







CUDA入门系列课程,从最基础着手,突出的就是一个字“细”!!
github项目包含代码、博客、课件pdf下载地址:https://github.com/sangyc10/CUDA-code!
在这里插入图片描述
https://github.com/sangyc10/CUDA-code
CUDA入门

CUDA 概论
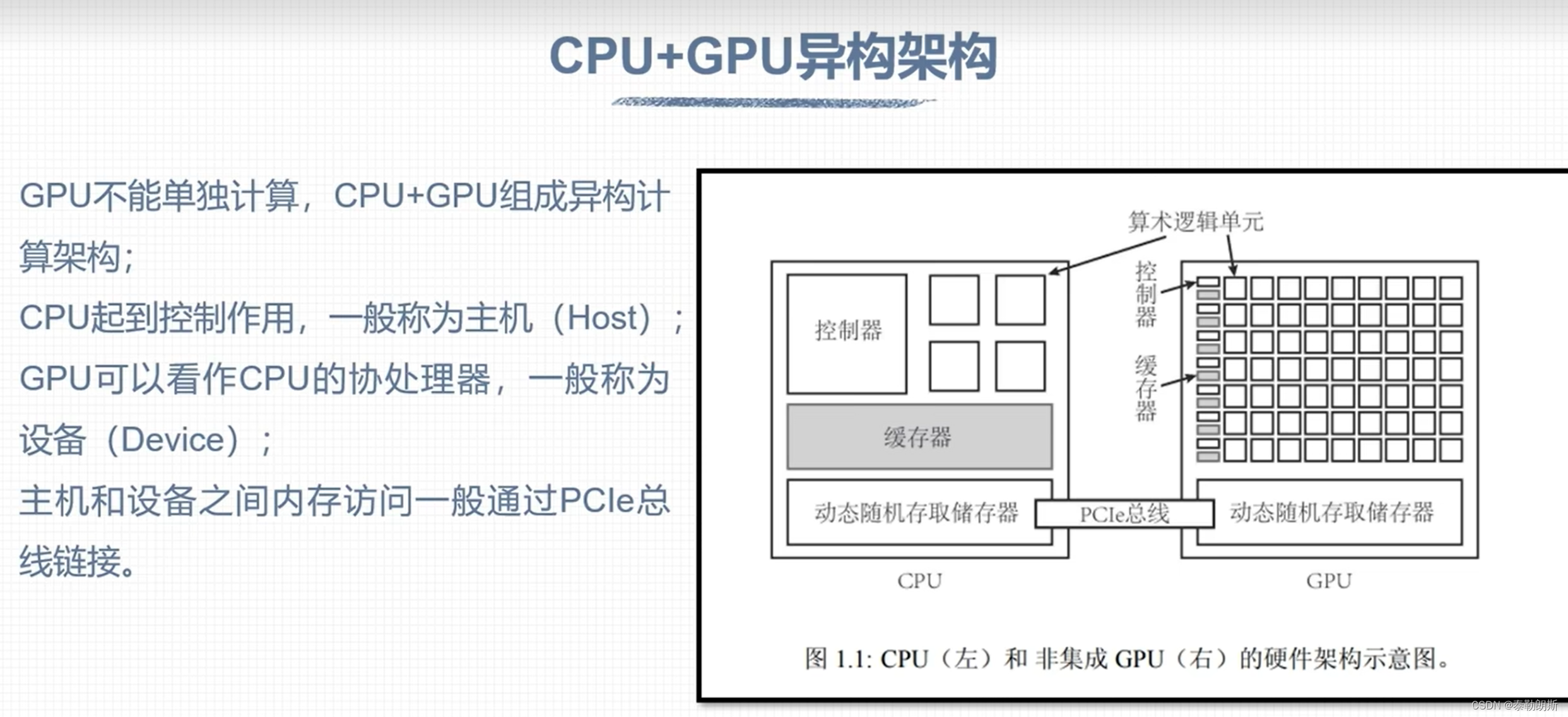

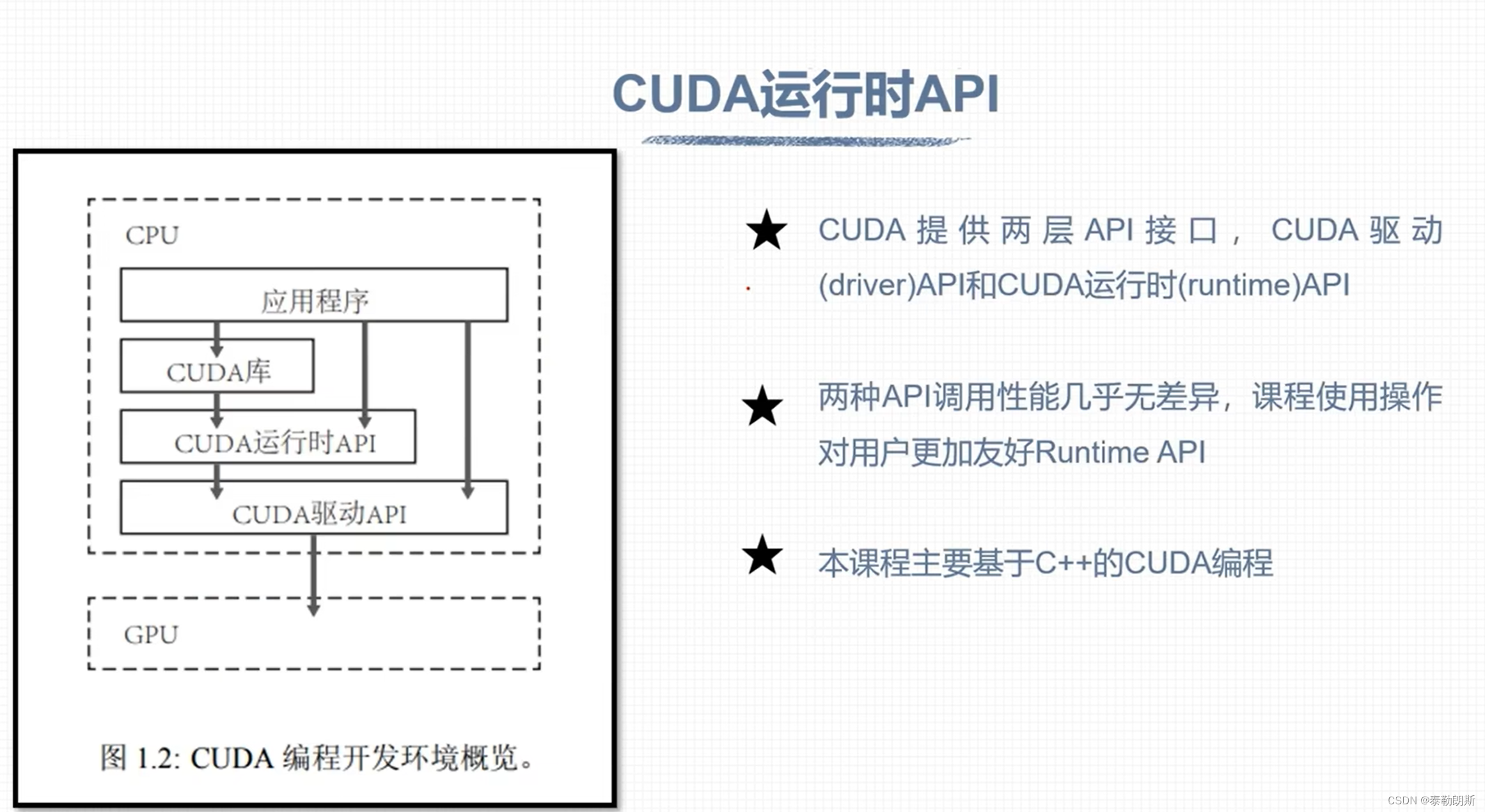
CUDA安装


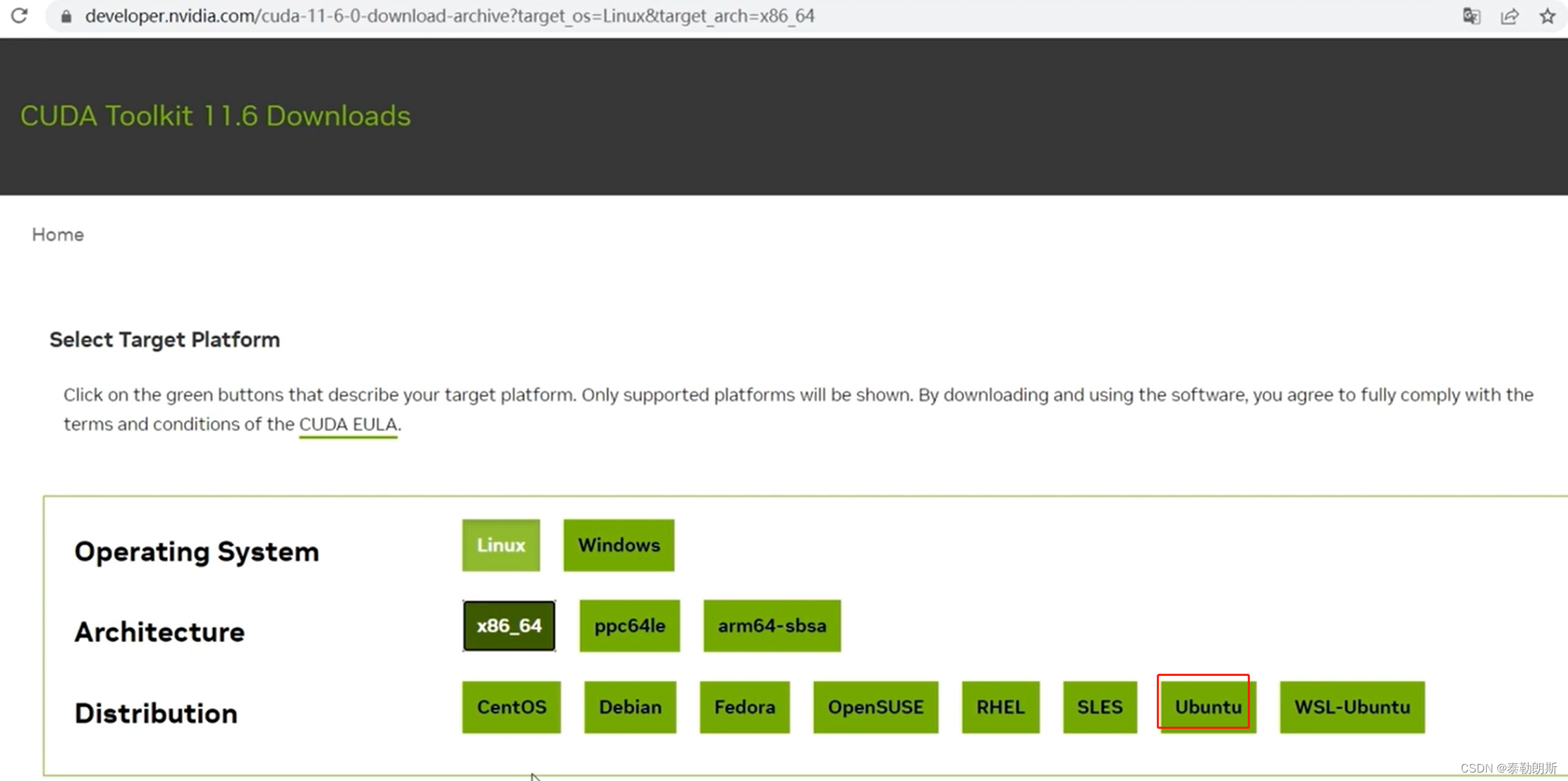

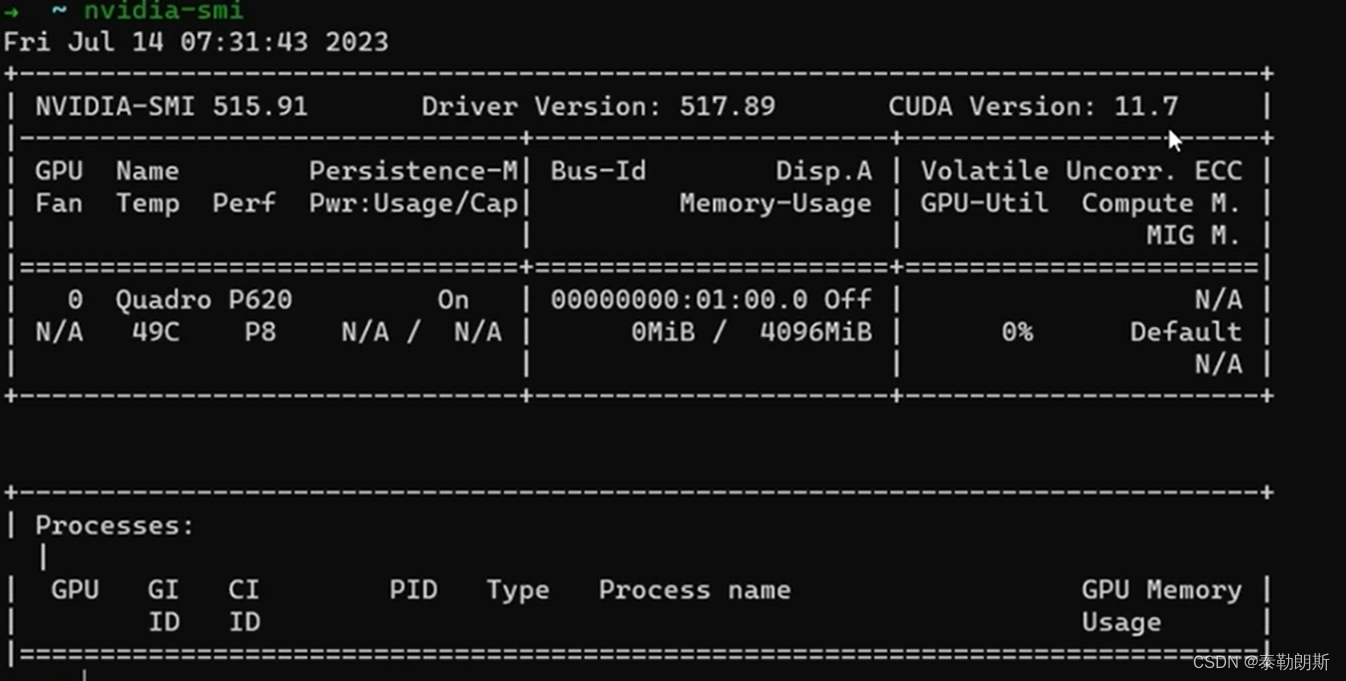
把上述命令依次执行就可以安装了,安装好执行:nvcc -V, nvidia-smi
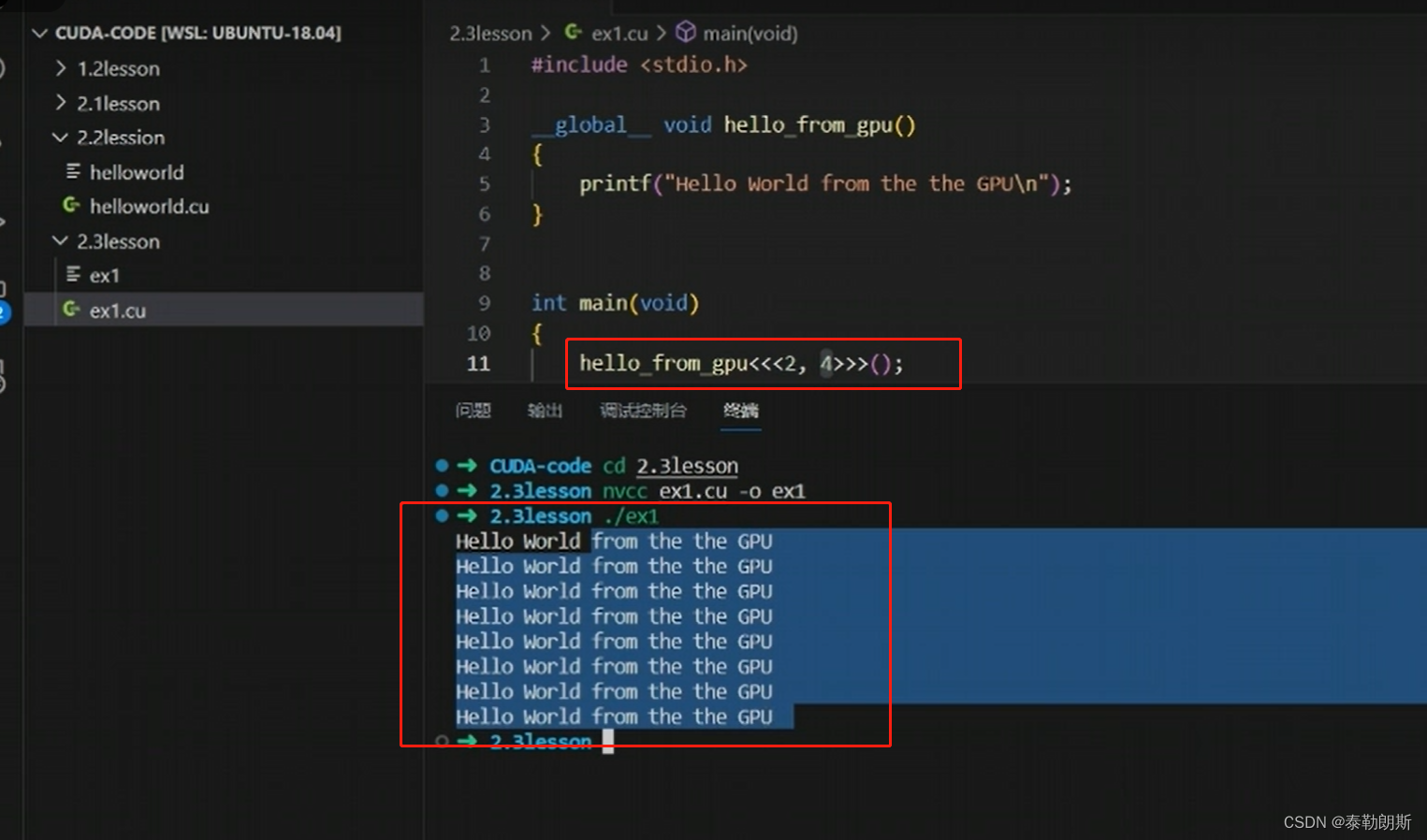
测试代码
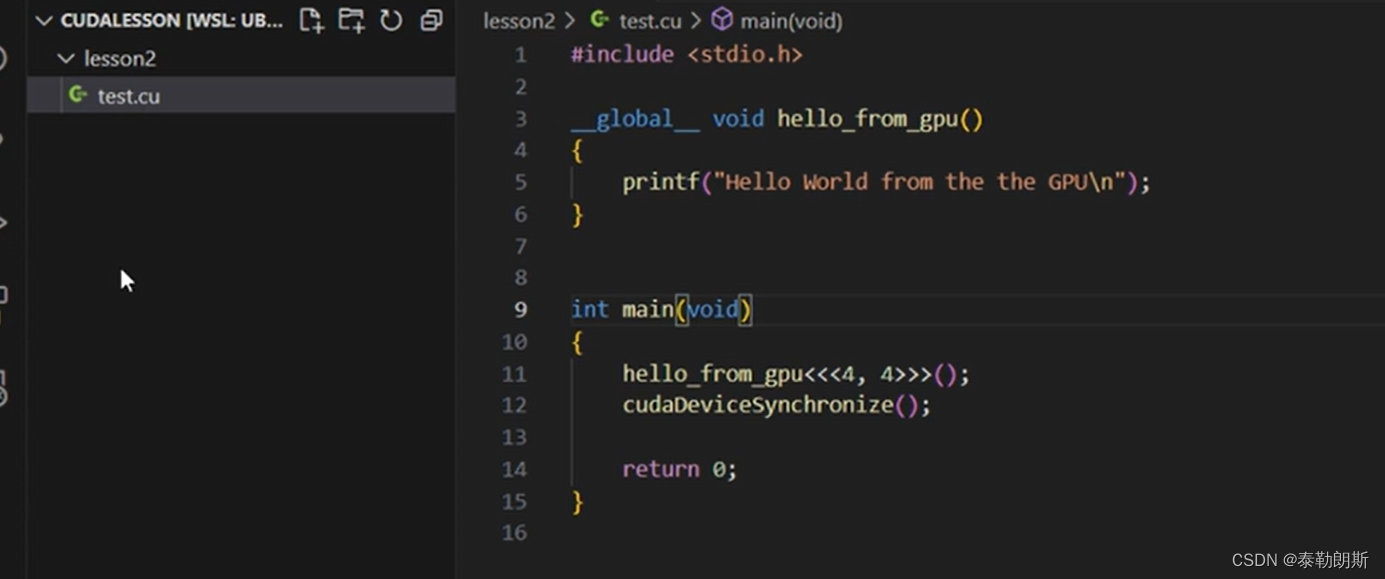
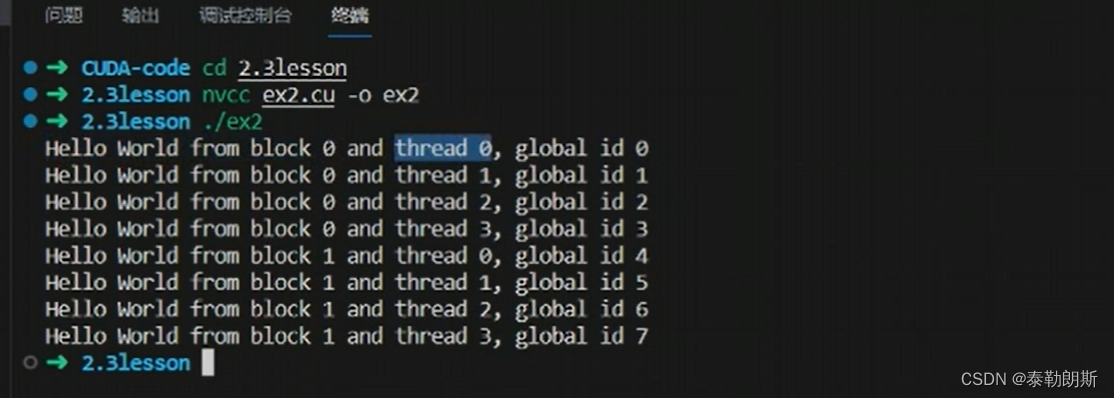
编译执行,
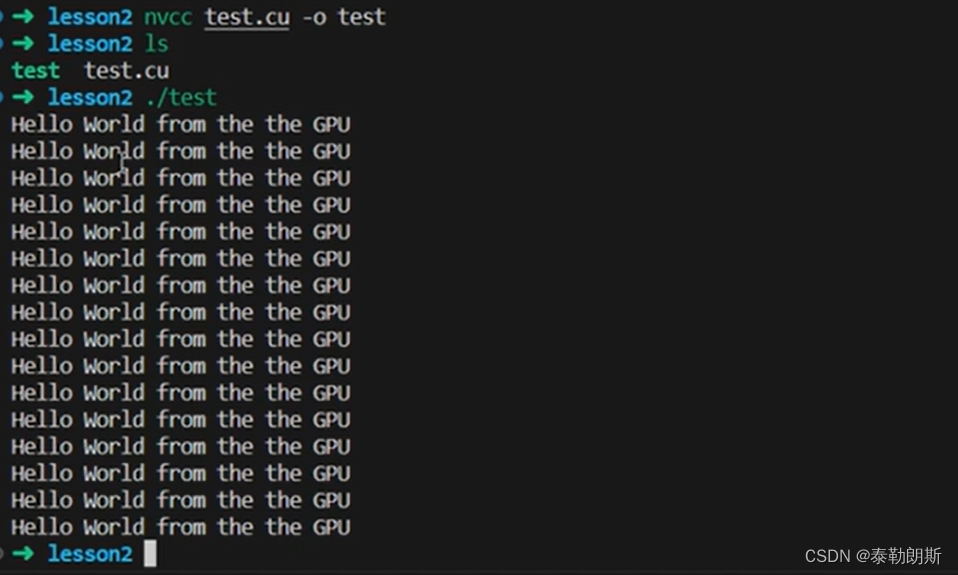
使用了4*4=16个线程,所以会打印16次
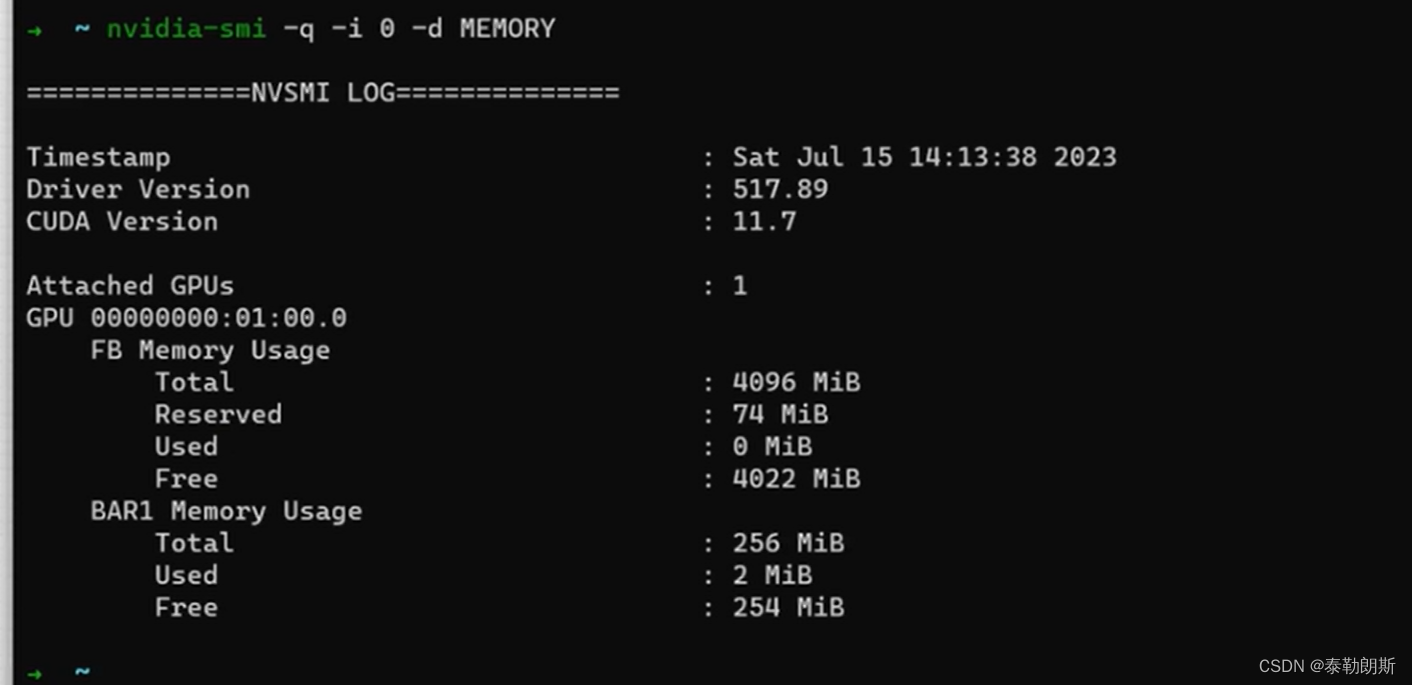
nvidia-smi 工具



