入的推理,还是涉及广泛的知识领域。基于对复杂度的判断,自适应 RAG 能够灵活选择不同的检索策略,从而提高生成效率。
例如,对于简单且直接的查询,系统可能选择跳过检索步骤,直接生成答案;对于中等复杂度的查询,采用Single-shot RAG策略,通过一次检索就能获取足够的文档来支持生成;而对于高复杂度的查询,则使用Iterative RAG策略,通过多轮检索逐步细化答案,确保覆盖所有相关的信息。
其架构图如下:
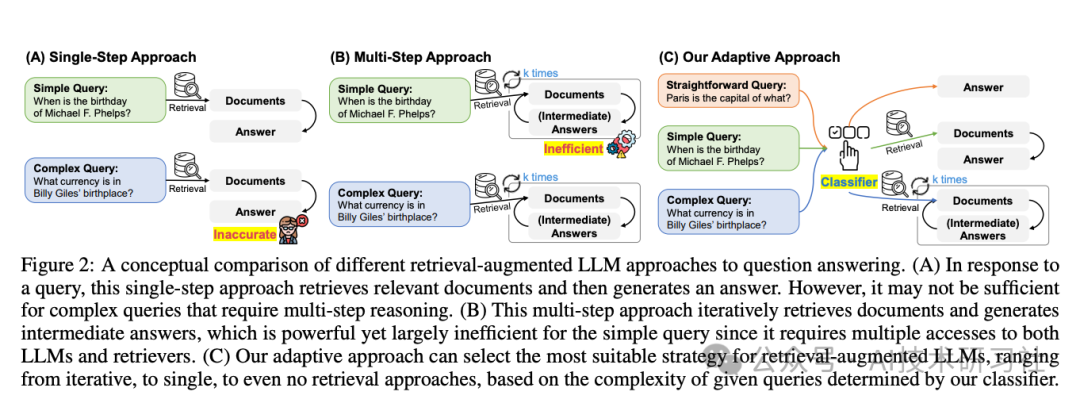
① 单步方法(Single-Step Approach)
简单查询:例如“迈克尔·菲尔普斯的生日是什么时候?”,系统会直接检索相关文档,并生成答案。这种方法在处理简单查询时通常能够准确回答。
复杂查询:例如“比利·吉列斯的出生地使用什么货币?”,在处理复杂查询时,由于仅进行一次检索,结果往往不够准确。
② 多步方法(Multi-Step Approach)
简单查询:尽管像“迈克尔·菲尔普斯的生日是什么时候?”这样简单的查询,系统仍会进行多轮检索和推理,最终生成答案。这导致了不必要的计算开销,使得过程显得低效。
复杂查询:对于复杂的问题,如“比利·吉列斯的出生地使用什么货币?”,系统会进行多轮检索和推理,逐步生成中间答案。这种方法有助于提高复杂查询的准确性。
③ 自适应方法(Our Adaptive Approach)
查询分类:引入了一个分类器,用于根据查询的复杂度选择合适的处理方式。
直接查询:例如“巴黎是哪个国家的首都?”,分类器判断为直接回答问题,系统可直接生成答案。
简单查询:例如“迈克尔·菲尔普斯的生日是什么时候?”,分类器判断为简单查询,系统进行单次检索,并生成答案。
复杂查询:例如“比利·吉列斯的出生地使用什么货币?”,分类器判断为复杂问题,系统进行多轮检索和推理,最终生成答案。

自我纠正机制是自适应 RAG 的另一个核心特性。在生成过程中,系统会根据文档的相关性和生成的初步结果进行自我评估。如果发现生成的答案存在不准确或不充分的情况,系统会主动调整检索策略,可能通过重新查询或者扩展检索范围来获取更多支持性的文档。这种循环式的自我调整不仅提高了最终答案的可靠性,还能够适应数据动态变化的情况。
在应用场景上,自适应 RAG 适用于需要高精度和灵活性的任务,如医疗诊断、法律分析和市场研究等。这些领域通常包含大量的复杂文档和不确定的信息来源,自适应 RAG 能够在这些场景中动态调整检索和生成策略,从而提供准确且上下文相关的回答。
此外,自适应 RAG 也适用于需要处理实时数据变化的情况,如新闻报道和社会舆情监测,因为其动态调整机制可以帮助模型更好地应对新信息的出现。
LangChain项目核心代码介绍:
from langchain.schema import Document
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def llm_fallback(state):
"""
Generate answer using the LLM w/o vectorstore
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---LLM Fallback---")
question = state["question"]
generation = llm_chain.invoke({"question": question})
return {"question": question, "generation": generation}
def generate(state):
"""
Generate answer using the vectorstore
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
if not isinstance(documents, list):
documents = [documents]
# RAG generation
generation = rag_chain.invoke({"documents": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---WEB SEARCH---")
question = state["question"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
return {"documents": web_results, "question": question}
### Edges ###
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
# Fallback to LLM or raise error if no decision
if "tool_calls" not in source.additional_kwargs:
print("---ROUTE QUESTION TO LLM---")
return "llm_fallback"
if len(source.additional_kwargs["tool_calls"]) == 0:
raise "Router could not decide source"
# Choose datasource
datasource = source.additional_kwargs["tool_calls"][0]["function"]["name"]
if datasource == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "web_search"
elif datasource == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
else:
print("---ROUTE QUESTION TO LLM---")
return "vectorstore"
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, WEB SEARCH---")
return "web_search"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
参考项目:https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_adaptive_rag_cohere.ipynb
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1471
1471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}