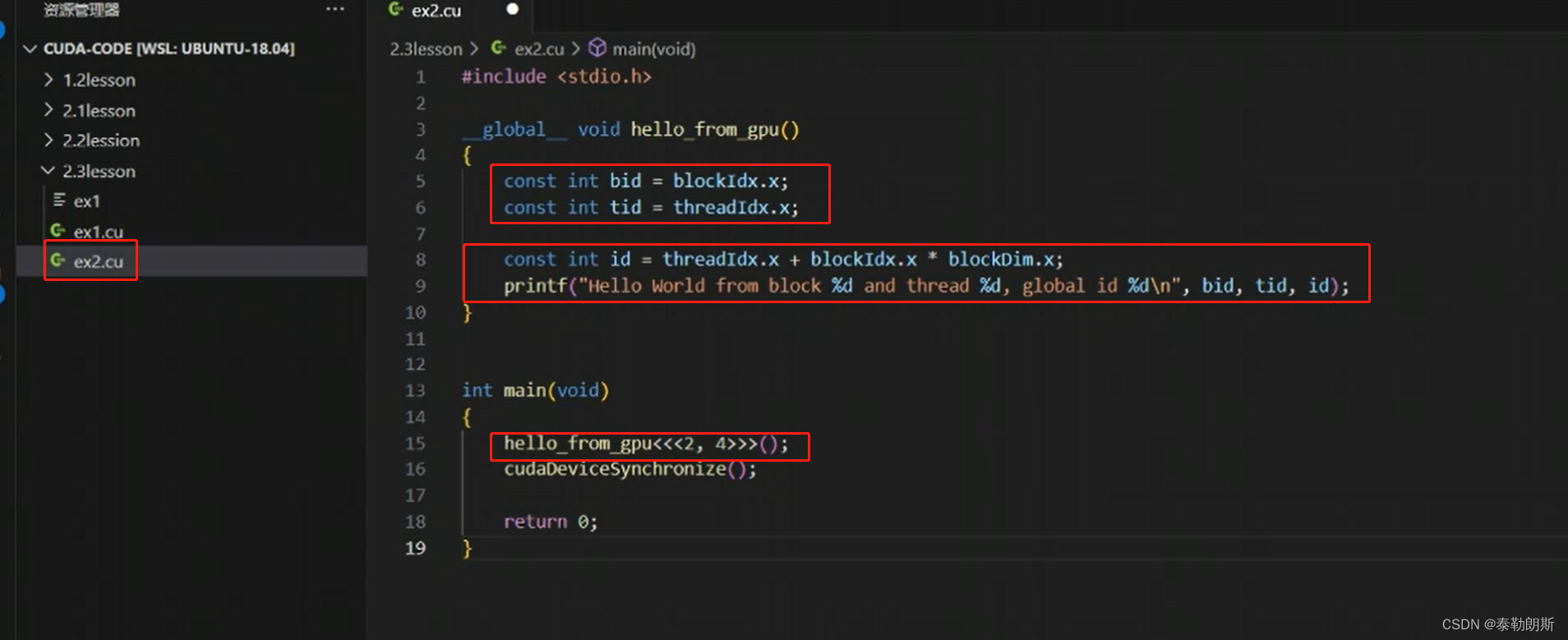
CUDA编程


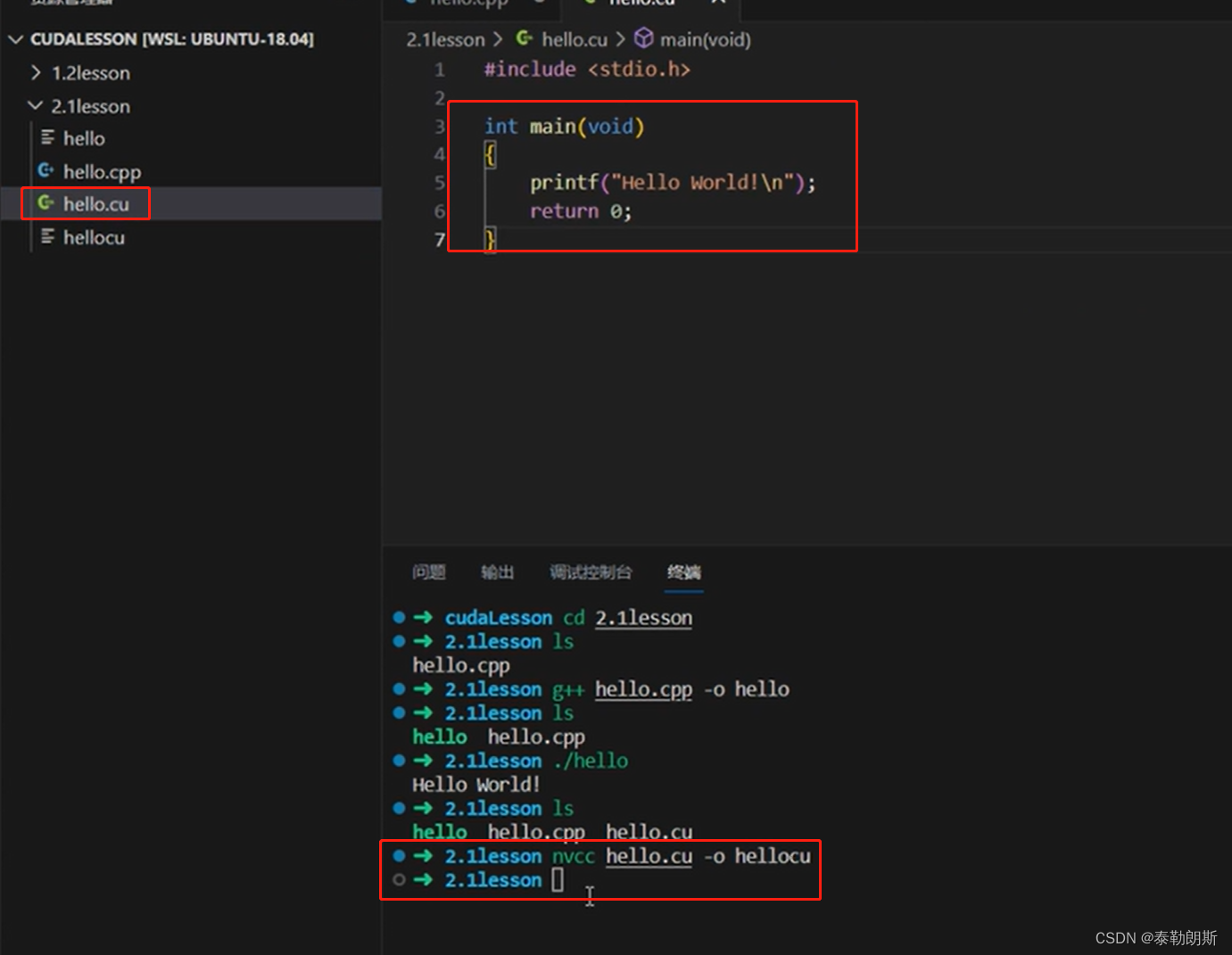



cudaDeviceSynchronize()是设备同步函数,等待核函数执行。
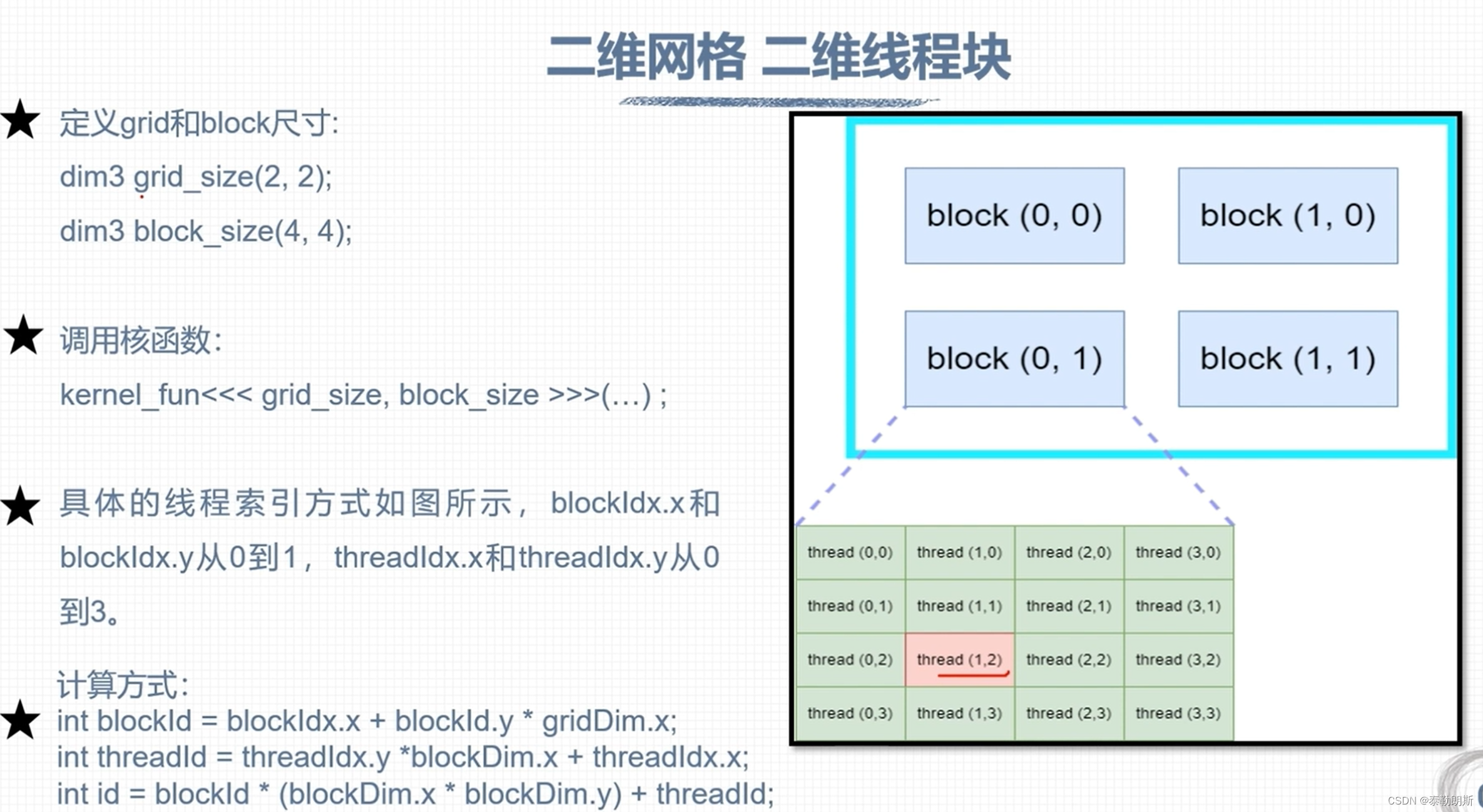
CUDA 线程模型

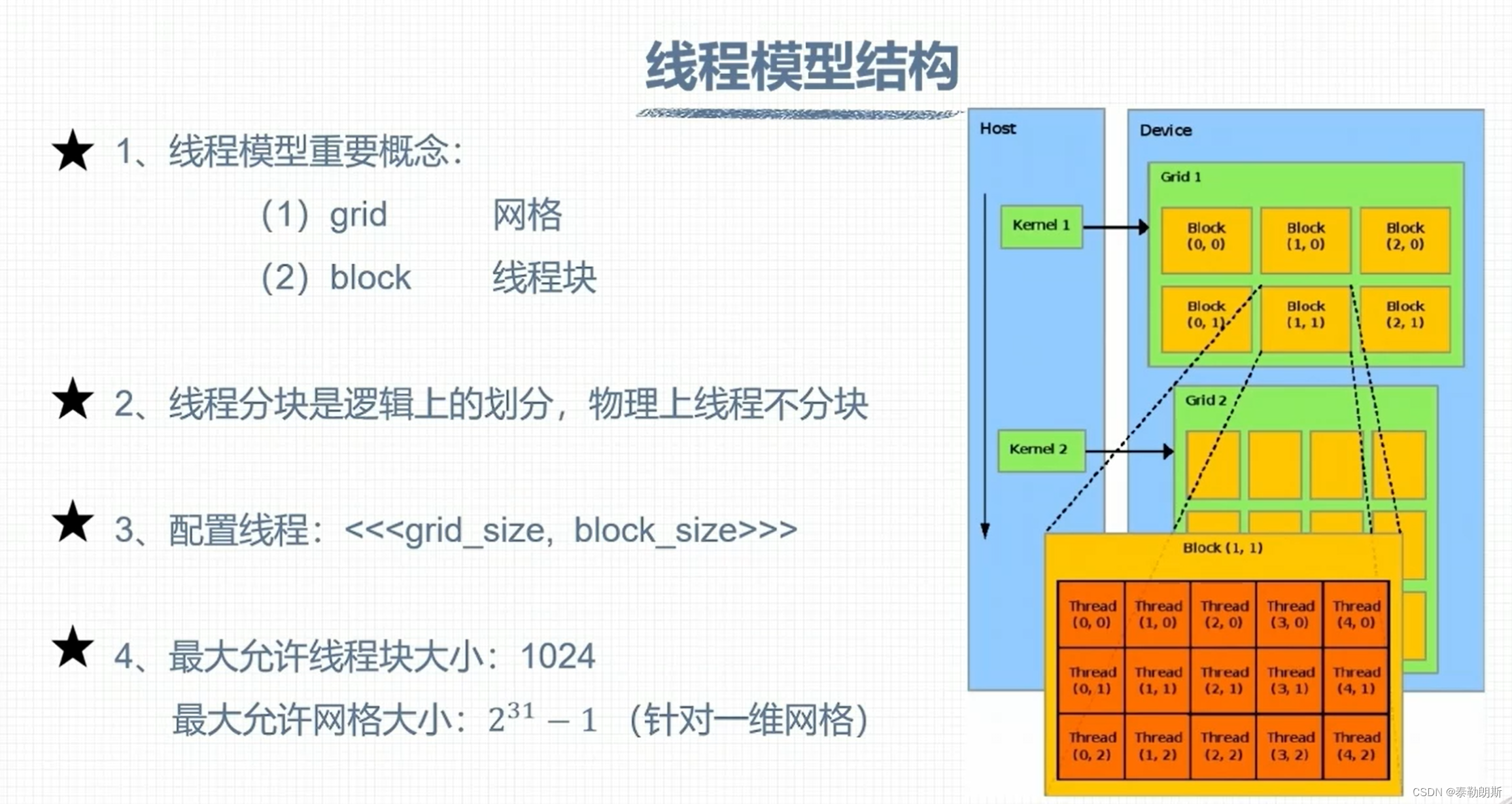

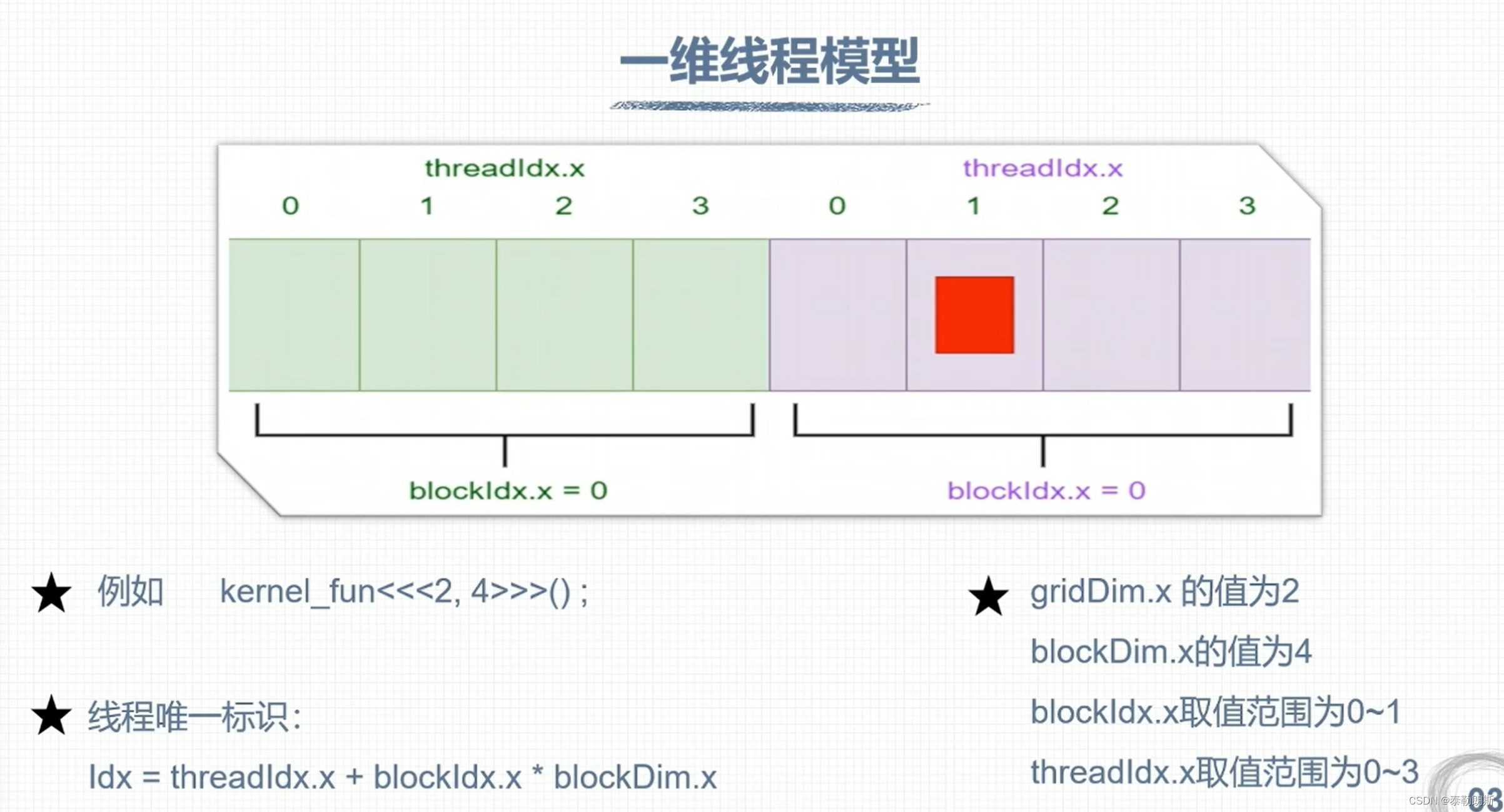




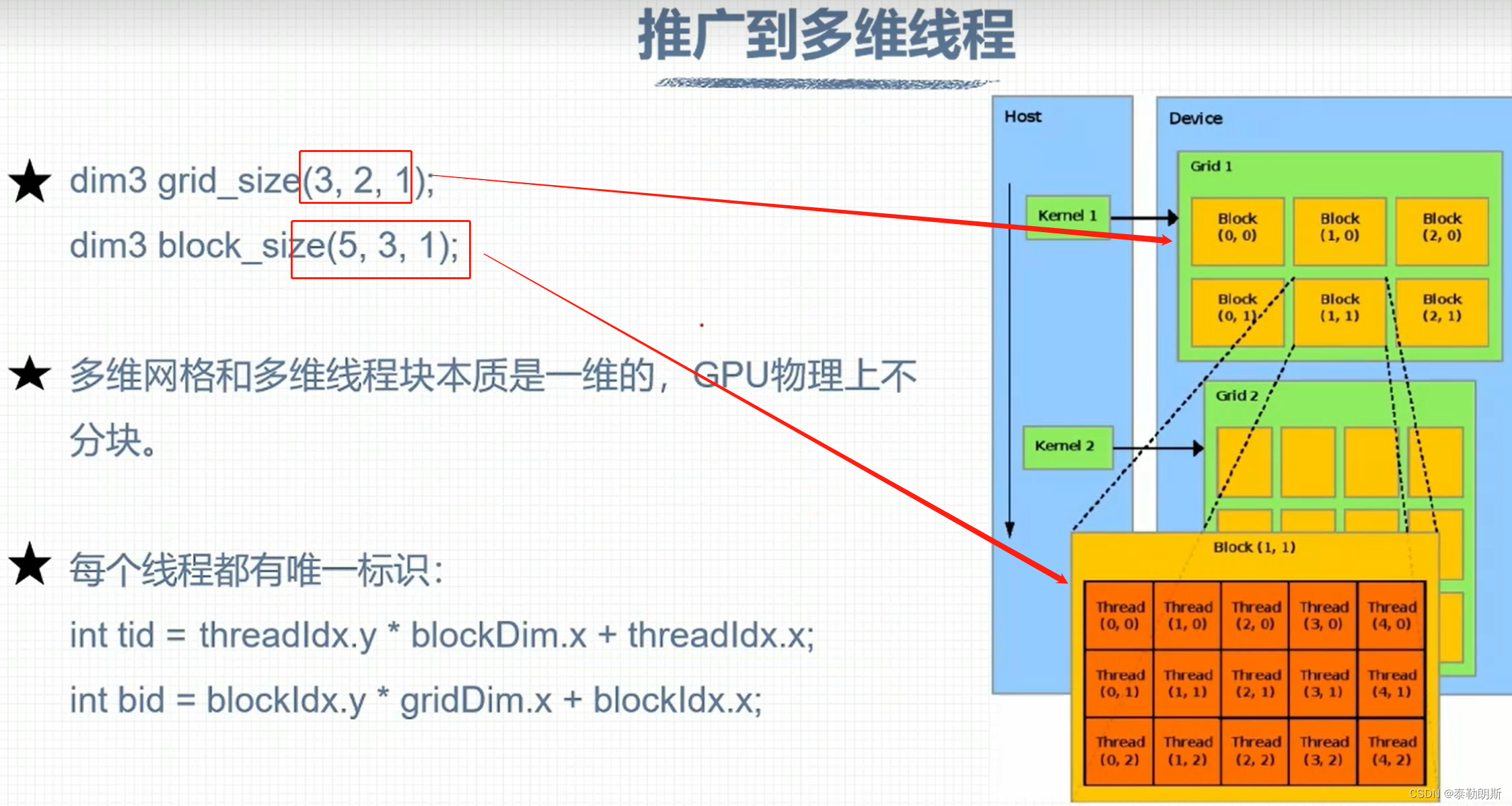
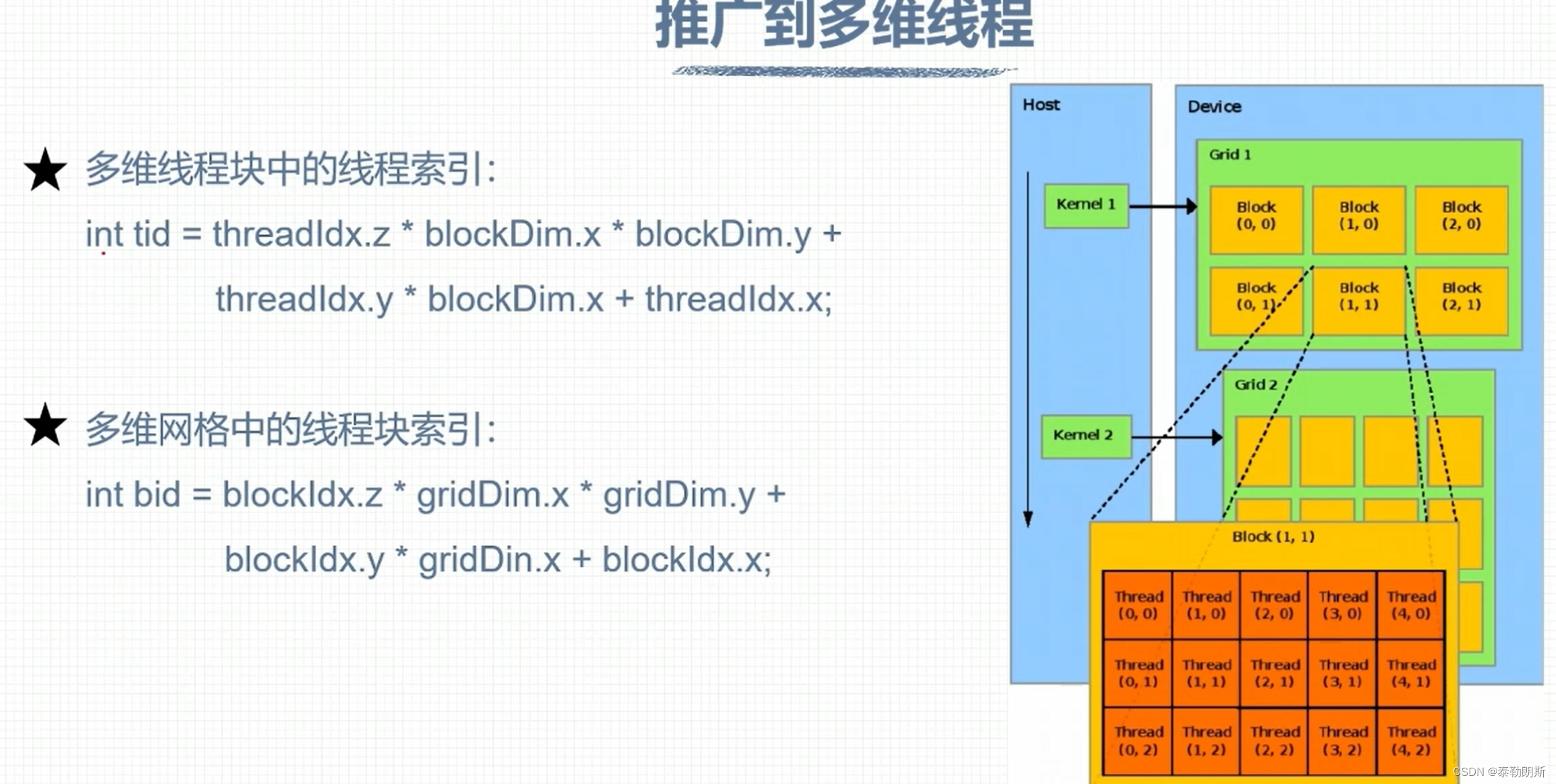

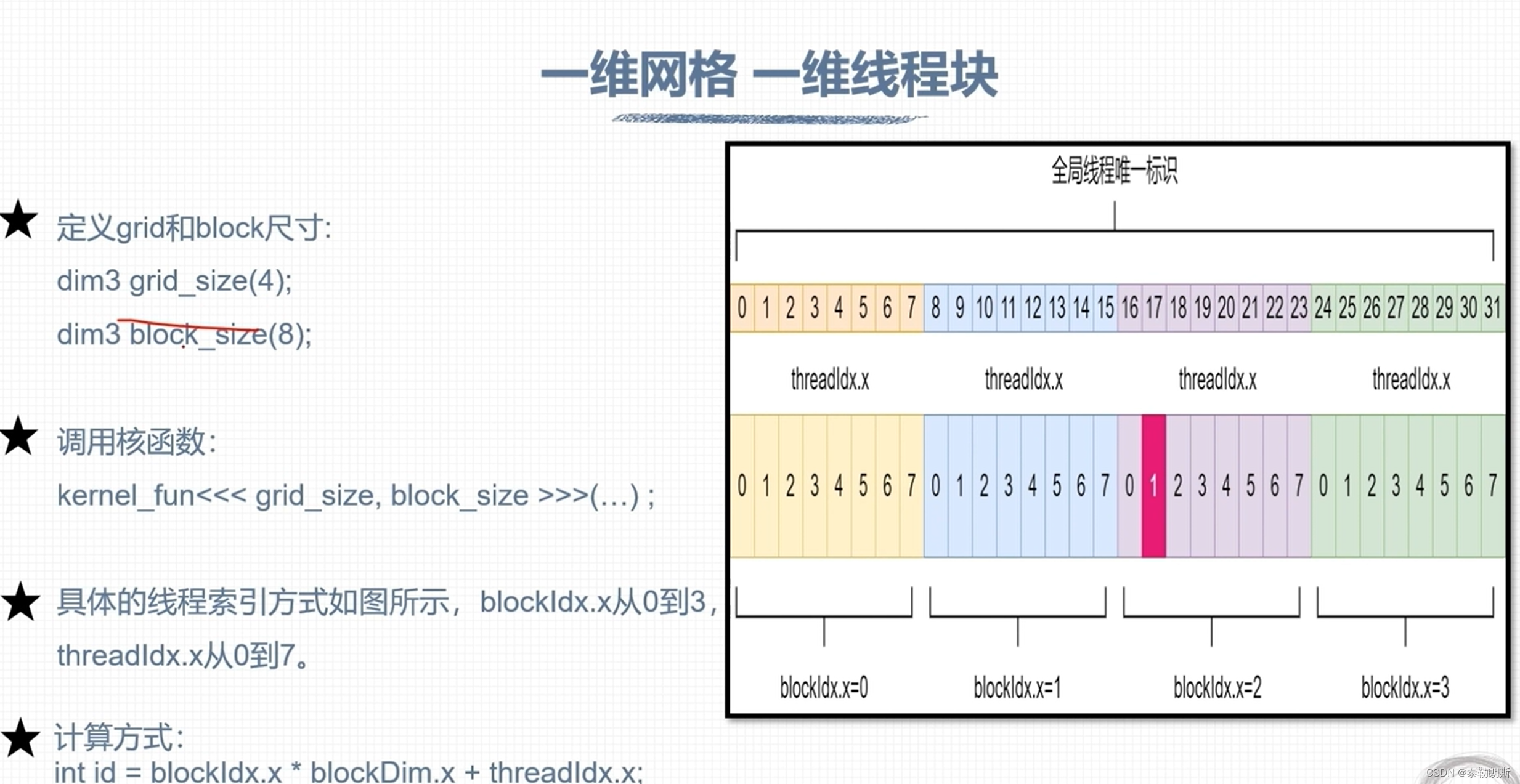
线程索引计算





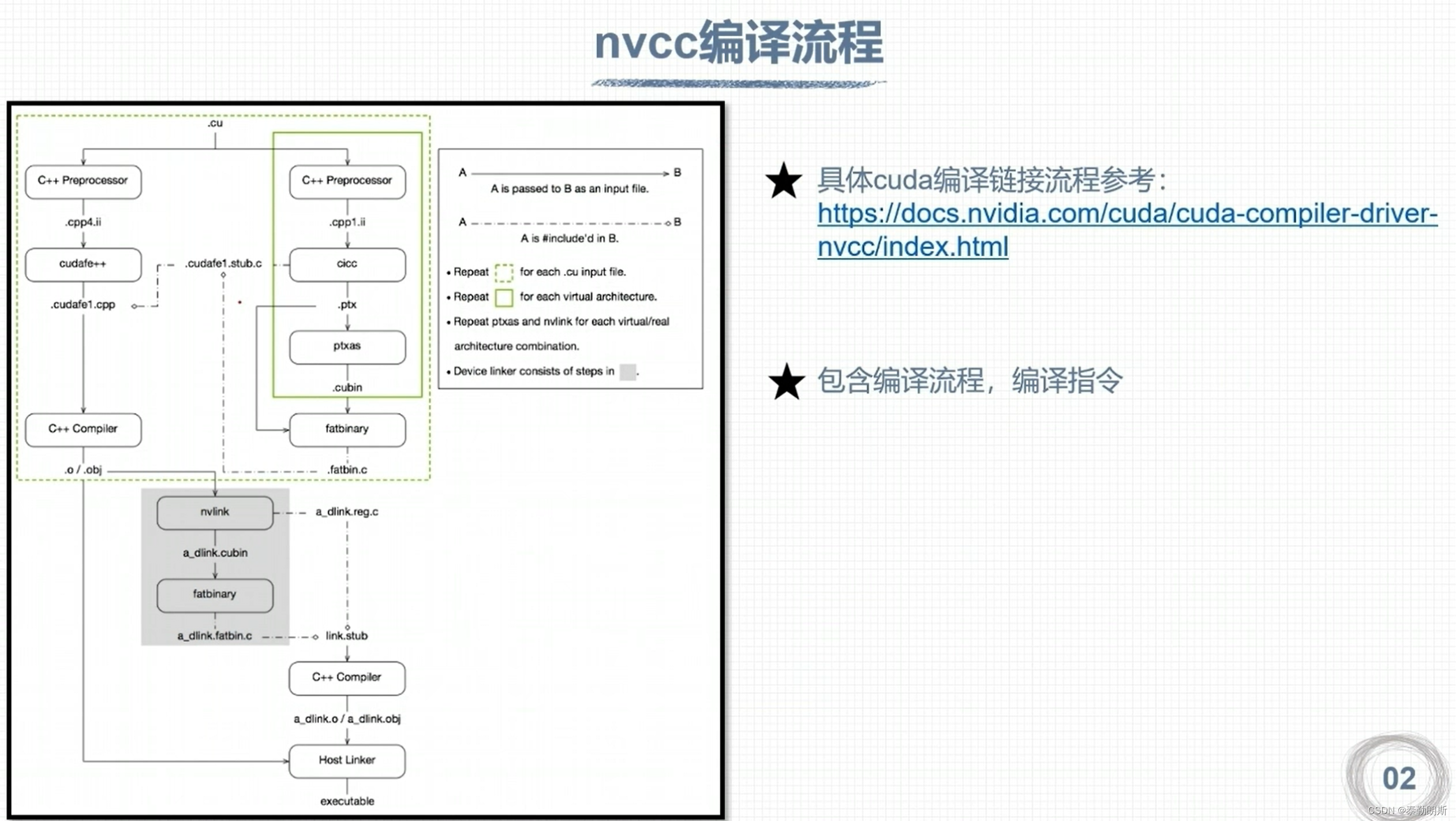
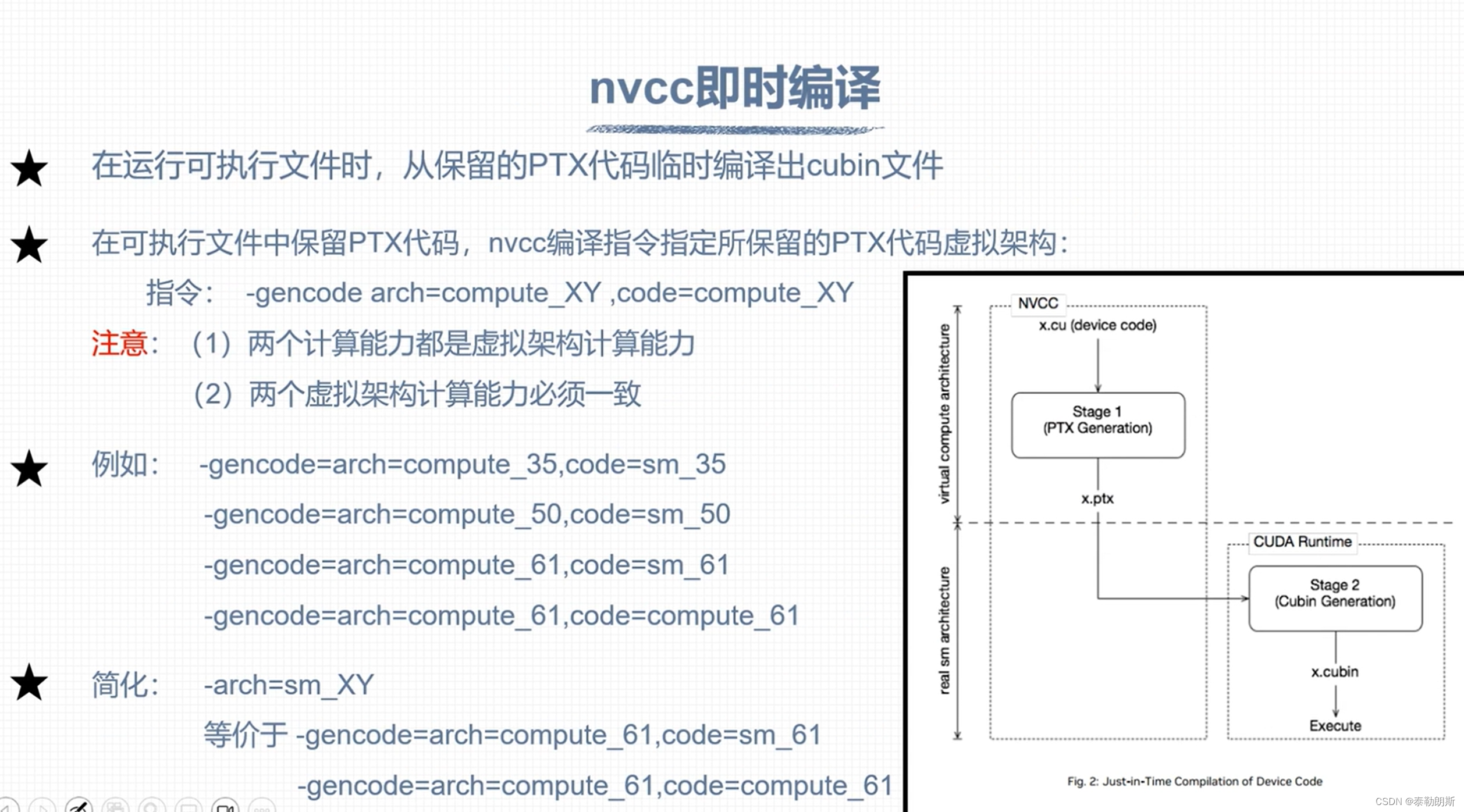
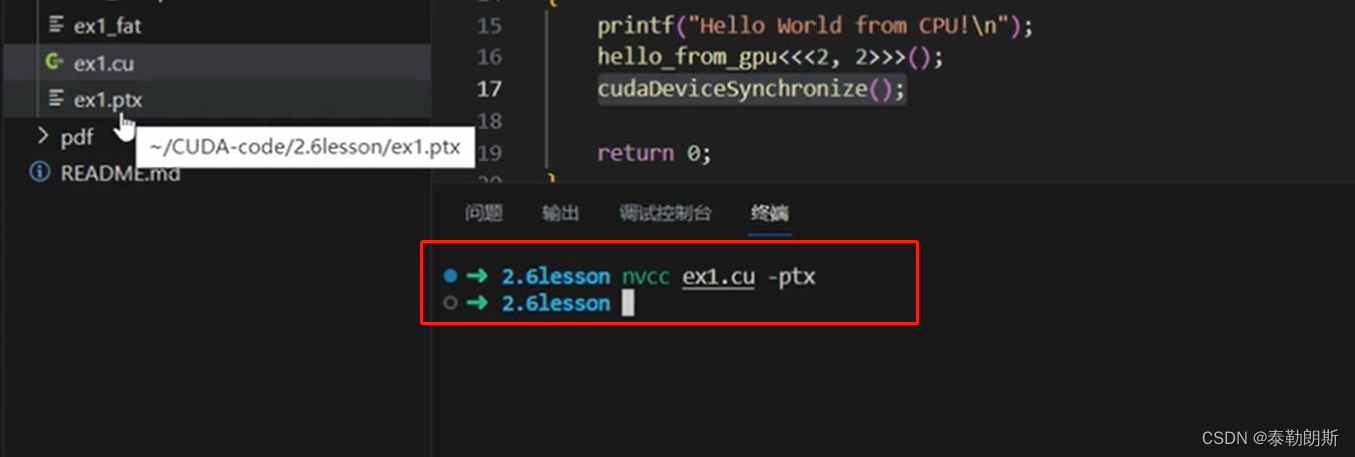
nvcc 编译流程和GPU计算能力



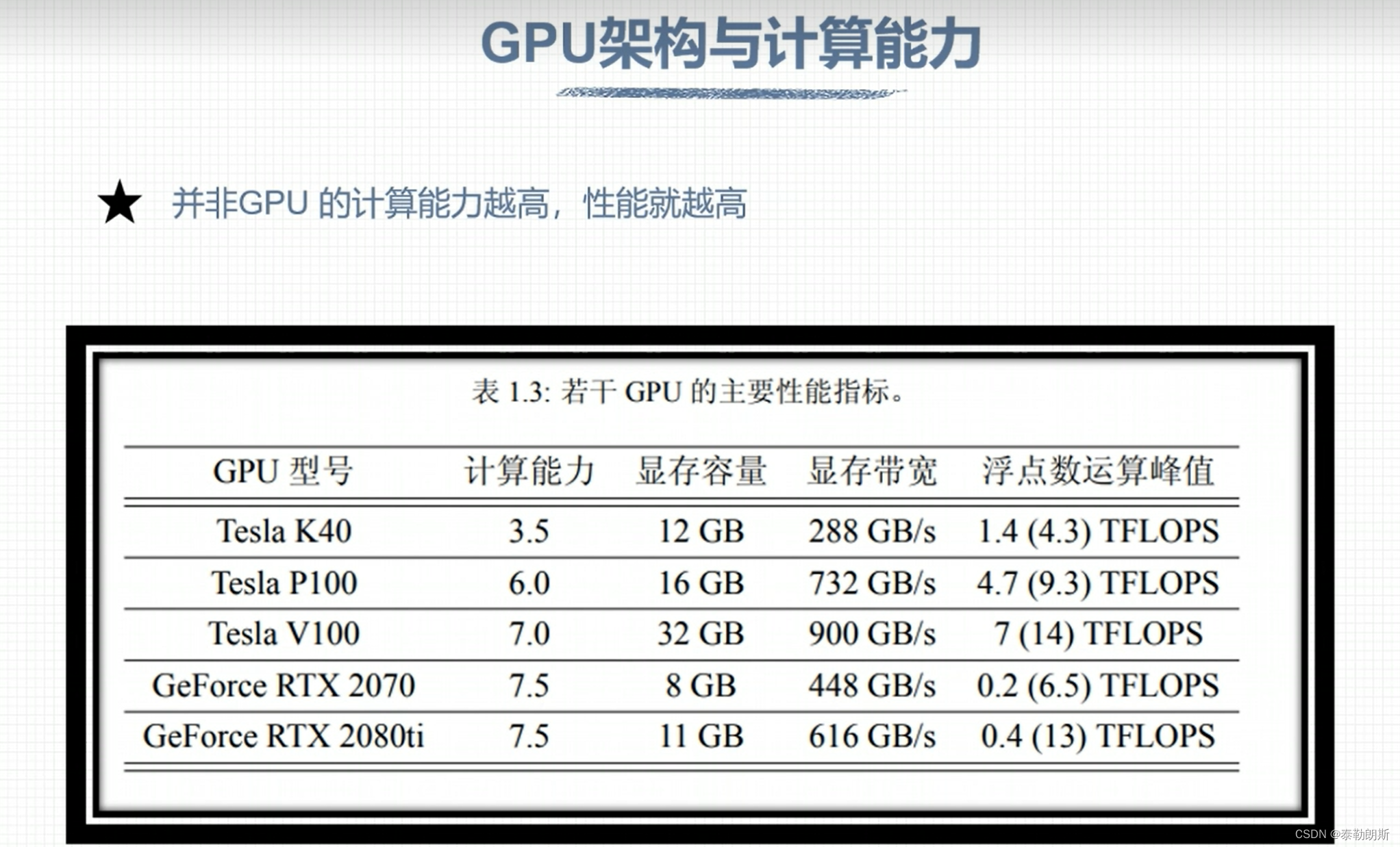
CUDA 程序兼容性问题


不要被下面的—误解了,应该是ppt的问题



CUDA 矩阵加法运算



注意上面函数前面的__host__ device



示例代码
/*********************************************************************************************
* file name : matrixSum1D_GPU.cu
* author : 权 双
* date : 2023-08-04
* brief : 矩阵求和程序,通过调用核函数在GPU执行
***********************************************************************************************/
#include <stdio.h>
#include "../tools/common.cuh"
__global__ void addFromGPU(float *A, float *B, float *C, const int N)
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
const int id = tid + bid * blockDim.x;
C[id] = A[id] + B[id];
}
void initialData(float *addr, int elemCount)
{
for (int i = 0; i < elemCount; i++)
{
addr[i] = (float)(rand() & 0xFF) / 10.f;
}
return;
}
int main(void)
{
// 1、设置GPU设备
setGPU();
// 2、分配主机内存和设备内存,并初始化
int iElemCount = 512; // 设置元素数量
size_t stBytesCount = iElemCount * sizeof(float); // 字节数
// (1)分配主机内存,并初始化
float *fpHost_A, *fpHost_B, *fpHost_C;
fpHost_A = (float *)malloc(stBytesCount);
fpHost_B = (float *)malloc(stBytesCount);
fpHost_C = (float *)malloc(stBytesCount);
if (fpHost_A != NULL && fpHost_B != NULL && fpHost_C != NULL)
{
memset(fpHost_A, 0, stBytesCount); // 主机内存初始化为0
memset(fpHost_B, 0, stBytesCount);
memset(fpHost_C, 0, stBytesCount);
}
else
{
printf("Fail to allocate host memory!\n");
exit(-1);
}
// (2)分配设备内存,并初始化
float *fpDevice_A, *fpDevice_B, *fpDevice_C;
cudaMalloc((float**)&fpDevice_A, stBytesCount);
cudaMalloc((float**)&fpDevice_B, stBytesCount);
cudaMalloc((float**)&fpDevice_C, stBytesCount);
if (fpDevice_A != NULL && fpDevice_B != NULL && fpDevice_C != NULL)
{
cudaMemset(fpDevice_A, 0, stBytesCount); // 设备内存初始化为0
cudaMemset(fpDevice_B, 0, stBytesCount);
cudaMemset(fpDevice_C, 0, stBytesCount);
}
else
{
printf("fail to allocate memory\n");
free(fpHost_A);
free(fpHost_B);
free(fpHost_C);
exit(-1);
}
// 3、初始化主机中数据
srand(666); // 设置随机种子
initialData(fpHost_A, iElemCount);
initialData(fpHost_B, iElemCount);
// 4、数据从主机复制到设备
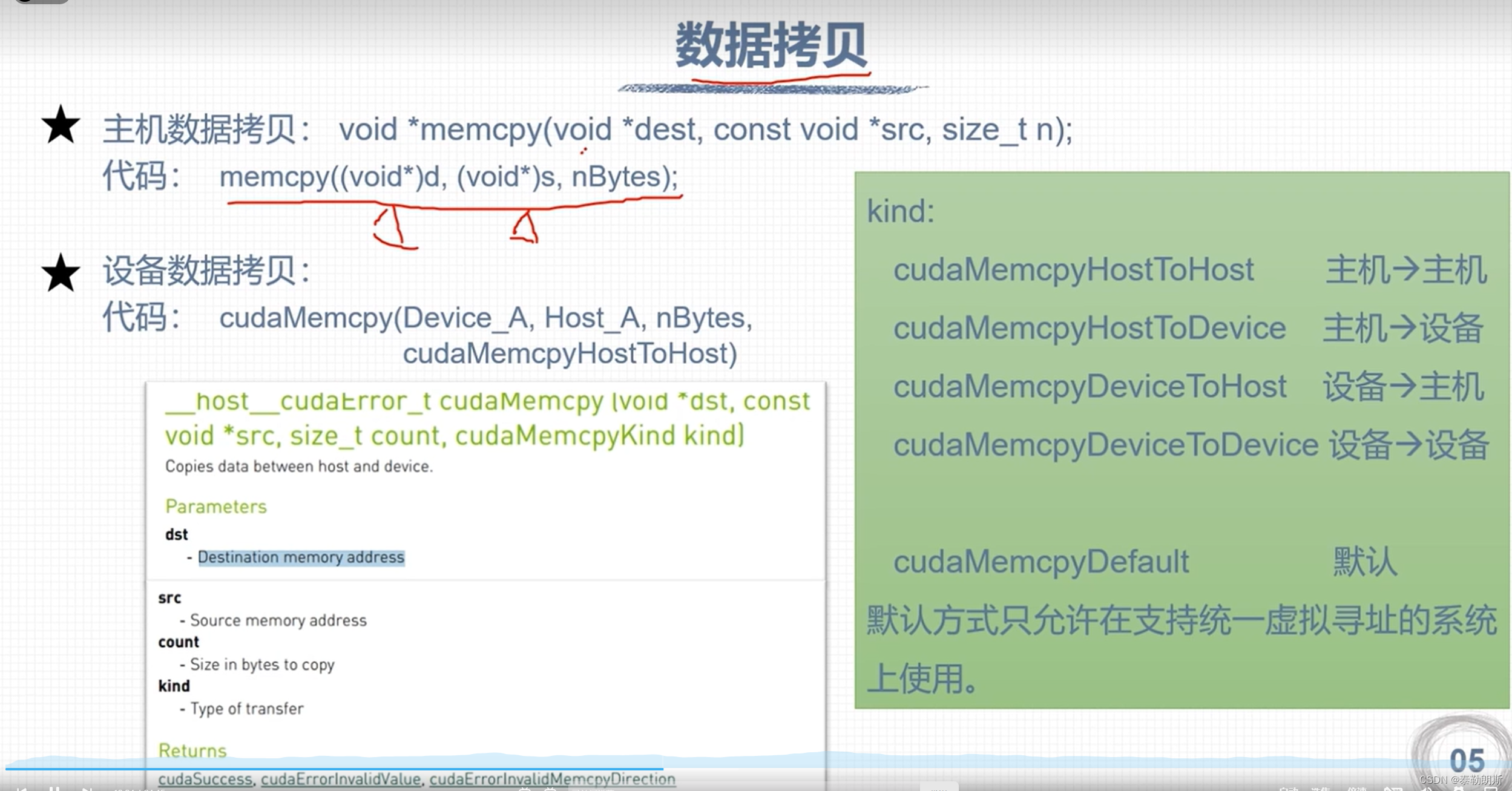
cudaMemcpy(fpDevice_A, fpHost_A, stBytesCount, cudaMemcpyHostToDevice);
cudaMemcpy(fpDevice_B, fpHost_B, stBytesCount, cudaMemcpyHostToDevice);
cudaMemcpy(fpDevice_C, fpHost_C, stBytesCount, cudaMemcpyHostToDevice);
// 5、调用核函数在设备中进行计算
dim3 block(32);
dim3 grid(iElemCount / 32);
addFromGPU<<<grid, block>>>(fpDevice_A, fpDevice_B, fpDevice_C, iElemCount); // 调用核函数
// cudaDeviceSynchronize();
// 6、将计算得到的数据从设备传给主机
cudaMemcpy(fpHost_C, fpDevice_C, stBytesCount, cudaMemcpyDeviceToHost);
for (int i = 0; i < 10; i++) // 打印
{
printf("idx=%2d\tmatrix_A:%.2f\tmatrix_B:%.2f\tresult=%.2f\n", i+1, fpHost_A[i], fpHost_B[i], fpHost_C[i]);
}
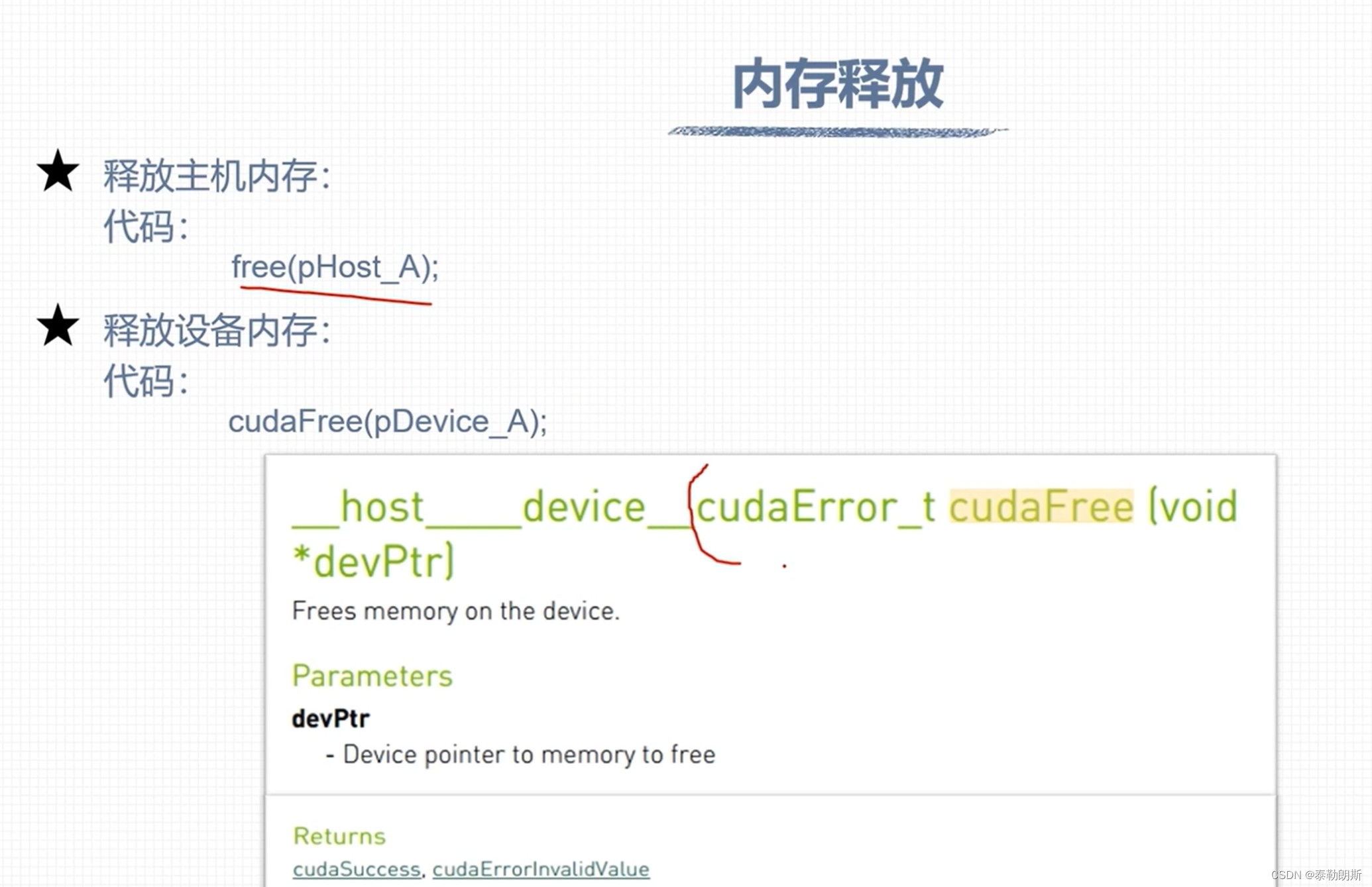
// 7、释放主机与设备内存
free(fpHost_A);
free(fpHost_B);
free(fpHost_C);
cudaFree(fpDevice_A);
cudaFree(fpDevice_B);
cudaFree(fpDevice_C);
cudaDeviceReset();
return 0;
}


__device__ float add(const float x, const float y)
{
return x + y;
}
__global__ void addFromGPU(float *A, float *B, float *C, const int N)
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
const int id = tid + bid * blockDim.x; // 513 32*17=544
if (id >= N) return;
C[id] = add(A[id], B[id]);
}
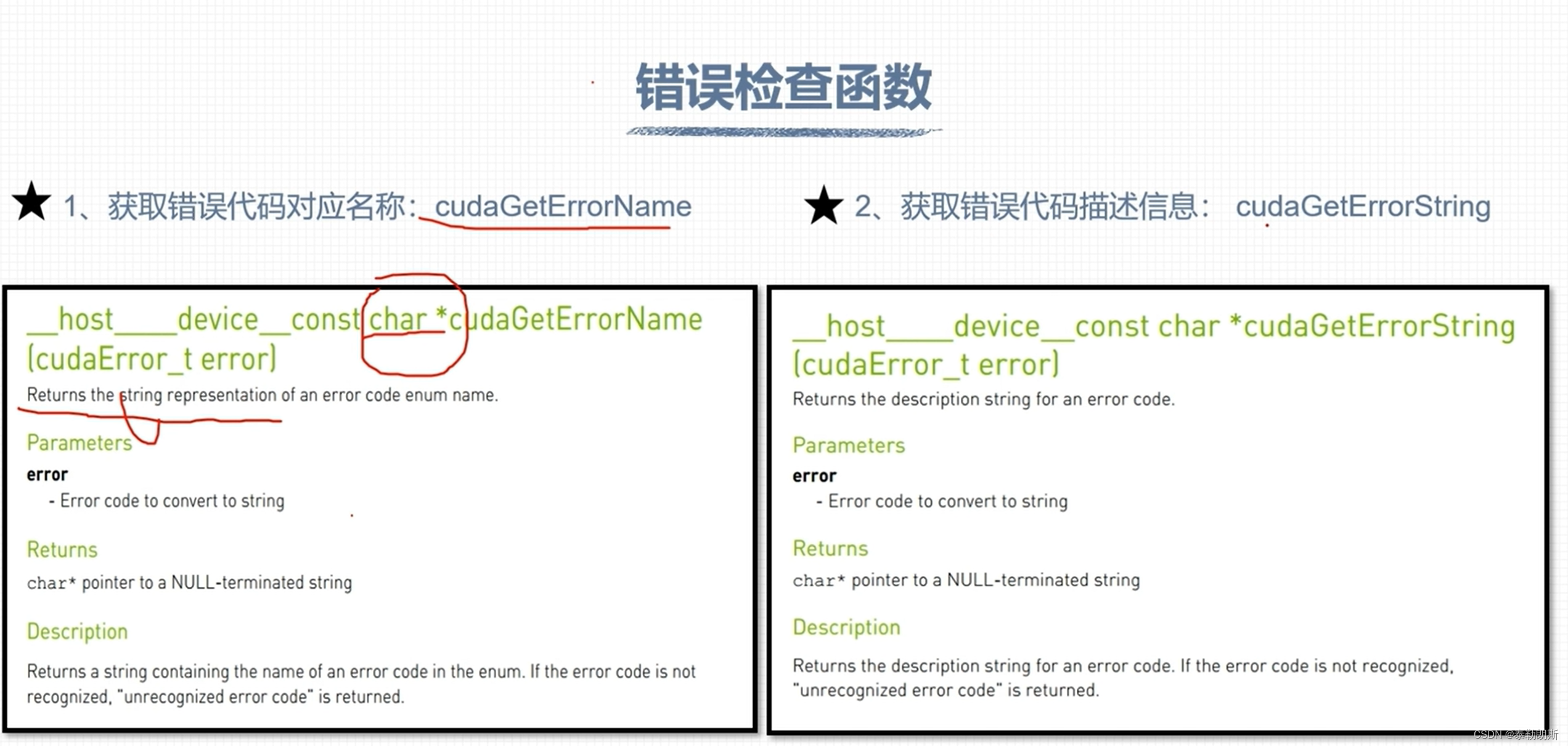
CUDA 错误检查


//common.cuh
#pragma once
#include <stdlib.h>
#include <stdio.h>
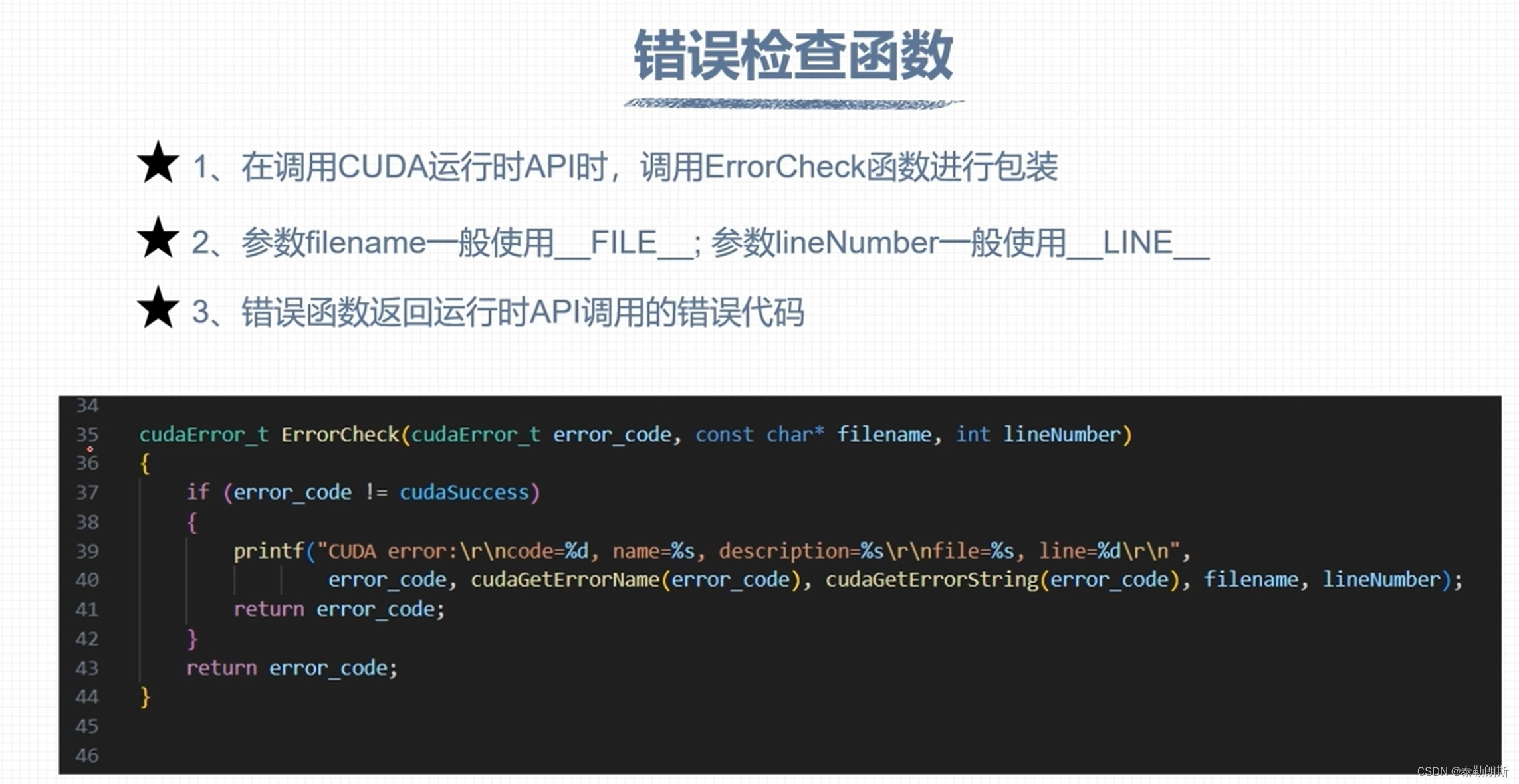
cudaError_t ErrorCheck(cudaError_t error_code, const char* filename, int lineNumber)
{
if (error_code != cudaSuccess)
{
printf("CUDA error:\r\ncode=%d, name=%s, description=%s\r\nfile=%s, line%d\r\n",
error_code, cudaGetErrorName(error_code), cudaGetErrorString(error_code), filename, lineNumber);
return error_code;
}
return error_code;
}
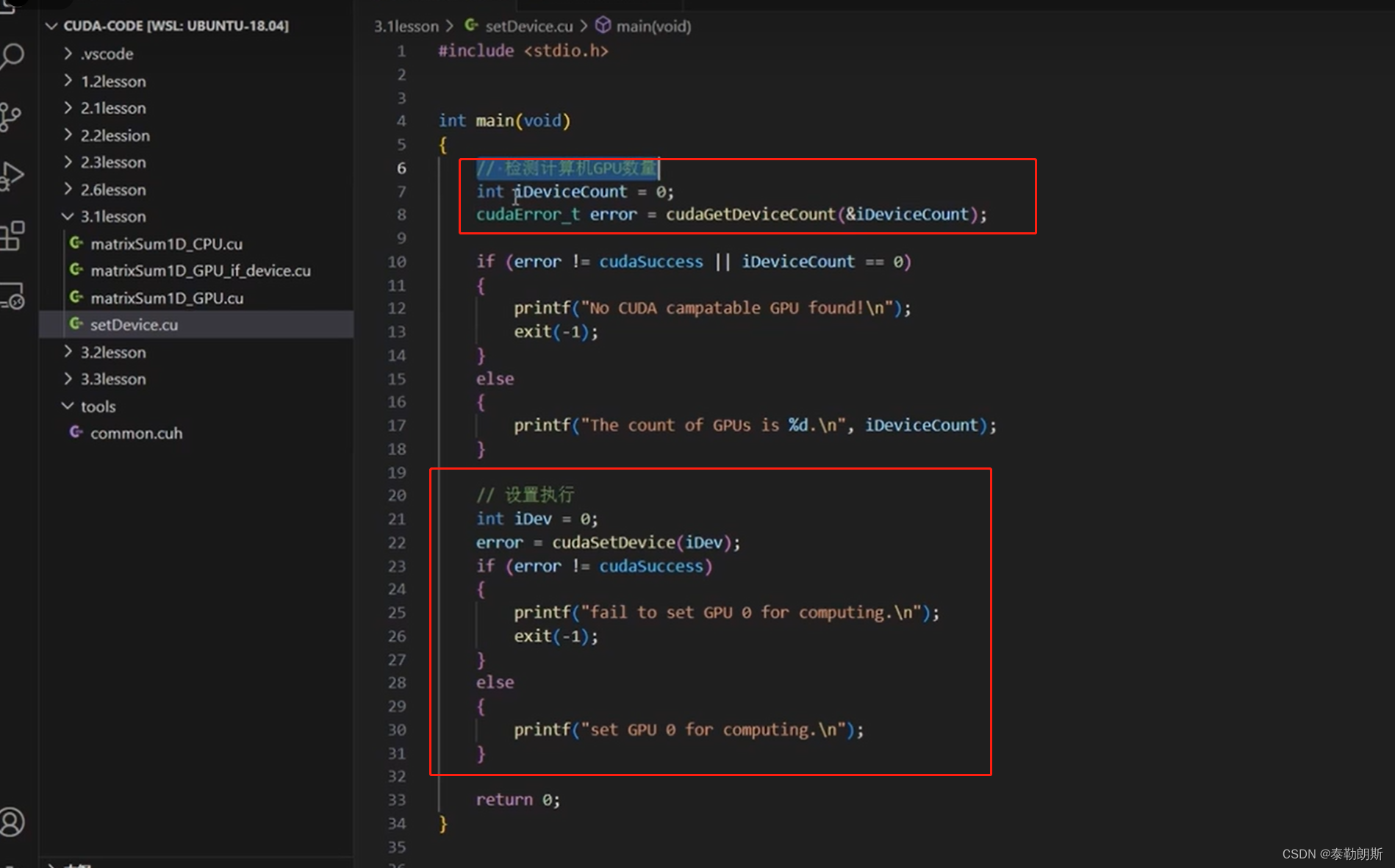
void setGPU()
{
// 检测计算机GPU数量
int iDeviceCount = 0;
cudaError_t error = ErrorCheck(cudaGetDeviceCount(&iDeviceCount), __FILE__, __LINE__);
if (error != cudaSuccess || iDeviceCount == 0)
{
printf("No CUDA campatable GPU found!\n");
exit(-1);
}
else
{
printf("The count of GPUs is %d.\n", iDeviceCount);
}
// 设置执行
int iDev = 0;
error = ErrorCheck(cudaSetDevice(iDev), __FILE__, __LINE__);
if (error != cudaSuccess)
{
printf("fail to set GPU 0 for computing.\n");
exit(-1);
}
else
{
printf("set GPU 0 for computing.\n");
}
}
下面是错误检测代码
#include <stdio.h>
#include "../tools/common.cuh"
int main(void)
{
// 1、分配主机内存,并初始化
float *fpHost_A;
fpHost_A = (float *)malloc(4);
memset(fpHost_A, 0, 4); // 主机内存初始化为0
float *fpDevice_A;
cudaError_t error = ErrorCheck(cudaMalloc((float**)&fpDevice_A, 4), __FILE__, __LINE__);
cudaMemset(fpDevice_A, 0, 4); // 设备内存初始化为0
// 2、数据从主机复制到设备
ErrorCheck(cudaMemcpy(fpDevice_A, fpHost_A, 4, cudaMemcpyDeviceToHost), __FILE__, __LINE__);
// 3、释放主机与设备内存
free(fpHost_A);
ErrorCheck(cudaFree(fpDevice_A), __FILE__, __LINE__);
ErrorCheck(cudaDeviceReset(), __FILE__, __LINE__);
return 0;
}

#include <stdio.h>
#include "../tools/common.cuh"
__device__ float add(const float x, const float y)
{
return x + y;
}
__global__ void addFromGPU(float *A, float *B, float *C, const int N)
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
const int id = tid + bid * blockDim.x;
if (id >= N) return;
C[id] = add(A[id], B[id]);
}
void initialData(float *addr, int elemCount)
{
for (int i = 0; i < elemCount; i++)
{
addr[i] = (float)(rand() & 0xFF) / 10.f;
}
return;
}
int main(void)
{
// 1、设置GPU设备
setGPU();
// 2、分配主机内存和设备内存,并初始化
int iElemCount = 4096; // 设置元素数量
size_t stBytesCount = iElemCount * sizeof(float); // 字节数
// (1)分配主机内存,并初始化
float *fpHost_A, *fpHost_B, *fpHost_C;
fpHost_A = (float *)malloc(stBytesCount);
fpHost_B = (float *)malloc(stBytesCount);
fpHost_C = (float *)malloc(stBytesCount);
if (fpHost_A != NULL && fpHost_B != NULL && fpHost_C != NULL)
{
memset(fpHost_A, 0, stBytesCount); // 主机内存初始化为0
memset(fpHost_B, 0, stBytesCount);
memset(fpHost_C, 0, stBytesCount);
}
else
{
printf("Fail to allocate host memory!\n");
exit(-1);
}
// (2)分配设备内存,并初始化
float *fpDevice_A, *fpDevice_B, *fpDevice_C;
cudaMalloc((float**)&fpDevice_A, stBytesCount);
cudaMalloc((float**)&fpDevice_B, stBytesCount);
cudaMalloc((float**)&fpDevice_C, stBytesCount);
if (fpDevice_A != NULL && fpDevice_B != NULL && fpDevice_C != NULL)
{
cudaMemset(fpDevice_A, 0, stBytesCount); // 设备内存初始化为0
cudaMemset(fpDevice_B, 0, stBytesCount);
cudaMemset(fpDevice_C, 0, stBytesCount);
}
else
{
printf("fail to allocate memory\n");
free(fpHost_A);
free(fpHost_B);
free(fpHost_C);
exit(-1);
}
// 3、初始化主机中数据
srand(666); // 设置随机种子
initialData(fpHost_A, iElemCount);
initialData(fpHost_B, iElemCount);
// 4、数据从主机复制到设备
cudaMemcpy(fpDevice_A, fpHost_A, stBytesCount, cudaMemcpyHostToDevice);
cudaMemcpy(fpDevice_B, fpHost_B, stBytesCount, cudaMemcpyHostToDevice);
cudaMemcpy(fpDevice_C, fpHost_C, stBytesCount, cudaMemcpyHostToDevice);
// 5、调用核函数在设备中进行计算
dim3 block(2048);
dim3 grid((iElemCount + block.x - 1) / 2048);
addFromGPU<<<grid, block>>>(fpDevice_A, fpDevice_B, fpDevice_C, iElemCount); // 调用核函数
ErrorCheck(cudaGetLastError(), __FILE__, __LINE__);
ErrorCheck(cudaDeviceSynchronize(), __FILE__, __LINE__);
// 6、将计算得到的数据从设备传给主机
cudaMemcpy(fpHost_C, fpDevice_C, stBytesCount, cudaMemcpyDeviceToHost);
for (int i = 0; i < 10; i++) // 打印
{
printf("idx=%2d\tmatrix_A:%.2f\tmatrix_B:%.2f\tresult=%.2f\n", i+1, fpHost_A[i], fpHost_B[i], fpHost_C[i]);
}
// 7、释放主机与设备内存
free(fpHost_A);
free(fpHost_B);
free(fpHost_C);
cudaFree(fpDevice_A);
cudaFree(fpDevice_B);
cudaFree(fpDevice_C);
cudaDeviceReset();
return 0;
}
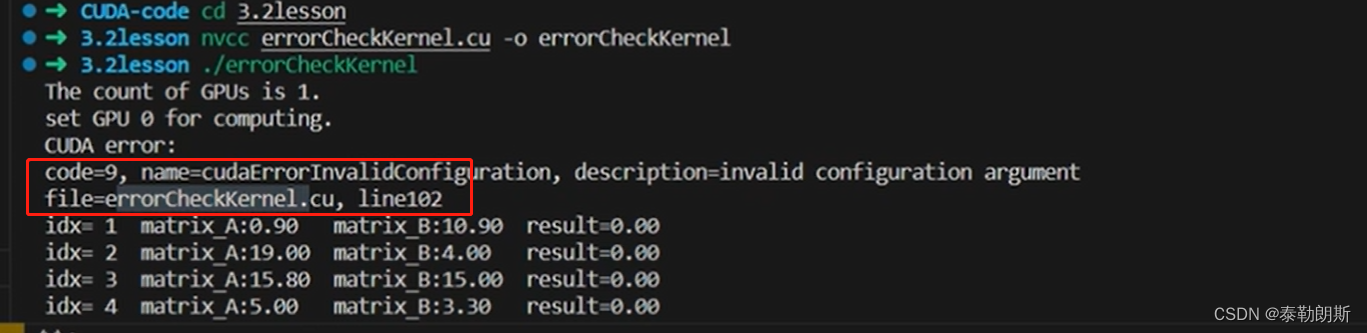
错误捕获
CUDA 计时

下面注意第5行,不可以用errorcheck
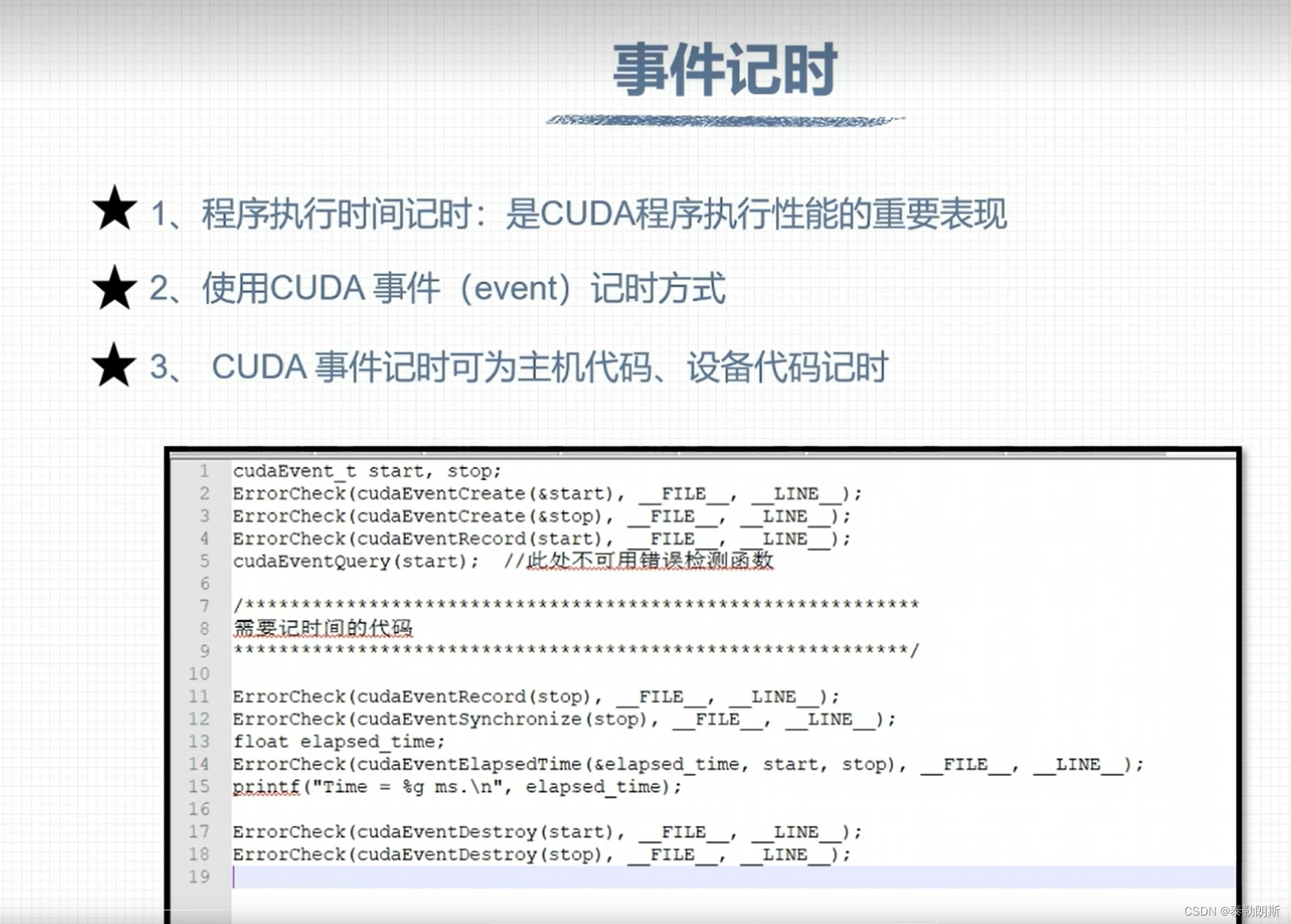
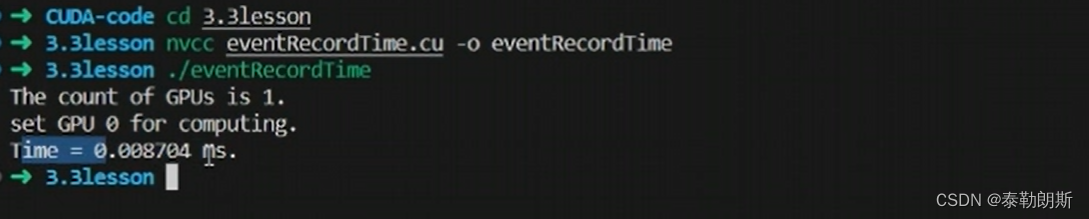
第一次调用核函数会花费非常长的时间
#include <stdio.h>
#include "../tools/common.cuh"
#define NUM_REPEATS 10
__device__ float add(const float x, const float y)
{
return x + y;
}
__global__ void addFromGPU(float *A, float *B, float *C, const int N)
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
const int id = tid + bid * blockDim.x;
if (id >= N) return;
C[id] = add(A[id], B[id]);
}
void initialData(float *addr, int elemCount)
{
for (int i = 0; i < elemCount; i++)
{
addr[i] = (float)(rand() & 0xFF) / 10.f;
}
return;
}
int main(void)
{
// 1、设置GPU设备
setGPU();
// 2、分配主机内存和设备内存,并初始化
int iElemCount = 4096; // 设置元素数量
size_t stBytesCount = iElemCount * sizeof(float); // 字节数
// (1)分配主机内存,并初始化
float *fpHost_A, *fpHost_B, *fpHost_C;
fpHost_A = (float *)malloc(stBytesCount);
fpHost_B = (float *)malloc(stBytesCount);
fpHost_C = (float *)malloc(stBytesCount);
if (fpHost_A != NULL && fpHost_B != NULL && fpHost_C != NULL)
{
memset(fpHost_A, 0, stBytesCount); // 主机内存初始化为0
memset(fpHost_B, 0, stBytesCount);
memset(fpHost_C, 0, stBytesCount);
}
else
{
printf("Fail to allocate host memory!\n");
exit(-1);
}
// (2)分配设备内存,并初始化
float *fpDevice_A, *fpDevice_B, *fpDevice_C;
ErrorCheck(cudaMalloc((float**)&fpDevice_A, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((float**)&fpDevice_B, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((float**)&fpDevice_C, stBytesCount), __FILE__, __LINE__);
if (fpDevice_A != NULL && fpDevice_B != NULL && fpDevice_C != NULL)
{
ErrorCheck(cudaMemset(fpDevice_A, 0, stBytesCount), __FILE__, __LINE__); // 设备内存初始化为0
ErrorCheck(cudaMemset(fpDevice_B, 0, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMemset(fpDevice_C, 0, stBytesCount), __FILE__, __LINE__);
}
else
{
printf("fail to allocate memory\n");
free(fpHost_A);
free(fpHost_B);
free(fpHost_C);
exit(-1);
}
// 3、初始化主机中数据
srand(666); // 设置随机种子
initialData(fpHost_A, iElemCount);
initialData(fpHost_B, iElemCount);
// 4、数据从主机复制到设备
ErrorCheck(cudaMemcpy(fpDevice_A, fpHost_A, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(fpDevice_B, fpHost_B, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(fpDevice_C, fpHost_C, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
// 5、调用核函数在设备中进行计算
dim3 block(32);
dim3 grid((iElemCount + block.x - 1) / 32);
float t_sum = 0;
for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
ErrorCheck(cudaEventCreate(&start), __FILE__, __LINE__);
ErrorCheck(cudaEventCreate(&stop), __FILE__, __LINE__);
ErrorCheck(cudaEventRecord(start), __FILE__, __LINE__);
cudaEventQuery(start); //此处不可用错误检测函数
addFromGPU<<<grid, block>>>(fpDevice_A, fpDevice_B, fpDevice_C, iElemCount); // 调用核函数
ErrorCheck(cudaEventRecord(stop), __FILE__, __LINE__);
ErrorCheck(cudaEventSynchronize(stop), __FILE__, __LINE__);
float elapsed_time;
ErrorCheck(cudaEventElapsedTime(&elapsed_time, start, stop), __FILE__, __LINE__);
// printf("Time = %g ms.\n", elapsed_time);
if (repeat > 0)
{
t_sum += elapsed_time;
}
ErrorCheck(cudaEventDestroy(start), __FILE__, __LINE__);
ErrorCheck(cudaEventDestroy(stop), __FILE__, __LINE__);
}
const float t_ave = t_sum / NUM_REPEATS;
printf("Time = %g ms.\n", t_ave);
// 6、将计算得到的数据从设备传给主机
ErrorCheck(cudaMemcpy(fpHost_C, fpDevice_C, stBytesCount, cudaMemcpyDeviceToHost), __FILE__, __LINE__);
// 7、释放主机与设备内存
free(fpHost_A);
free(fpHost_B);
free(fpHost_C);
ErrorCheck(cudaFree(fpDevice_A), __FILE__, __LINE__);
ErrorCheck(cudaFree(fpDevice_B), __FILE__, __LINE__);
ErrorCheck(cudaFree(fpDevice_C), __FILE__, __LINE__);
ErrorCheck(cudaDeviceReset(), __FILE__, __LINE__);
return 0;
}
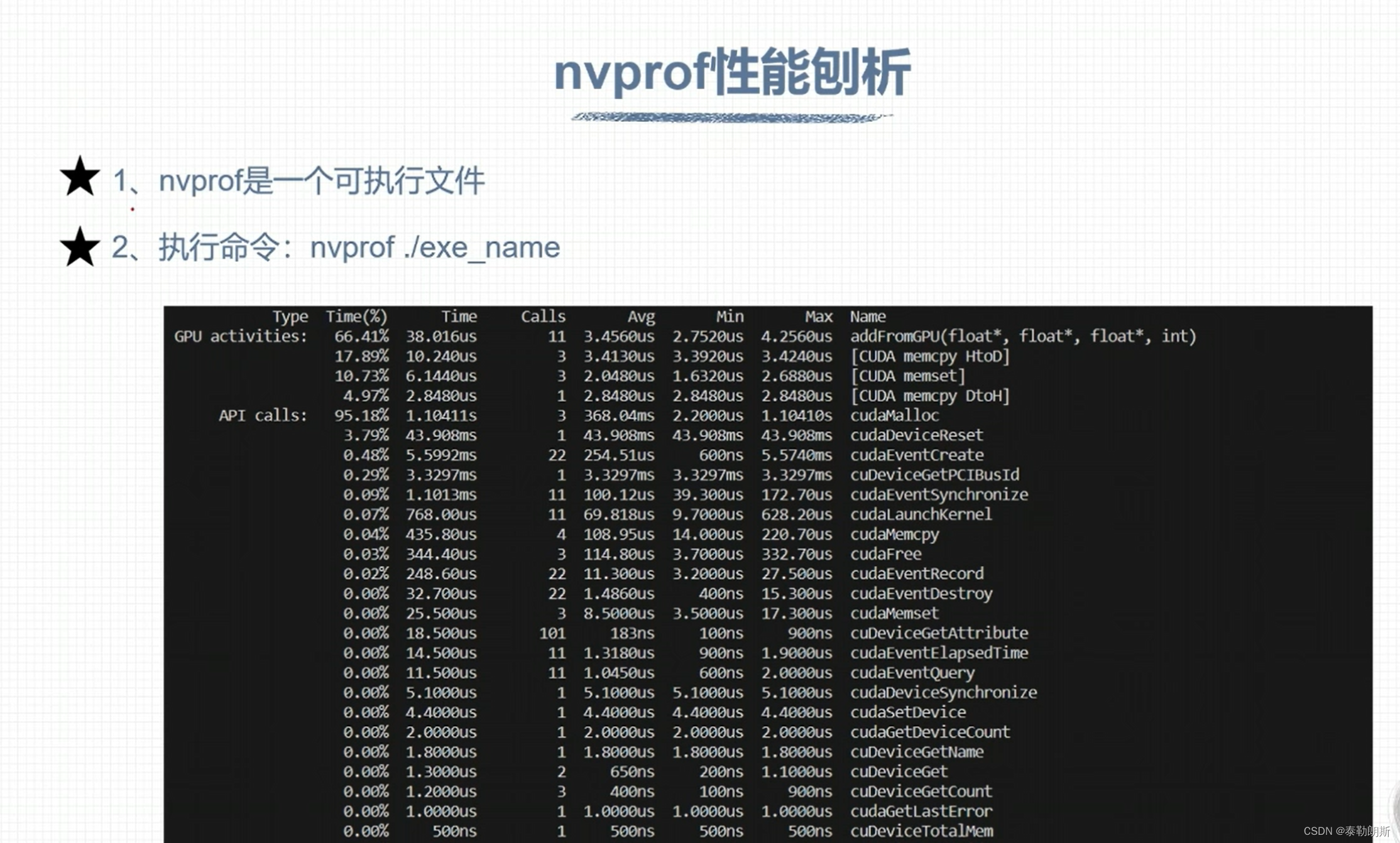
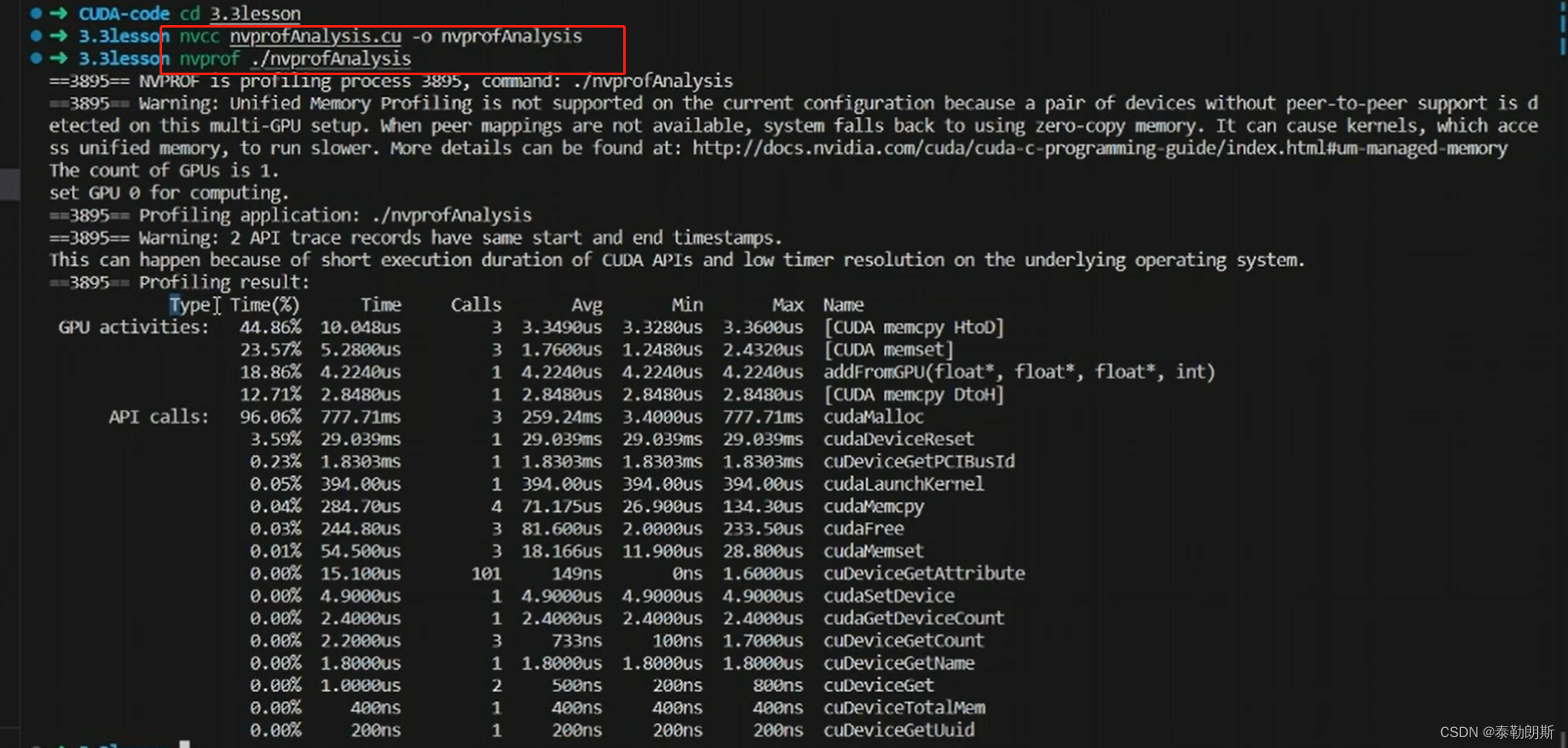
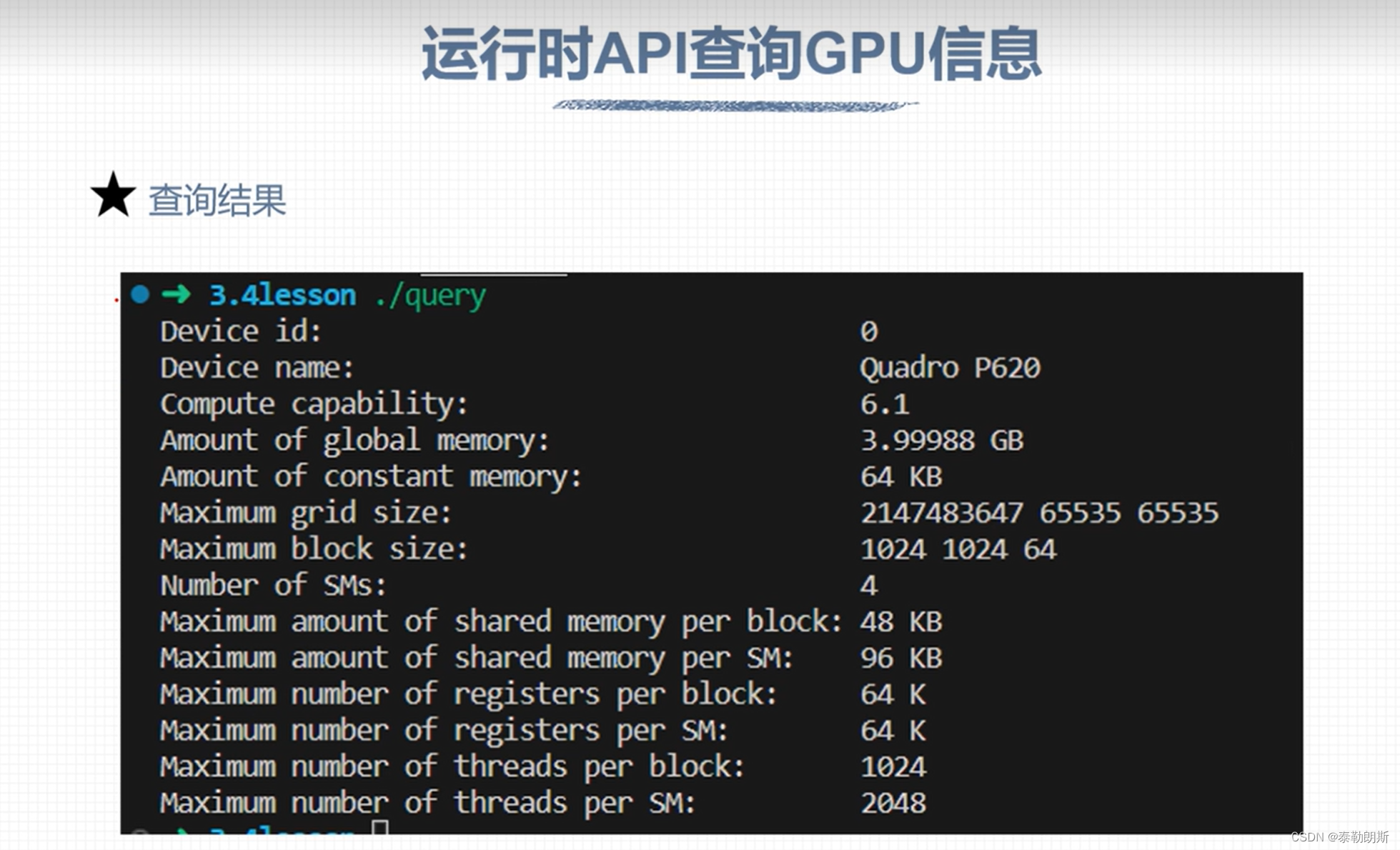
运行时GPU信息查询

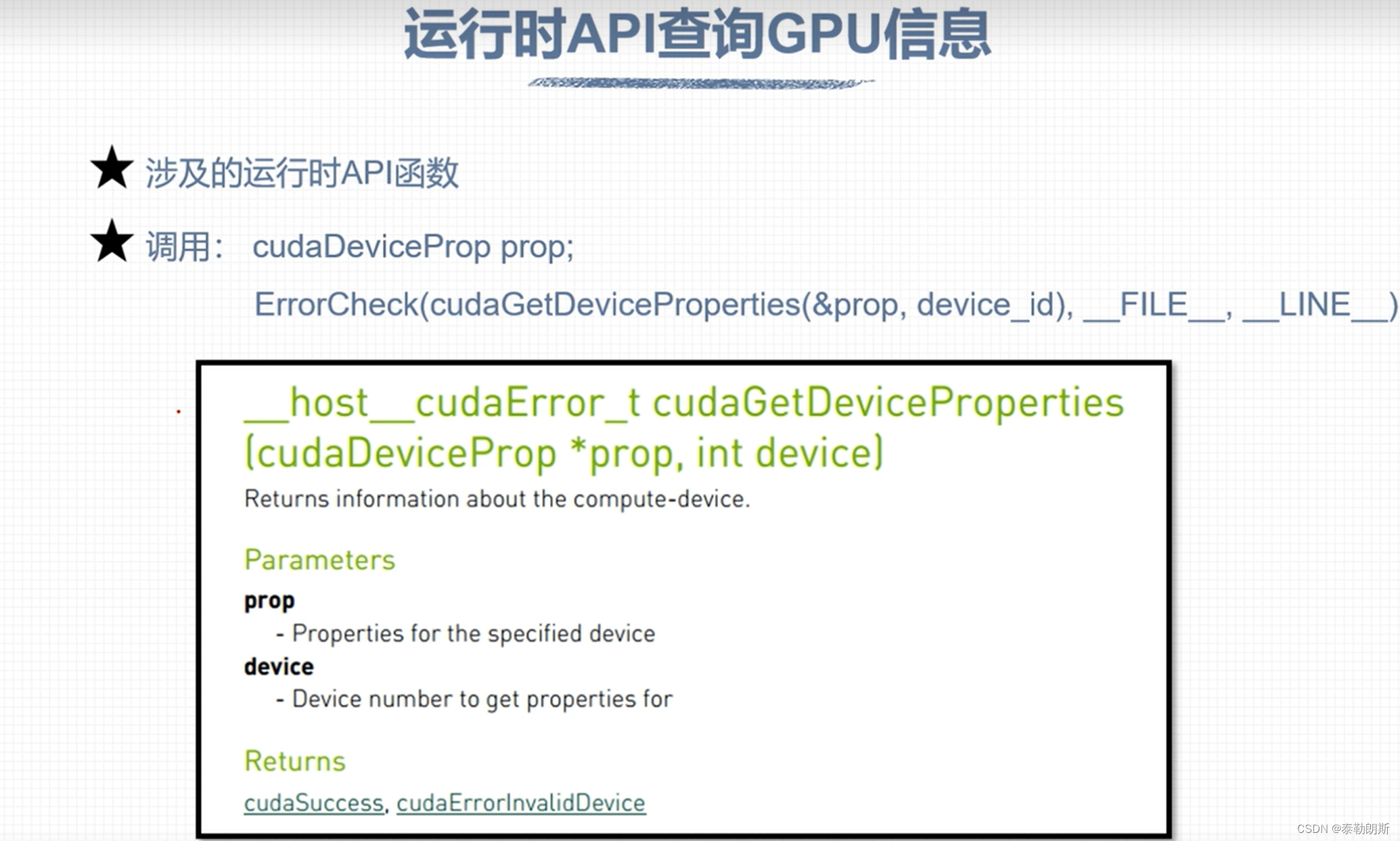
#include "../tools/common.cuh"
#include <stdio.h>
int main(void)
{
int device_id = 0;
ErrorCheck(cudaSetDevice(device_id), __FILE__, __LINE__);
cudaDeviceProp prop;
ErrorCheck(cudaGetDeviceProperties(&prop, device_id), __FILE__, __LINE__);
printf("Device id: %d\n",
device_id);
printf("Device name: %s\n",
prop.name);
printf("Compute capability: %d.%d\n",
prop.major, prop.minor);
printf("Amount of global memory: %g GB\n",
prop.totalGlobalMem / (1024.0 * 1024 * 1024));
printf("Amount of constant memory: %g KB\n",
prop.totalConstMem / 1024.0);
printf("Maximum grid size: %d %d %d\n",
prop.maxGridSize[0],
prop.maxGridSize[1], prop.maxGridSize[2]);
printf("Maximum block size: %d %d %d\n",
prop.maxThreadsDim[0], prop.maxThreadsDim[1],
prop.maxThreadsDim[2]);
printf("Number of SMs: %d\n",
prop.multiProcessorCount);
printf("Maximum amount of shared memory per block: %g KB\n",
prop.sharedMemPerBlock / 1024.0);
printf("Maximum amount of shared memory per SM: %g KB\n",
prop.sharedMemPerMultiprocessor / 1024.0);
printf("Maximum number of registers per block: %d K\n",
prop.regsPerBlock / 1024);
printf("Maximum number of registers per SM: %d K\n",
prop.regsPerMultiprocessor / 1024);
printf("Maximum number of threads per block: %d\n",
prop.maxThreadsPerBlock);
printf("Maximum number of threads per SM: %d\n",
prop.maxThreadsPerMultiProcessor);
return 0;
}

#include <stdio.h>
#include "../tools/common.cuh"
int getSPcores(cudaDeviceProp devProp)
{
int cores = 0;
int mp = devProp.multiProcessorCount;
switch (devProp.major){
case 2: // Fermi
if (devProp.minor == 1) cores = mp * 48;
else cores = mp * 32;
break;
case 3: // Kepler
cores = mp * 192;
break;
case 5: // Maxwell
cores = mp * 128;
break;
case 6: // Pascal
if ((devProp.minor == 1) || (devProp.minor == 2)) cores = mp * 128;
else if (devProp.minor == 0) cores = mp * 64;
else printf("Unknown device type\n");
break;
case 7: // Volta and Turing
if ((devProp.minor == 0) || (devProp.minor == 5)) cores = mp * 64;
else printf("Unknown device type\n");
break;
case 8: // Ampere
if (devProp.minor == 0) cores = mp * 64;
else if (devProp.minor == 6) cores = mp * 128;
else if (devProp.minor == 9) cores = mp * 128; // ada lovelace
else printf("Unknown device type\n");
break;
case 9: // Hopper
if (devProp.minor == 0) cores = mp * 128;
else printf("Unknown device type\n");
break;
default:
printf("Unknown device type\n");
break;
}
return cores;
}
int main()
{
int device_id = 0;
ErrorCheck(cudaSetDevice(device_id), __FILE__, __LINE__);
cudaDeviceProp prop;
ErrorCheck(cudaGetDeviceProperties(&prop, device_id), __FILE__, __LINE__);
printf("Compute cores is %d.\n", getSPcores(prop));
return 0;
}
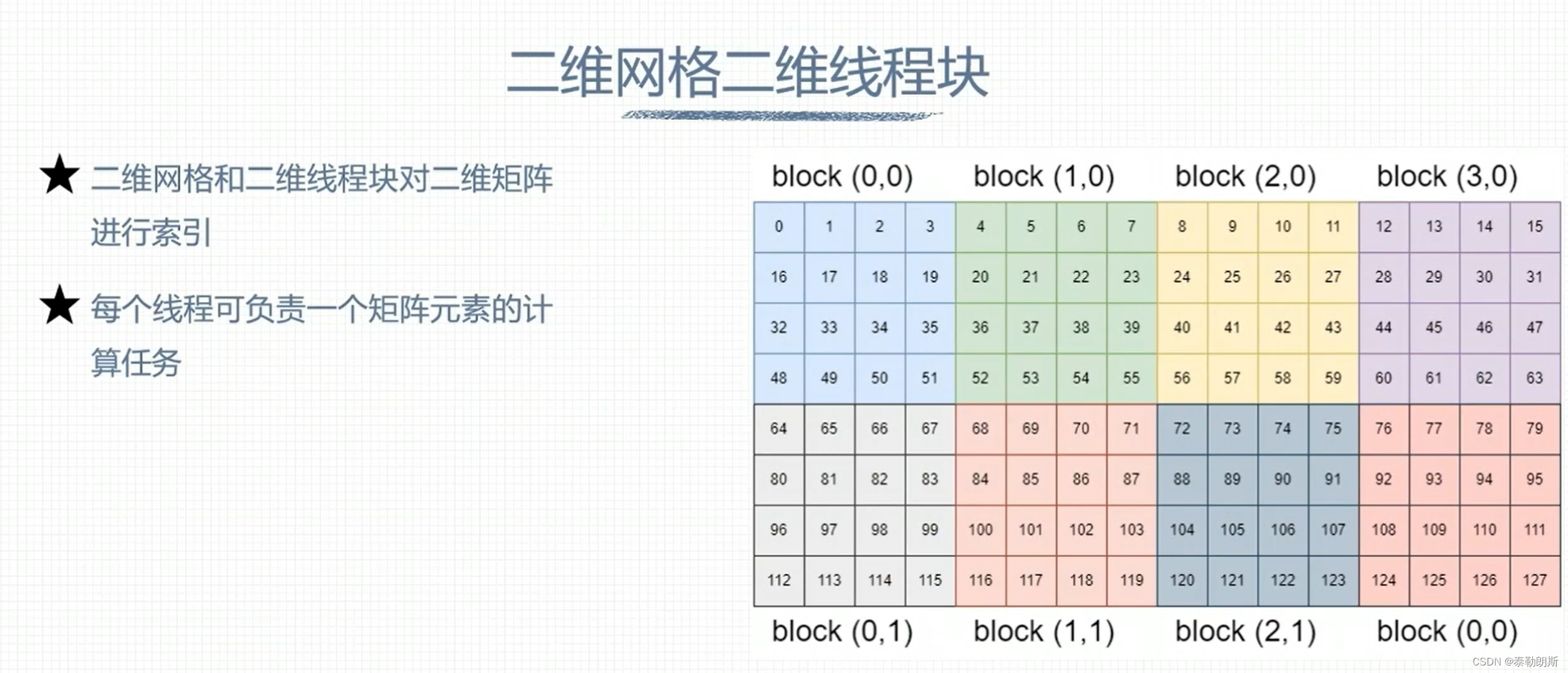
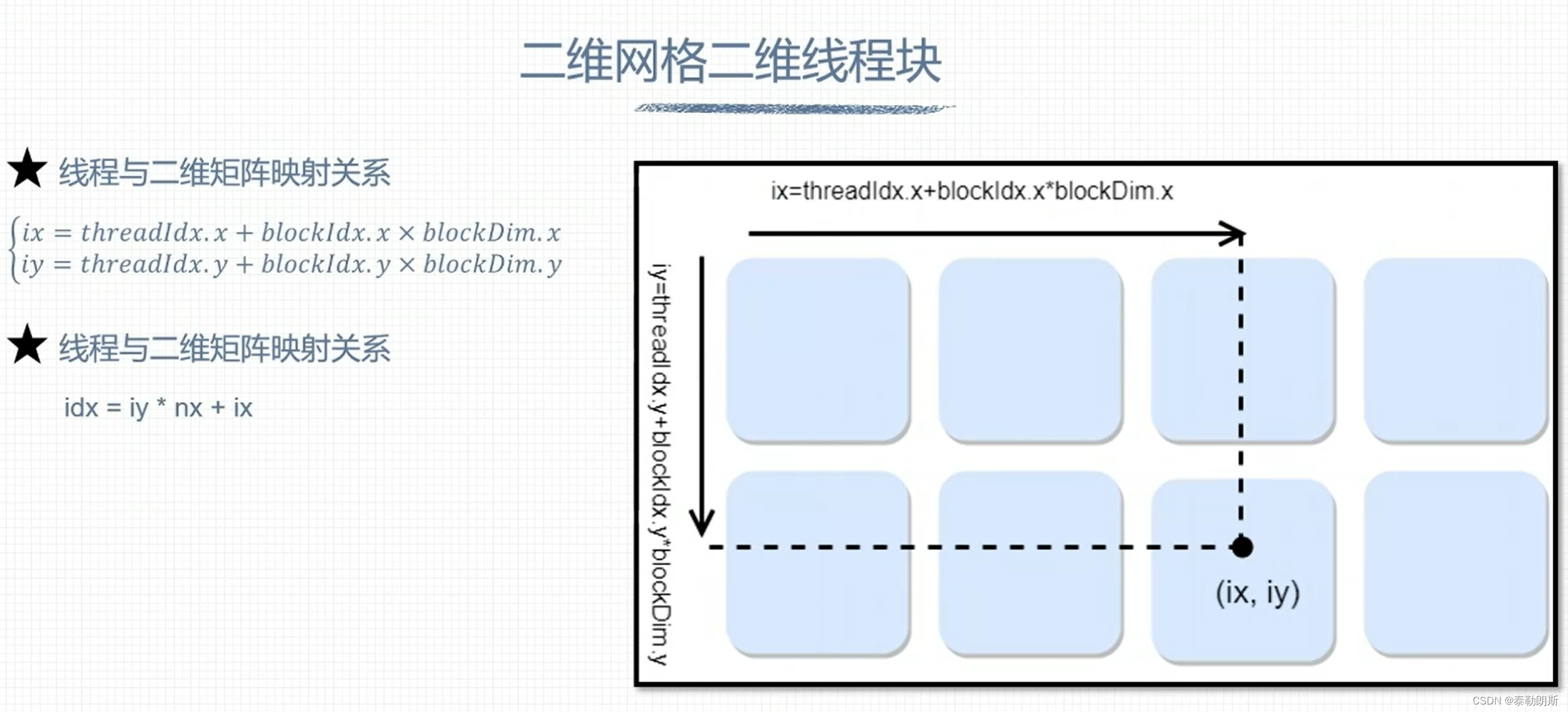
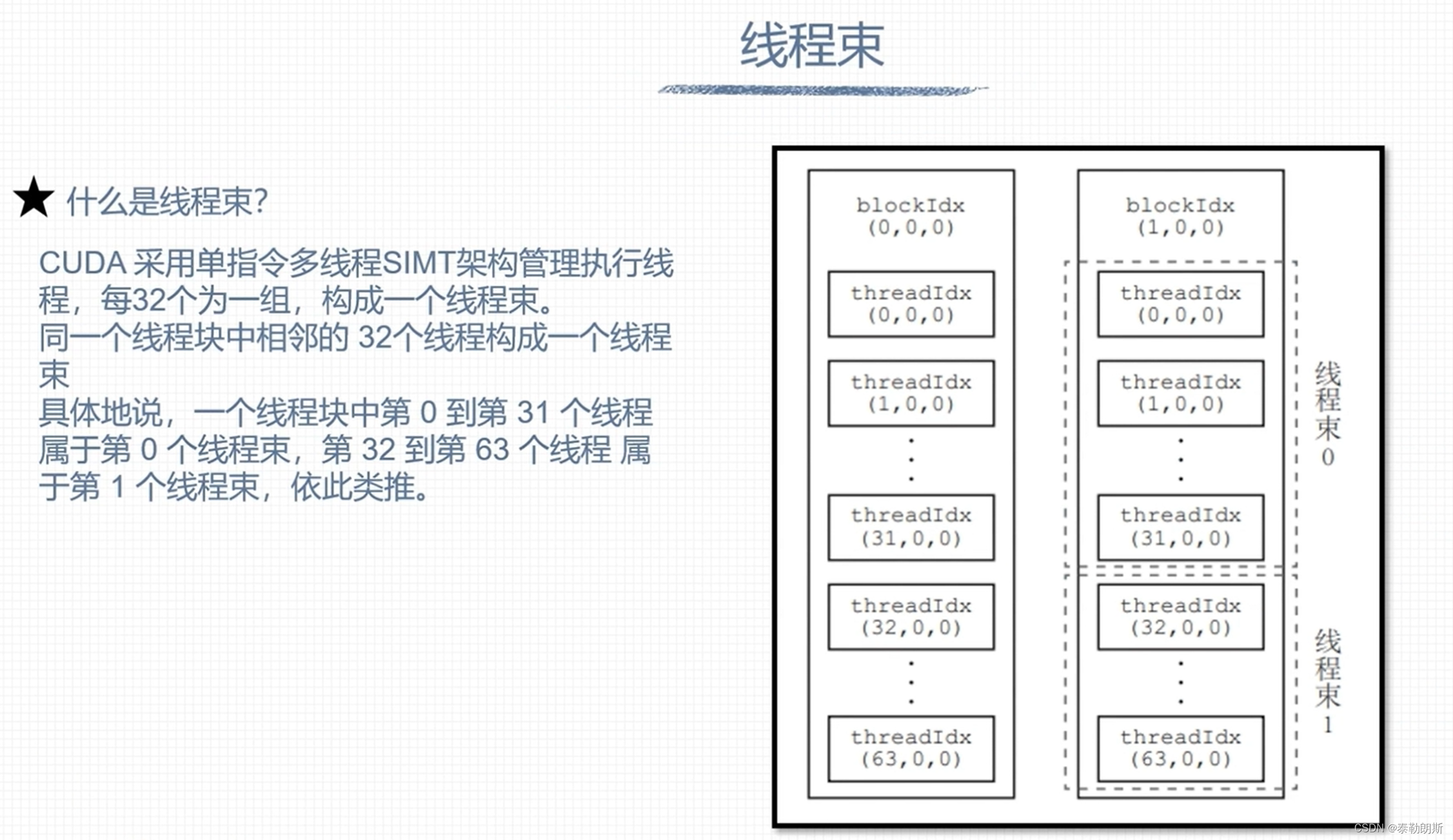
组织线程模型

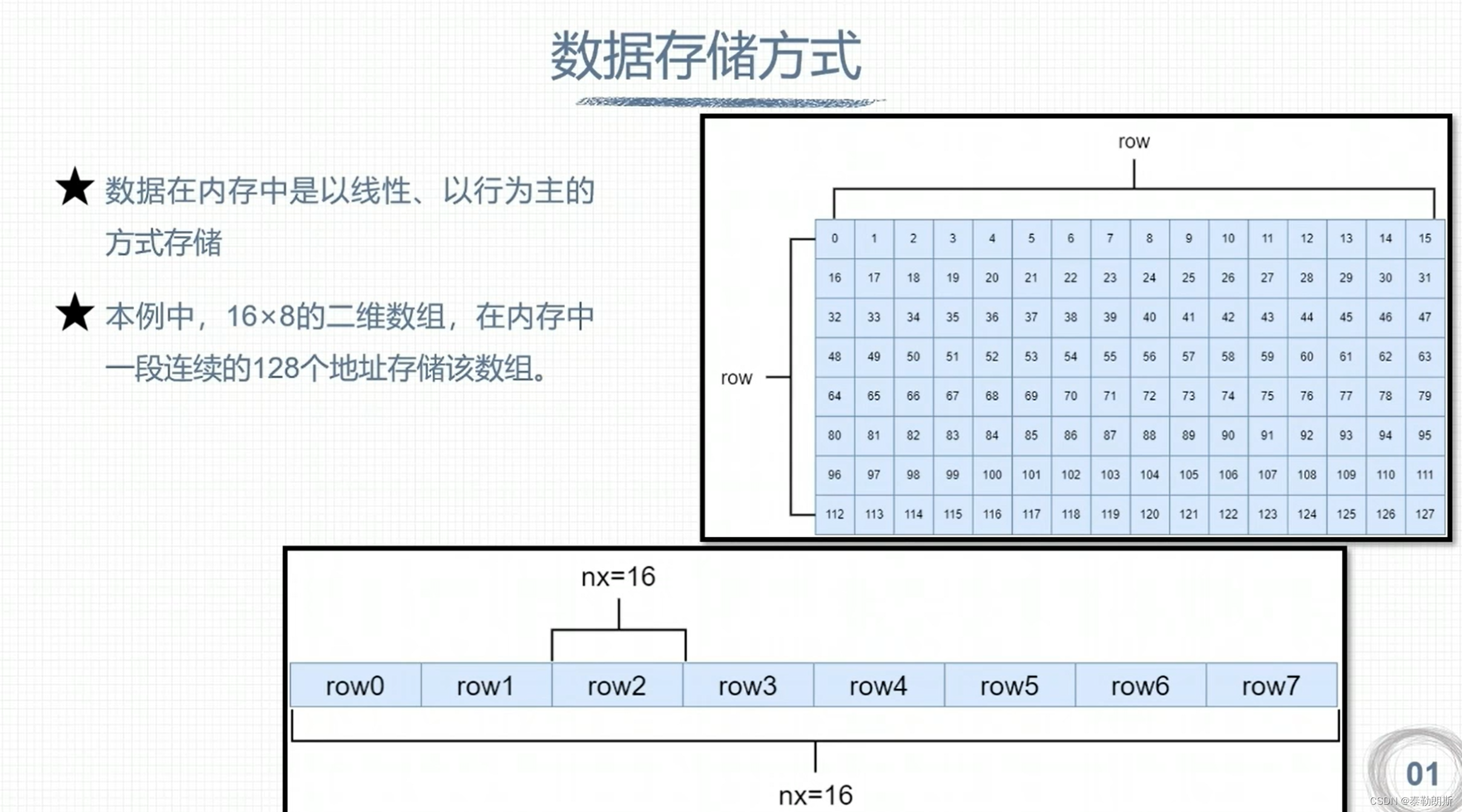
下图中上面的row为column
下面最后一block应该为(3,1)
下列计算指出该元素在第几行第几列,所以nx=16
idx=iy*nx + ix
#include <stdio.h>
#include "../tools/common.cuh"
__global__ void addMatrix(int *A, int *B, int *C, const int nx, const int ny)
{
int ix = threadIdx.x + blockIdx.x * blockDim.x;
int iy = threadIdx.y + blockIdx.y * blockDim.y;;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
{
C[idx] = A[idx] + B[idx];
}
}
int main(void)
{
// 1、设置GPU设备
setGPU();
// 2、分配主机内存和设备内存,并初始化
int nx = 16;
int ny = 8;
int nxy = nx * ny;
size_t stBytesCount = nxy * sizeof(int);
// (1)分配主机内存,并初始化
int *ipHost_A, *ipHost_B, *ipHost_C;
ipHost_A = (int *)malloc(stBytesCount);
ipHost_B = (int *)malloc(stBytesCount);
ipHost_C = (int *)malloc(stBytesCount);
if (ipHost_A != NULL && ipHost_B != NULL && ipHost_C != NULL)
{
for (int i = 0; i < nxy; i++)
{
ipHost_A[i] = i;
ipHost_B[i] = i + 1;
}
memset(ipHost_C, 0, stBytesCount);
}
else
{
printf("Fail to allocate host memory!\n");
exit(-1);
}
// (2)分配设备内存,并初始化
int *ipDevice_A, *ipDevice_B, *ipDevice_C;
ErrorCheck(cudaMalloc((int**)&ipDevice_A, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((int**)&ipDevice_B, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((int**)&ipDevice_C, stBytesCount), __FILE__, __LINE__);
if (ipDevice_A != NULL && ipDevice_B != NULL && ipDevice_C != NULL)
{
ErrorCheck(cudaMemcpy(ipDevice_A, ipHost_A, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(ipDevice_B, ipHost_B, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(ipDevice_C, ipHost_C, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
}
else
{
printf("Fail to allocate memory\n");
free(ipHost_A);
free(ipHost_B);
free(ipHost_C);
exit(1);
}
// calculate on GPU
dim3 block(4, 4);
dim3 grid((nx + block.x -1) / block.x, (ny + block.y - 1) / block.y);
printf("Thread config:grid:<%d, %d>, block:<%d, %d>\n", grid.x, grid.y, block.x, block.y);
addMatrix<<<grid, block>>>(ipDevice_A, ipDevice_B, ipDevice_C, nx, ny); // 调用内核函数
ErrorCheck(cudaMemcpy(ipHost_C, ipDevice_C, stBytesCount, cudaMemcpyDeviceToHost), __FILE__, __LINE__);
for (int i = 0; i < 10; i++)
{
printf("id=%d, matrix_A=%d, matrix_B=%d, result=%d\n", i + 1,ipHost_A[i], ipHost_B[i], ipHost_C[i]);
}
free(ipHost_A);
free(ipHost_B);
free(ipHost_C);
ErrorCheck(cudaFree(ipDevice_A), __FILE__, __LINE__);
ErrorCheck(cudaFree(ipDevice_B), __FILE__, __LINE__);
ErrorCheck(cudaFree(ipDevice_C), __FILE__, __LINE__);
ErrorCheck(cudaDeviceReset(), __FILE__, __LINE__);
return 0;
}
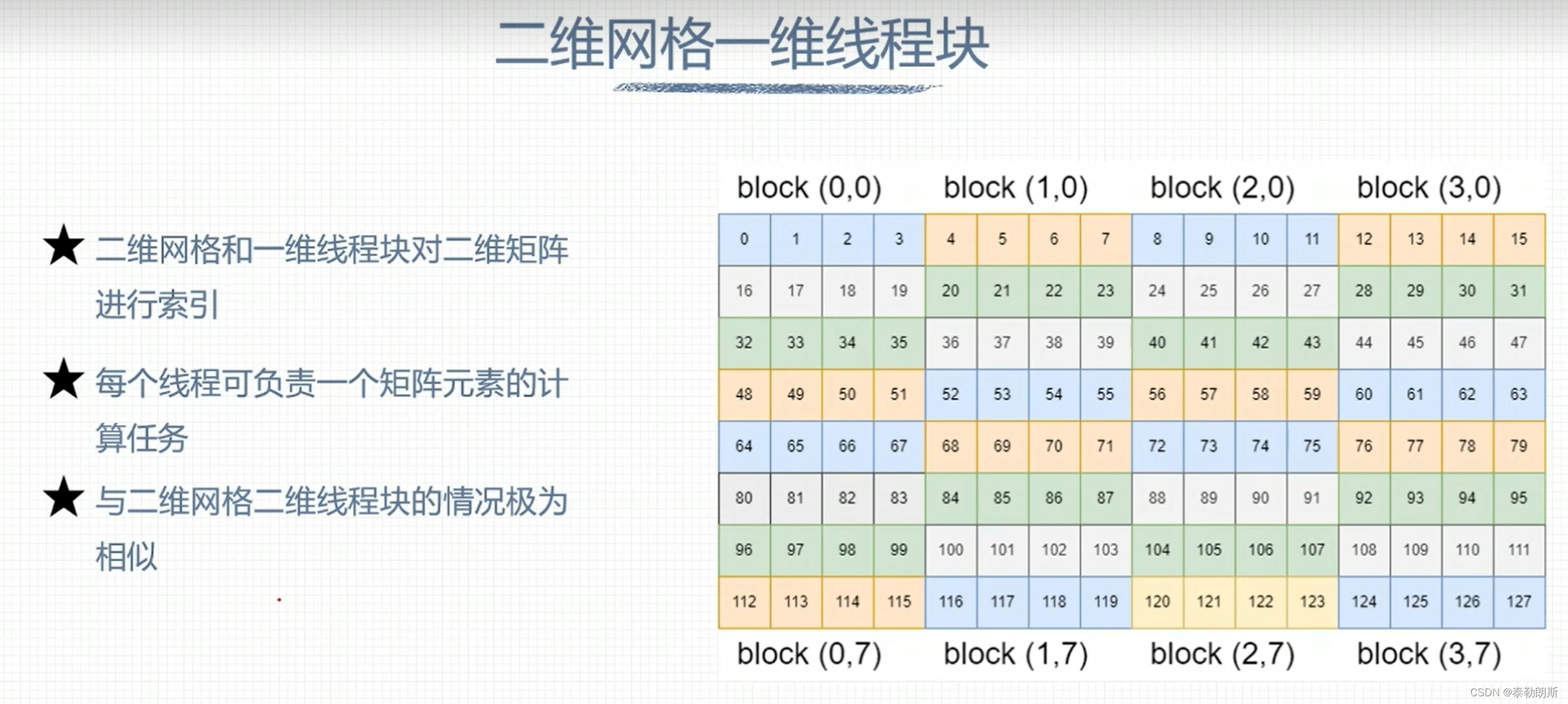
这里也是计算几行几列
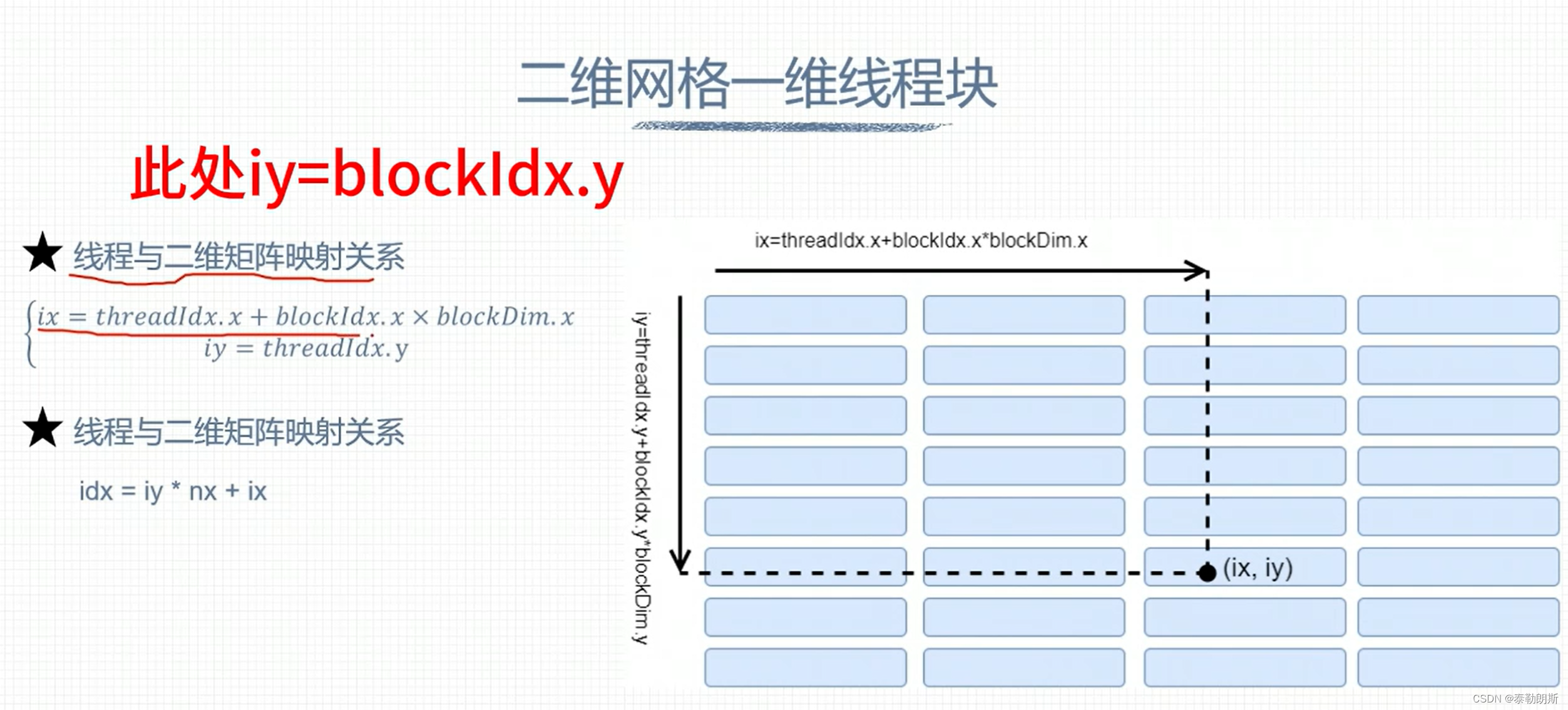
还是一个线程处理一个数据
#include <stdio.h>
#include "../tools/common.cuh"
__global__ void addMatrix(int *A, int *B, int *C, const int nx, const int ny)
{
int ix = threadIdx.x + blockIdx.x * blockDim.x;
int iy = blockIdx.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
{
C[idx] = A[idx] + B[idx];
}
}
int main(void)
{
// 1、设置GPU设备
setGPU();
// 2、分配主机内存和设备内存,并初始化
int nx = 16;
int ny = 8;
int nxy = nx * ny;
size_t stBytesCount = nxy * sizeof(int);
// (1)分配主机内存,并初始化
int *ipHost_A, *ipHost_B, *ipHost_C;
ipHost_A = (int *)malloc(stBytesCount);
ipHost_B = (int *)malloc(stBytesCount);
ipHost_C = (int *)malloc(stBytesCount);
if (ipHost_A != NULL && ipHost_B != NULL && ipHost_C != NULL)
{
for (int i = 0; i < nxy; i++)
{
ipHost_A[i] = i;
ipHost_B[i] = i + 1;
}
memset(ipHost_C, 0, stBytesCount);
}
else
{
printf("Fail to allocate host memory!\n");
exit(-1);
}
// (2)分配设备内存,并初始化
int *ipDevice_A, *ipDevice_B, *ipDevice_C;
ErrorCheck(cudaMalloc((int**)&ipDevice_A, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((int**)&ipDevice_B, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((int**)&ipDevice_C, stBytesCount), __FILE__, __LINE__);
if (ipDevice_A != NULL && ipDevice_B != NULL && ipDevice_C != NULL)
{
ErrorCheck(cudaMemcpy(ipDevice_A, ipHost_A, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(ipDevice_B, ipHost_B, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(ipDevice_C, ipHost_C, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
}
else
{
printf("Fail to allocate memory\n");
free(ipHost_A);
free(ipHost_B);
free(ipHost_C);
exit(1);
}
// calculate on GPU
dim3 block(4, 1);
dim3 grid((nx + block.x -1) / block.x, ny); //(4,8)
printf("Thread config:grid:<%d, %d>, block:<%d, %d>\n", grid.x, grid.y, block.x, block.y);
addMatrix<<<grid, block>>>(ipDevice_A, ipDevice_B, ipDevice_C, nx, ny); // 调用内核函数
ErrorCheck(cudaMemcpy(ipHost_C, ipDevice_C, stBytesCount, cudaMemcpyDeviceToHost), __FILE__, __LINE__);
for (int i = 0; i < 10; i++)
{
printf("id=%d, matrix_A=%d, matrix_B=%d, result=%d\n", i + 1,ipHost_A[i], ipHost_B[i], ipHost_C[i]);
}
free(ipHost_A);
free(ipHost_B);
free(ipHost_C);
ErrorCheck(cudaFree(ipDevice_A), __FILE__, __LINE__);
ErrorCheck(cudaFree(ipDevice_B), __FILE__, __LINE__);
ErrorCheck(cudaFree(ipDevice_C), __FILE__, __LINE__);
ErrorCheck(cudaDeviceReset(), __FILE__, __LINE__);
return 0;
}
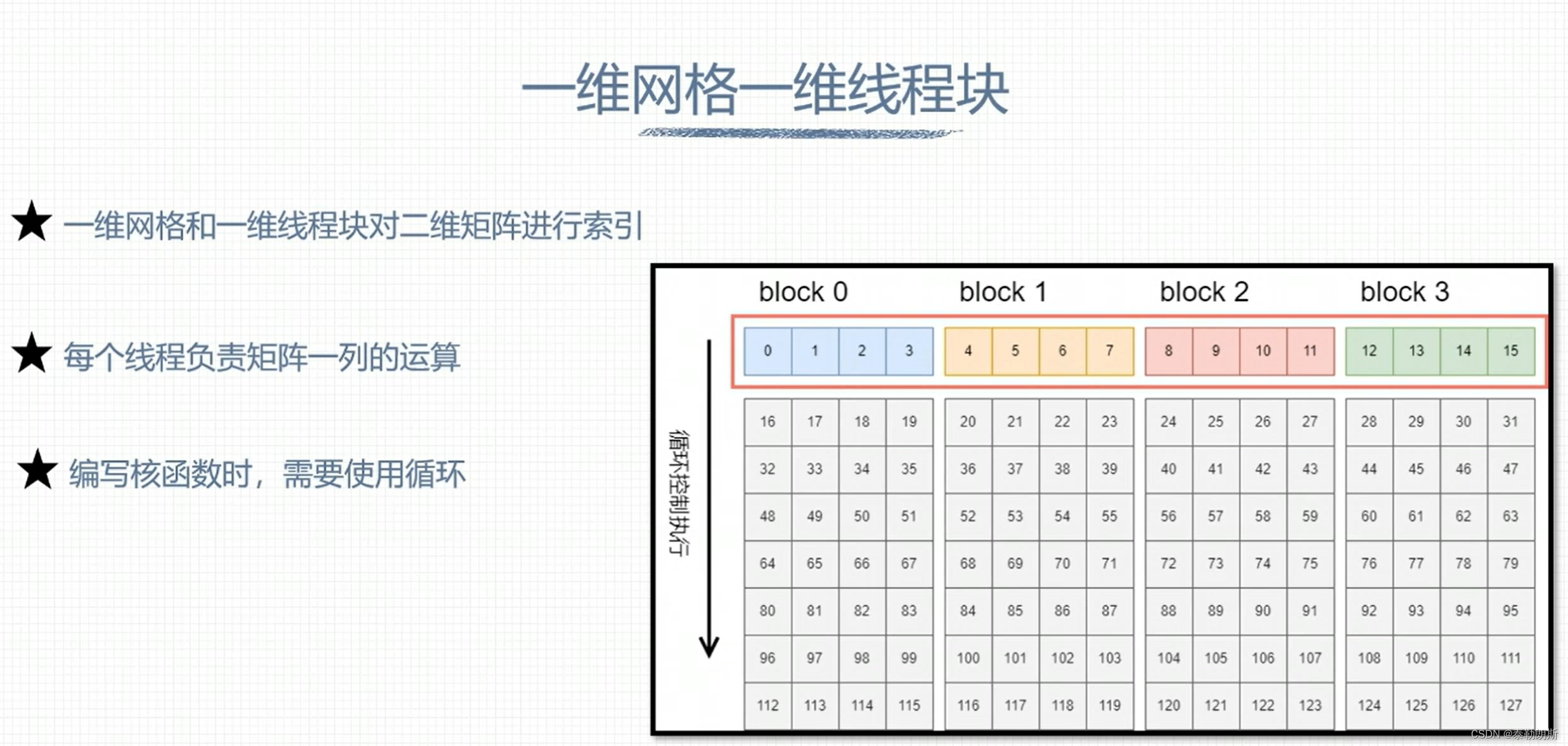
下面是一个线程负责一列数据
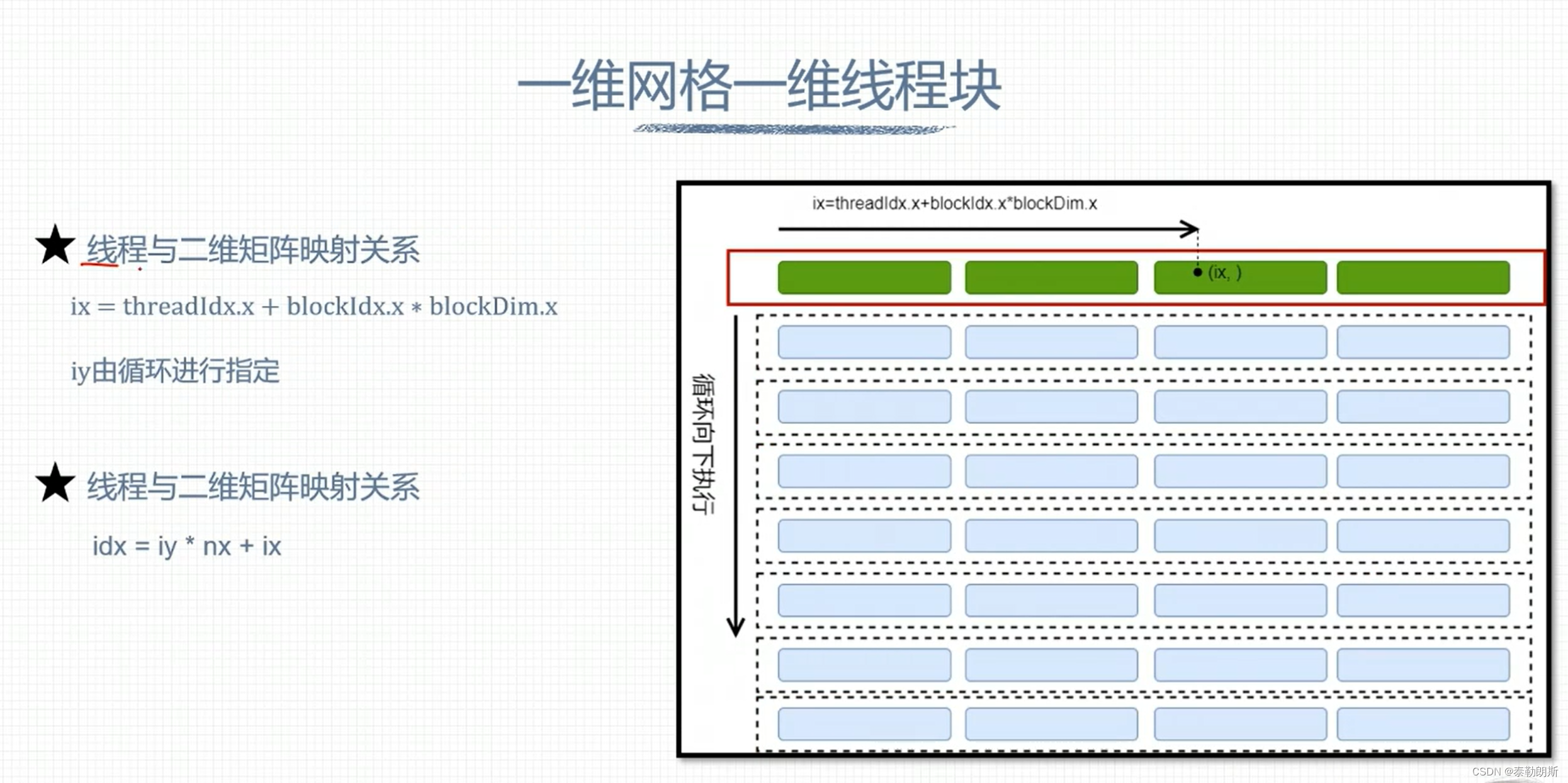
#include <stdio.h>
#include "../tools/common.cuh"
__global__ void addMatrix(int *A, int *B, int *C, const int nx, const int ny)
{
int ix = threadIdx.x + blockIdx.x * blockDim.x;
if (ix < nx)
{
for (int iy = 0; iy < ny; iy++)
{
int idx = iy * nx + ix;
C[idx] = A[idx] + B[idx];
}
}
}
int main(void)
{
// 1、设置GPU设备
setGPU();
// 2、分配主机内存和设备内存,并初始化
int nx = 16;
int ny = 8;
int nxy = nx * ny;
size_t stBytesCount = nxy * sizeof(int);
// (1)分配主机内存,并初始化
int *ipHost_A, *ipHost_B, *ipHost_C;
ipHost_A = (int *)malloc(stBytesCount);
ipHost_B = (int *)malloc(stBytesCount);
ipHost_C = (int *)malloc(stBytesCount);
if (ipHost_A != NULL && ipHost_B != NULL && ipHost_C != NULL)
{
for (int i = 0; i < nxy; i++)
{
ipHost_A[i] = i;
ipHost_B[i] = i + 1;
}
memset(ipHost_C, 0, stBytesCount);
}
else
{
printf("Fail to allocate host memory!\n");
exit(-1);
}
// (2)分配设备内存,并初始化
int *ipDevice_A, *ipDevice_B, *ipDevice_C;
ErrorCheck(cudaMalloc((int**)&ipDevice_A, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((int**)&ipDevice_B, stBytesCount), __FILE__, __LINE__);
ErrorCheck(cudaMalloc((int**)&ipDevice_C, stBytesCount), __FILE__, __LINE__);
if (ipDevice_A != NULL && ipDevice_B != NULL && ipDevice_C != NULL)
{
ErrorCheck(cudaMemcpy(ipDevice_A, ipHost_A, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(ipDevice_B, ipHost_B, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
ErrorCheck(cudaMemcpy(ipDevice_C, ipHost_C, stBytesCount, cudaMemcpyHostToDevice), __FILE__, __LINE__);
}
else
{
printf("Fail to allocate memory\n");
free(ipHost_A);
free(ipHost_B);
free(ipHost_C);
exit(1);
}
// calculate on GPU
dim3 block(4, 1);
dim3 grid((nx + block.x -1) / block.x, 1);
printf("Thread config:grid:<%d, %d>, block:<%d, %d>\n", grid.x, grid.y, block.x, block.y);
addMatrix<<<grid, block>>>(ipDevice_A, ipDevice_B, ipDevice_C, nx, ny); // 调用内核函数
ErrorCheck(cudaMemcpy(ipHost_C, ipDevice_C, stBytesCount, cudaMemcpyDeviceToHost), __FILE__, __LINE__);
for (int i = 0; i < 10; i++)
{
printf("id=%d, matrix_A=%d, matrix_B=%d, result=%d\n", i + 1,ipHost_A[i], ipHost_B[i], ipHost_C[i]);
}
free(ipHost_A);
free(ipHost_B);
free(ipHost_C);
ErrorCheck(cudaFree(ipDevice_A), __FILE__, __LINE__);
ErrorCheck(cudaFree(ipDevice_B), __FILE__, __LINE__);
ErrorCheck(cudaFree(ipDevice_C), __FILE__, __LINE__);
ErrorCheck(cudaDeviceReset(), __FILE__, __LINE__);
return 0;
}
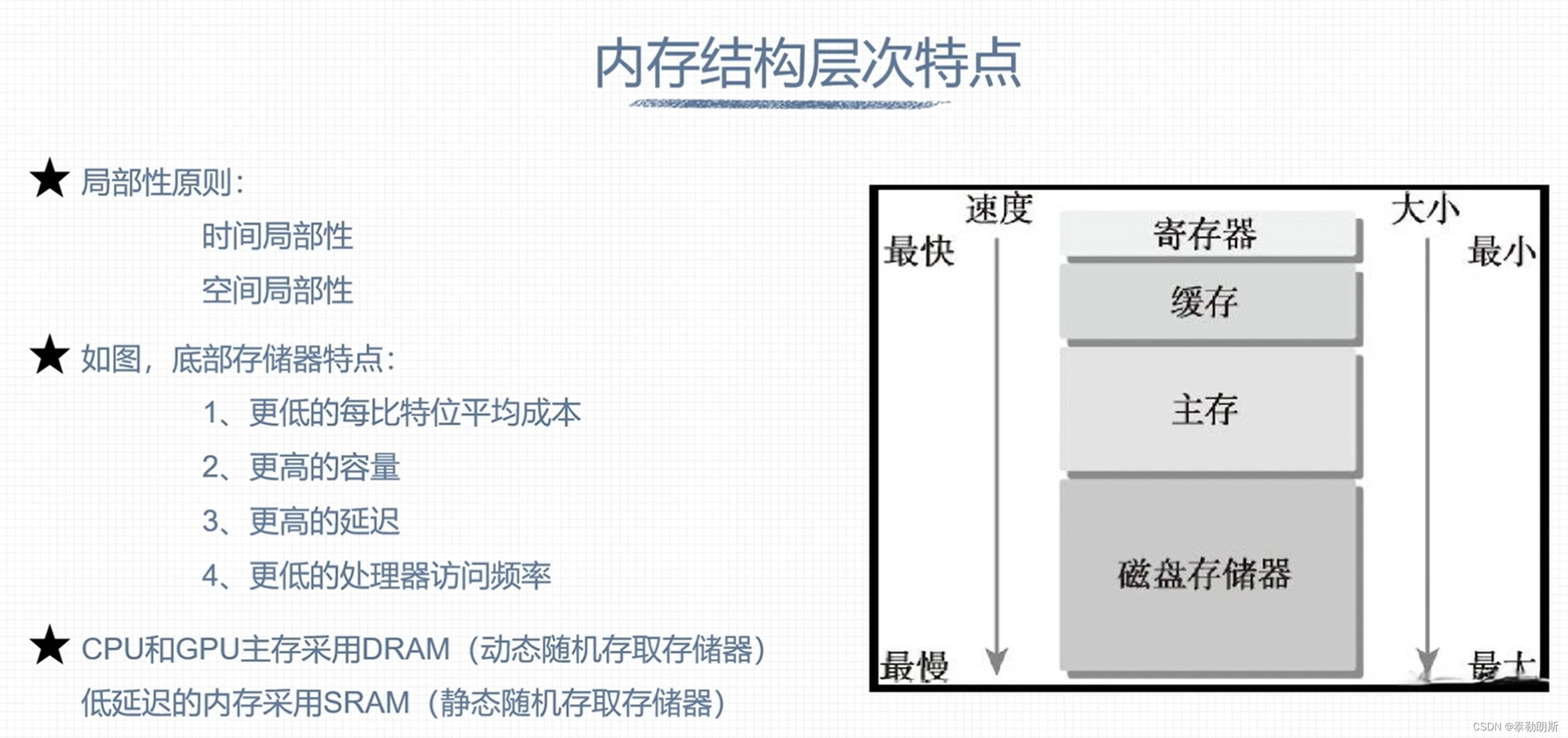
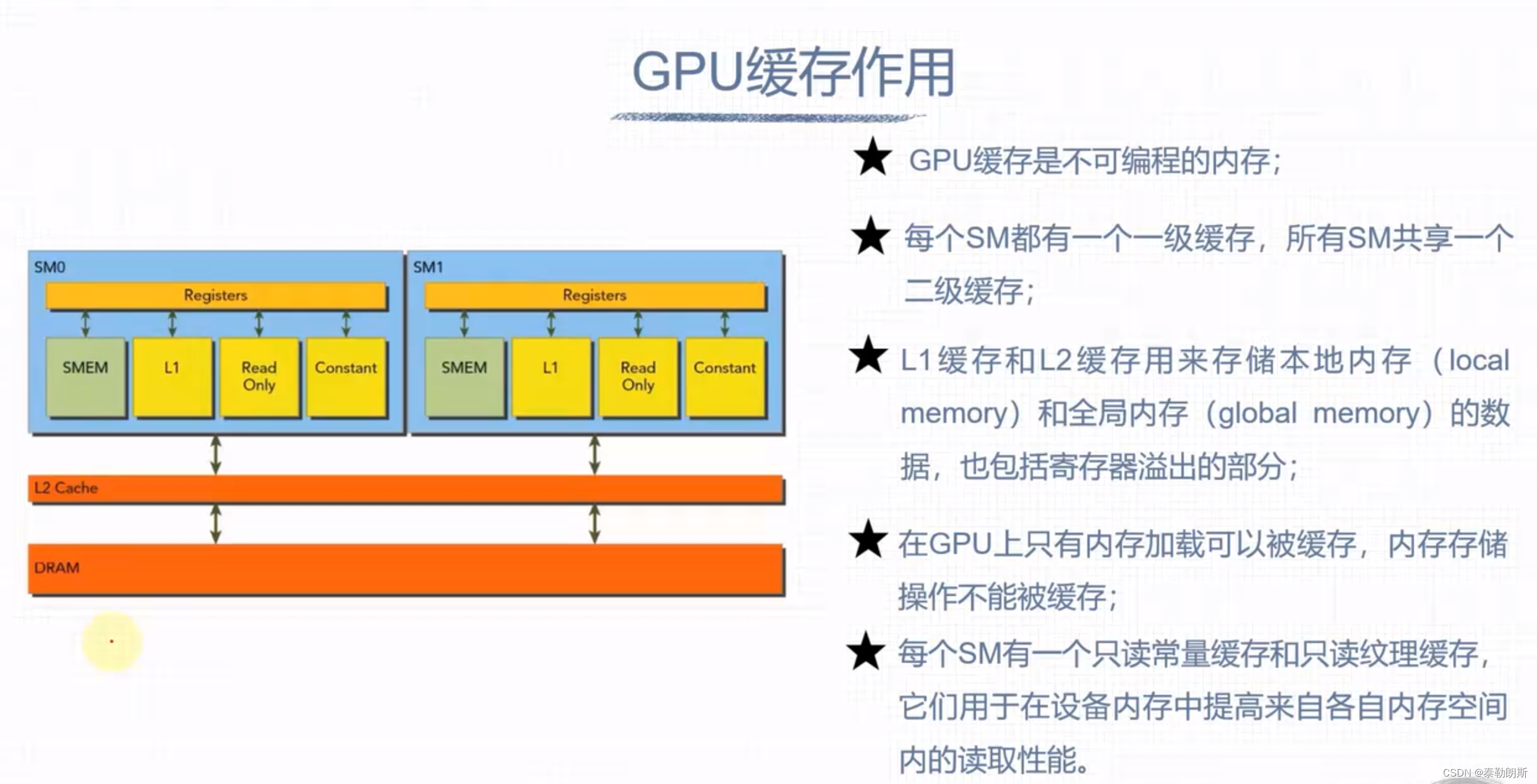
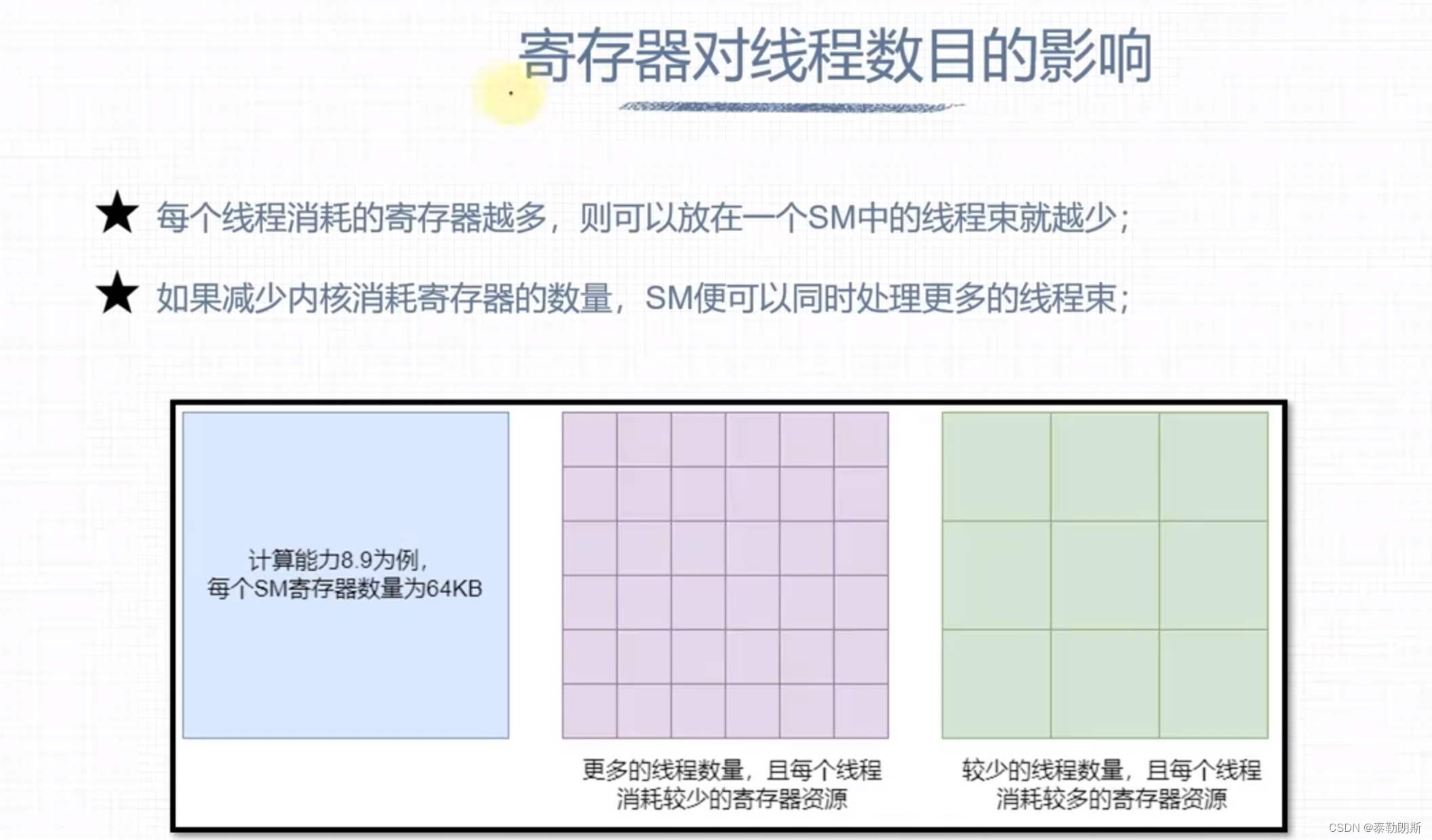
GPU 硬件资源

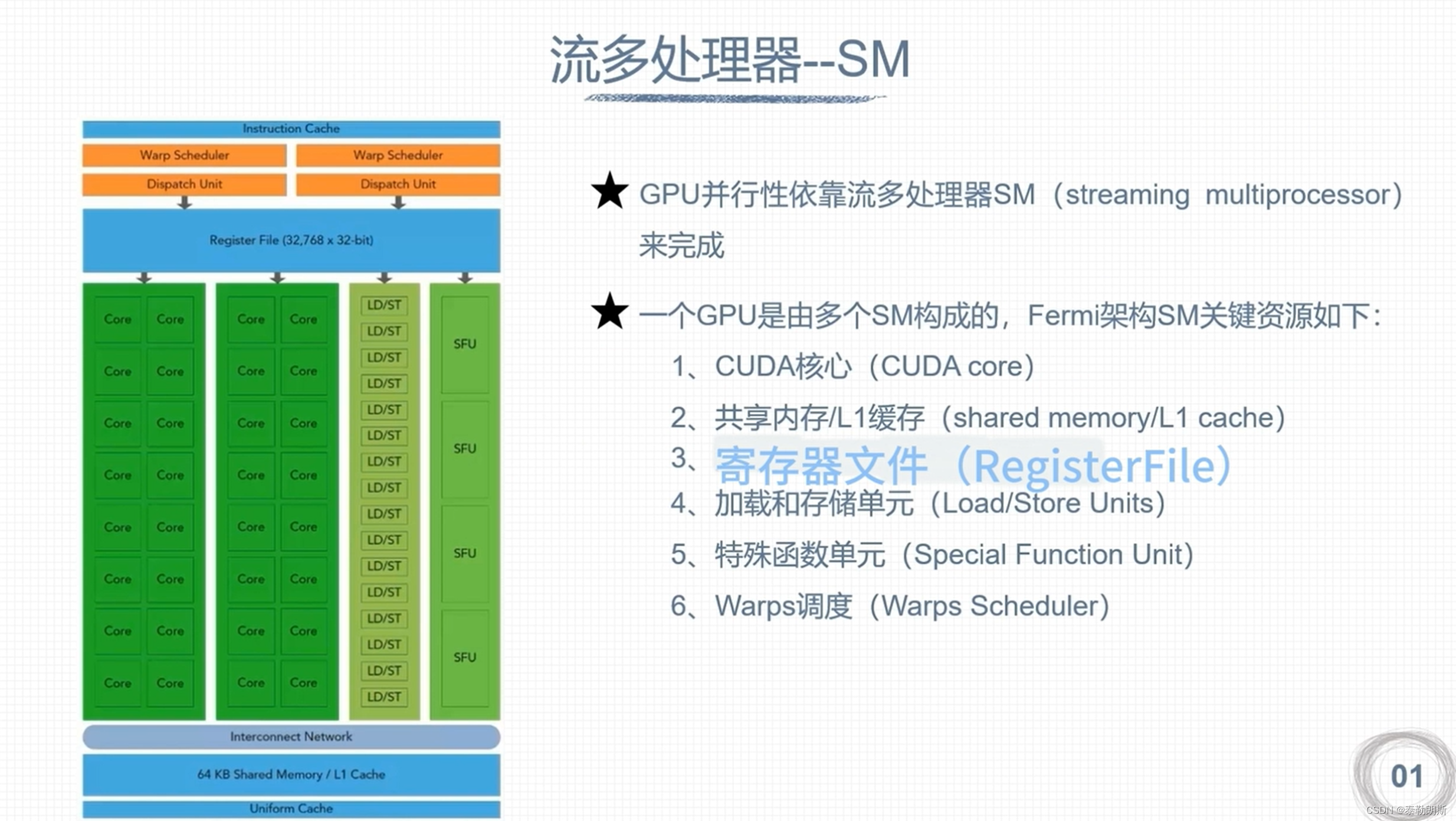
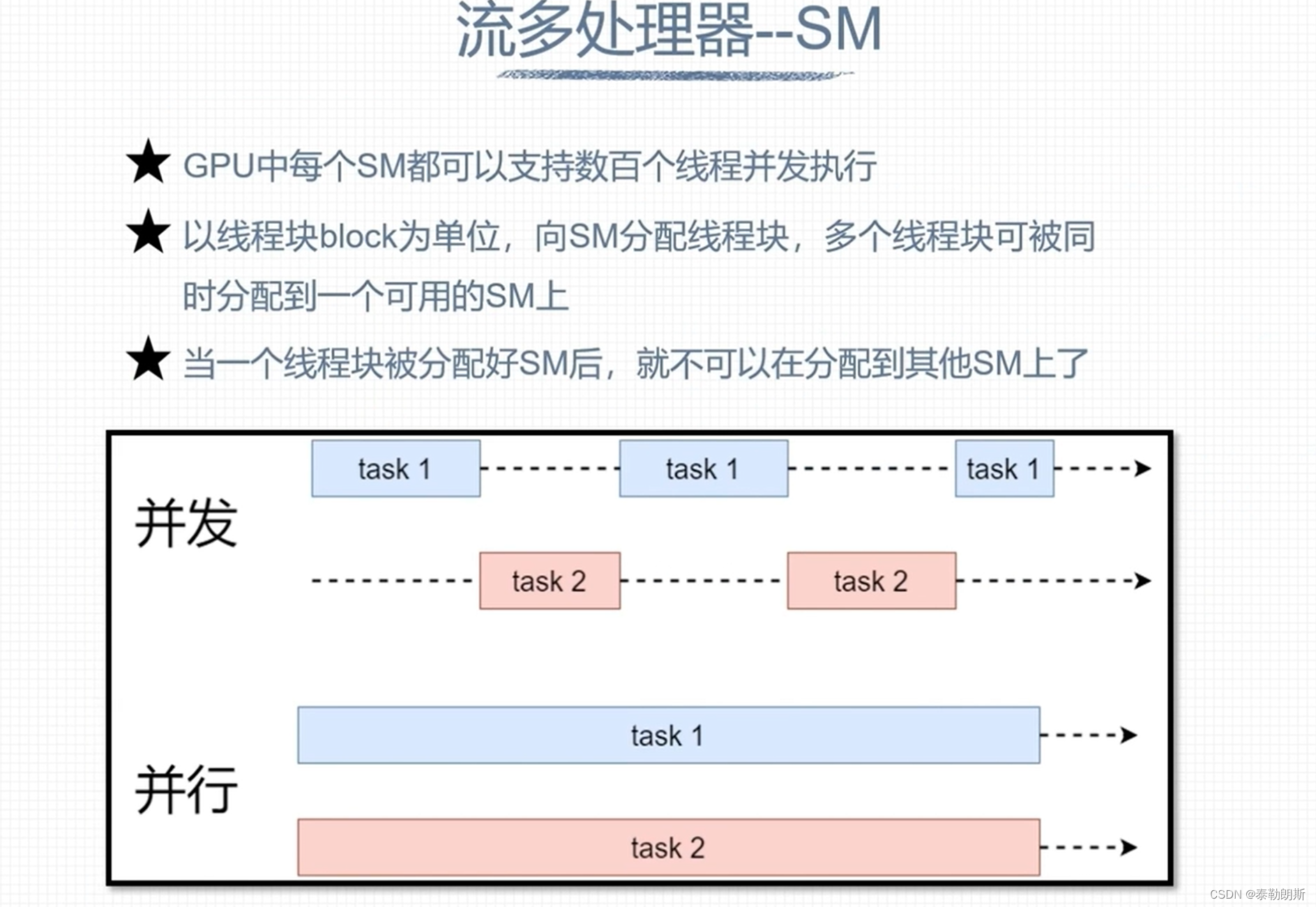
下面注意的是线程是按照block为单位进行分配的
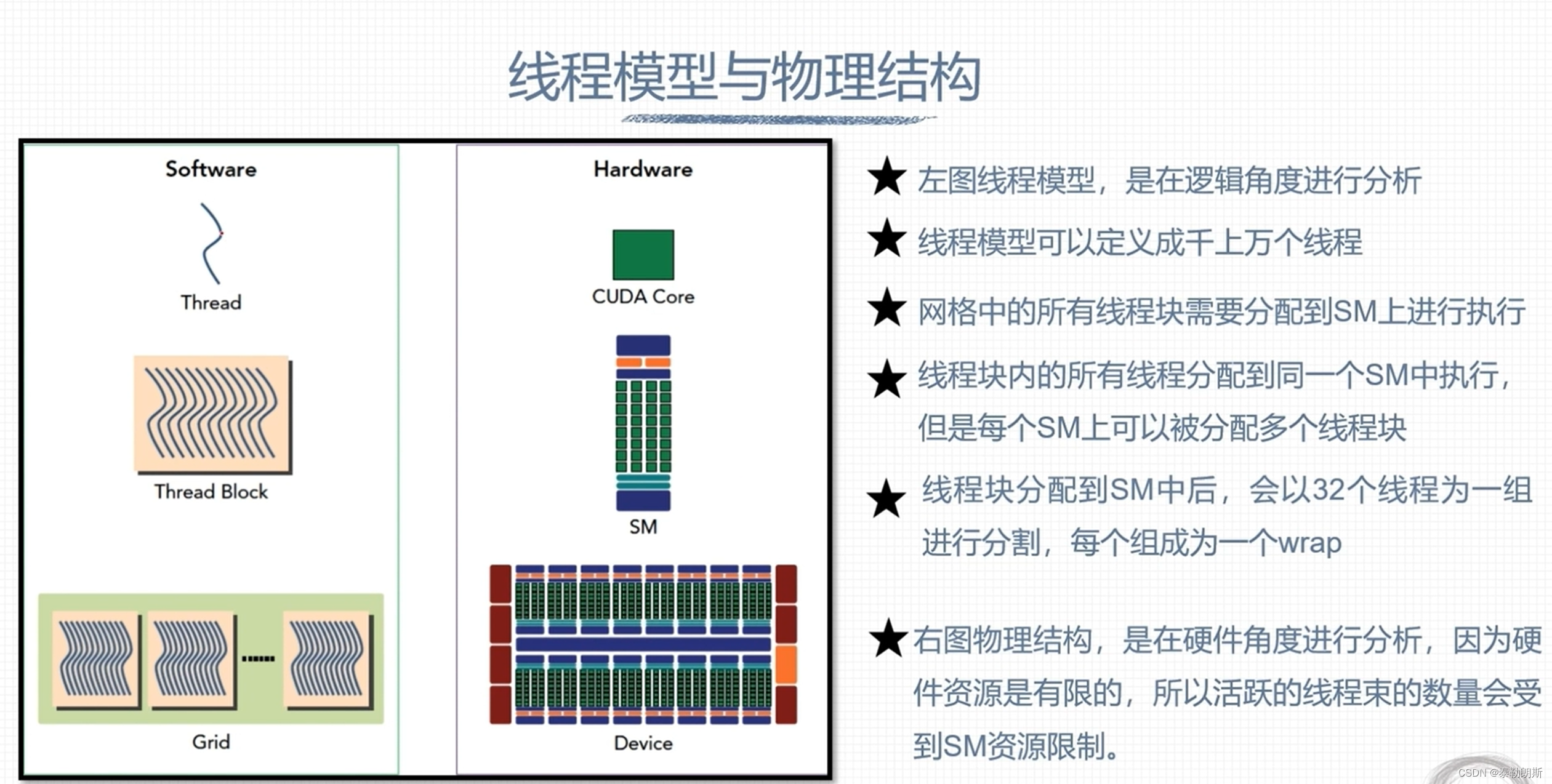

CUDA内存模型

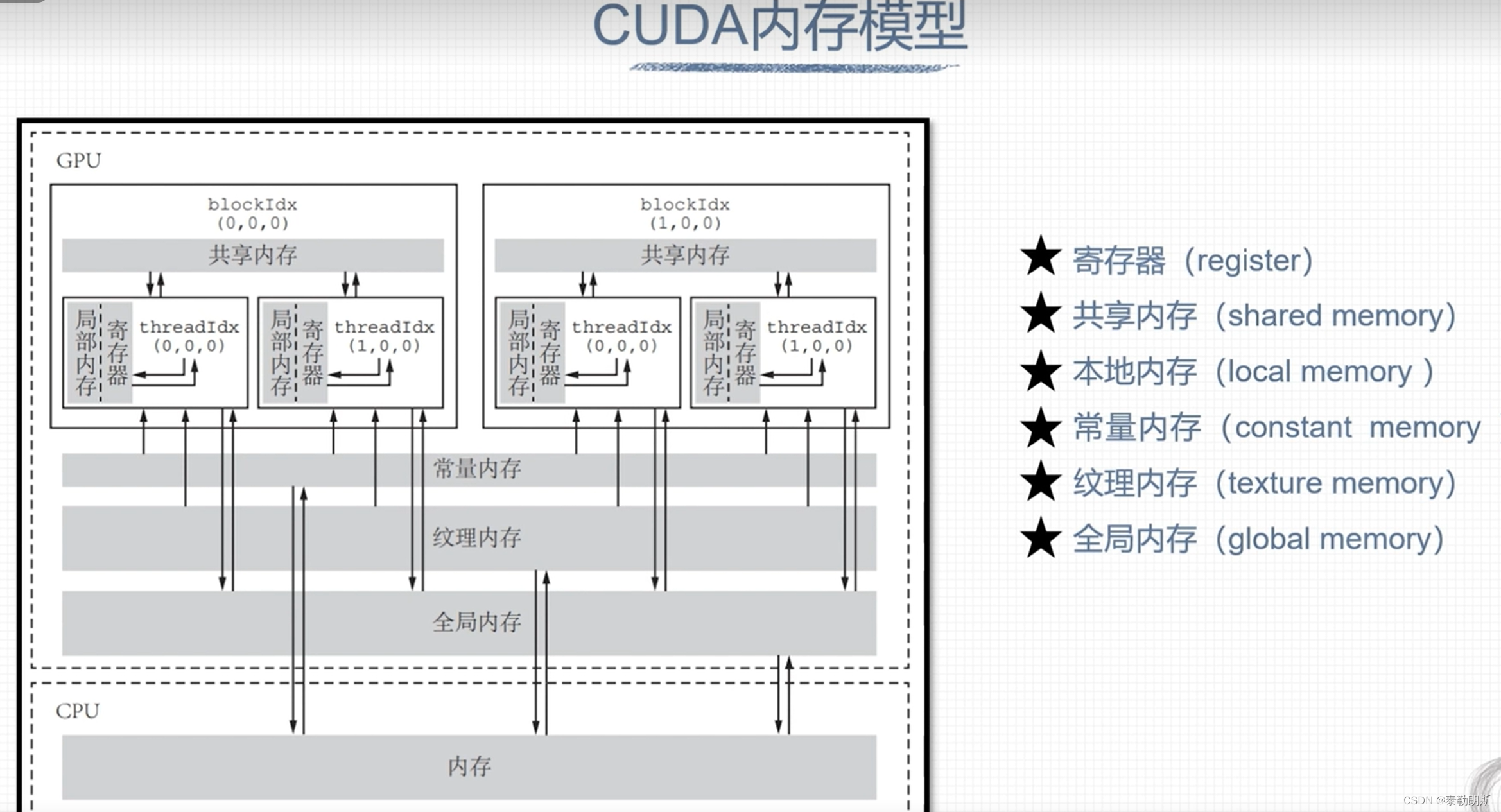
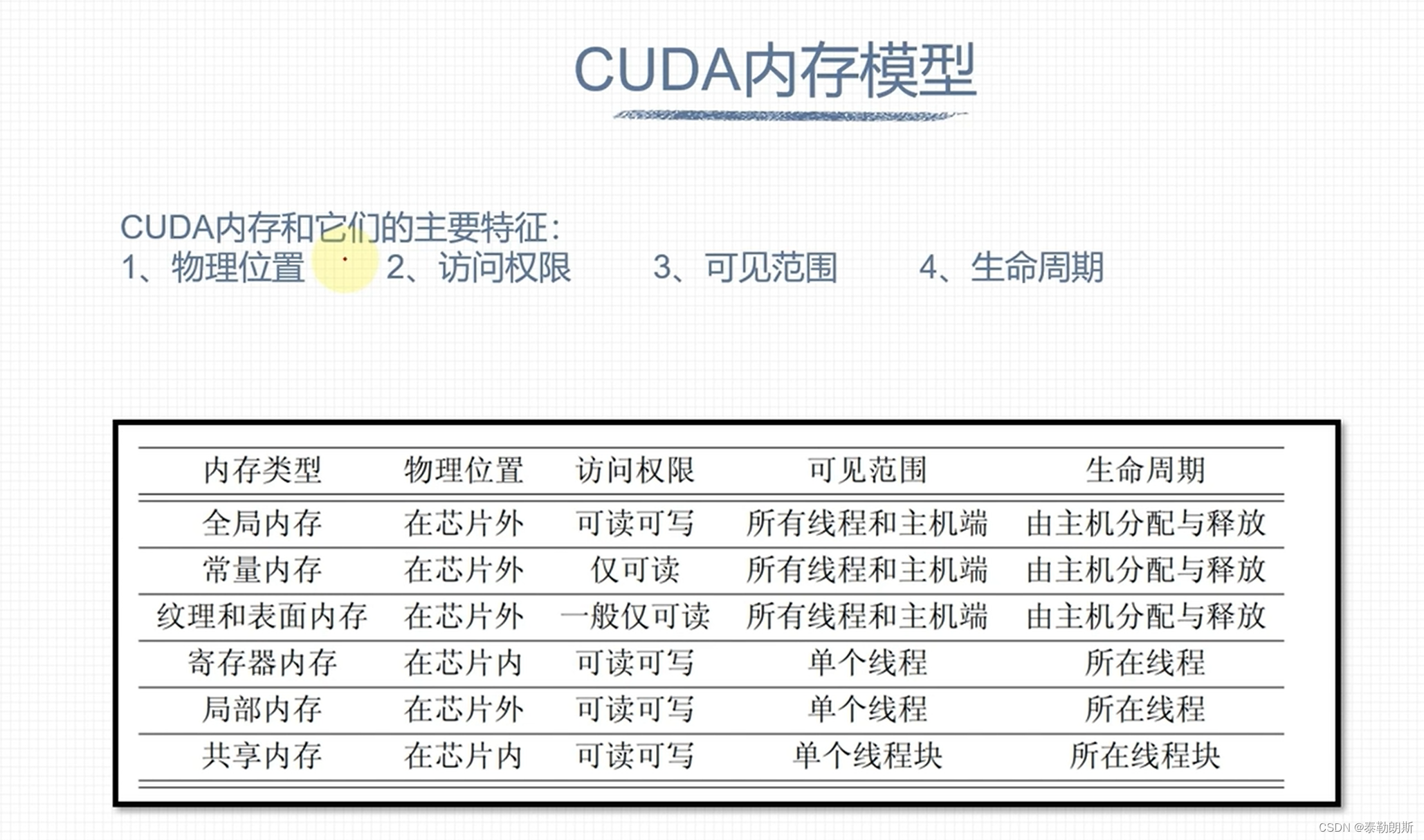
寄存器和本地内存


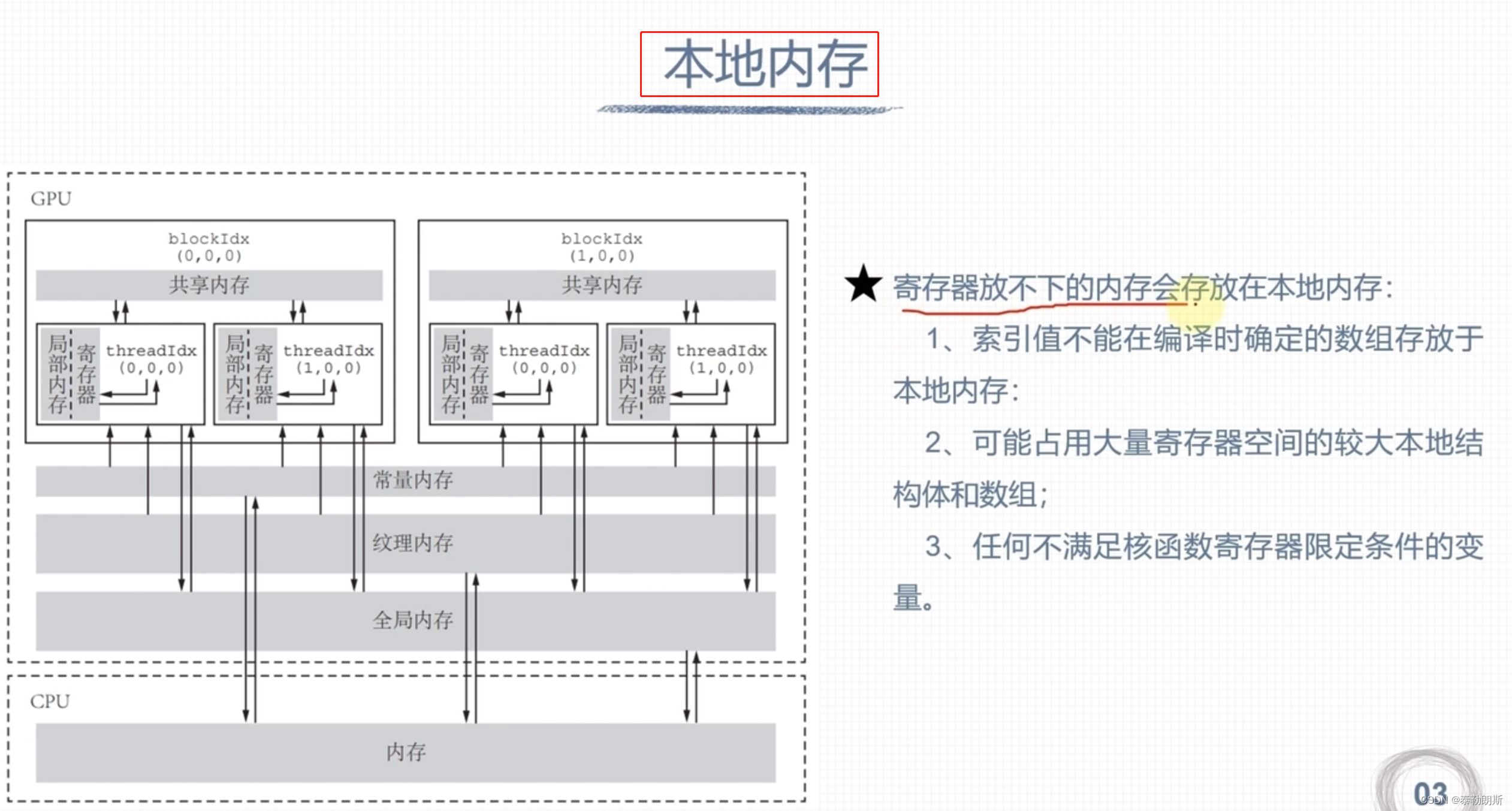


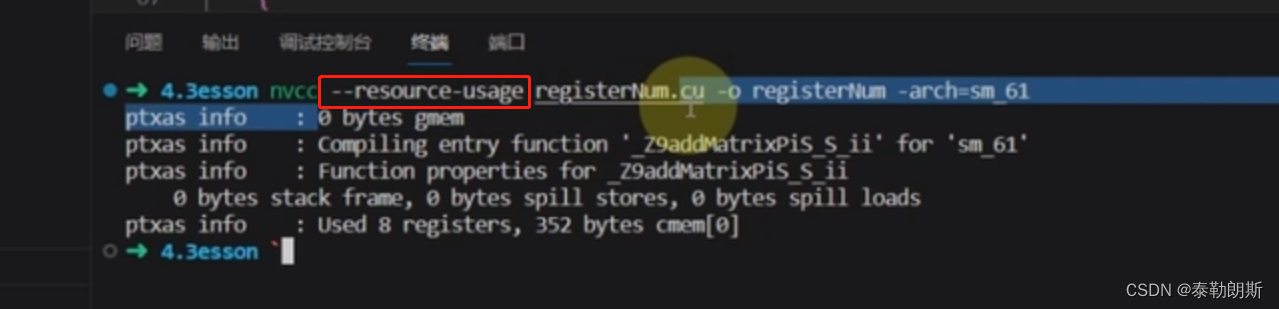
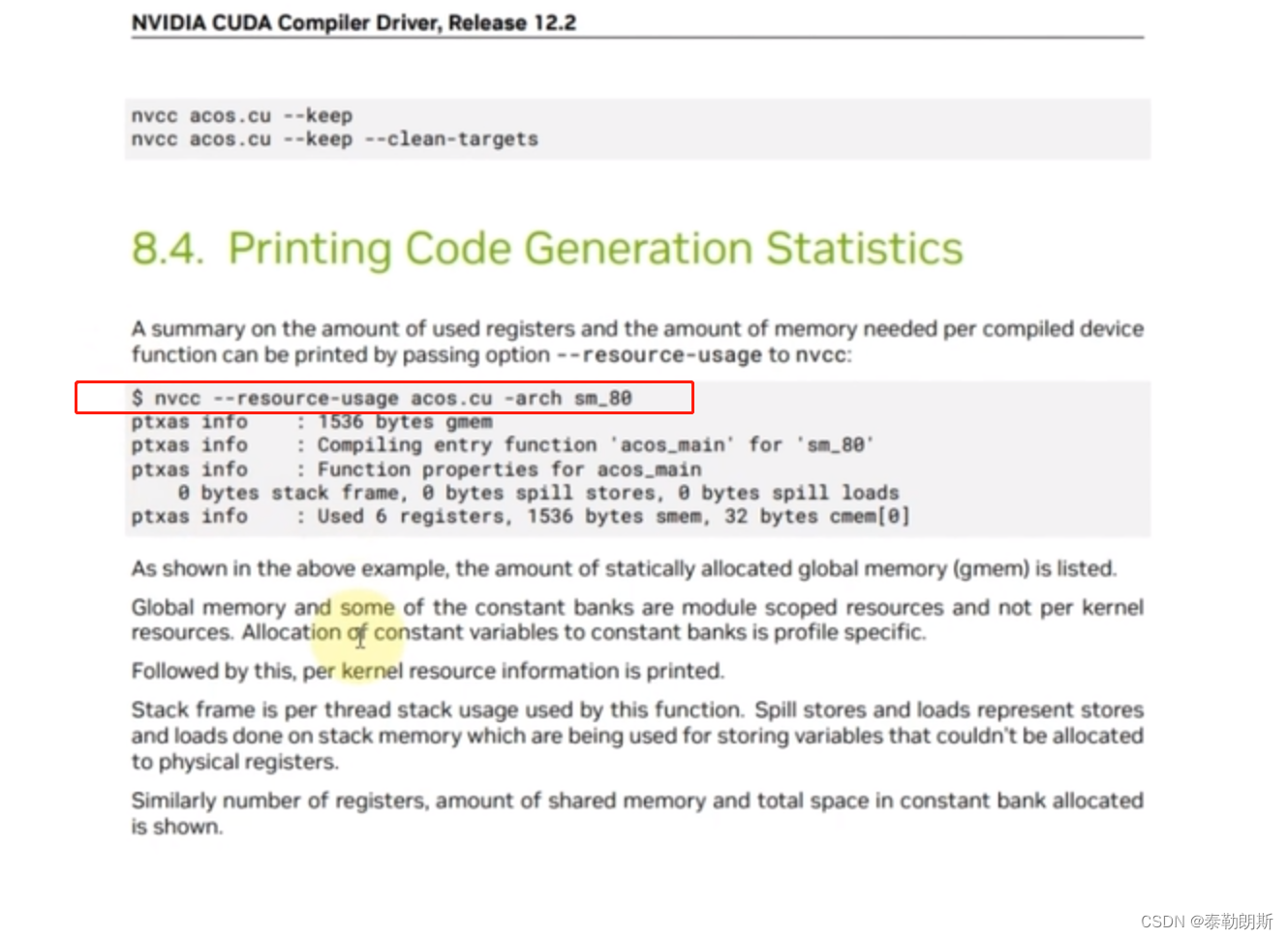
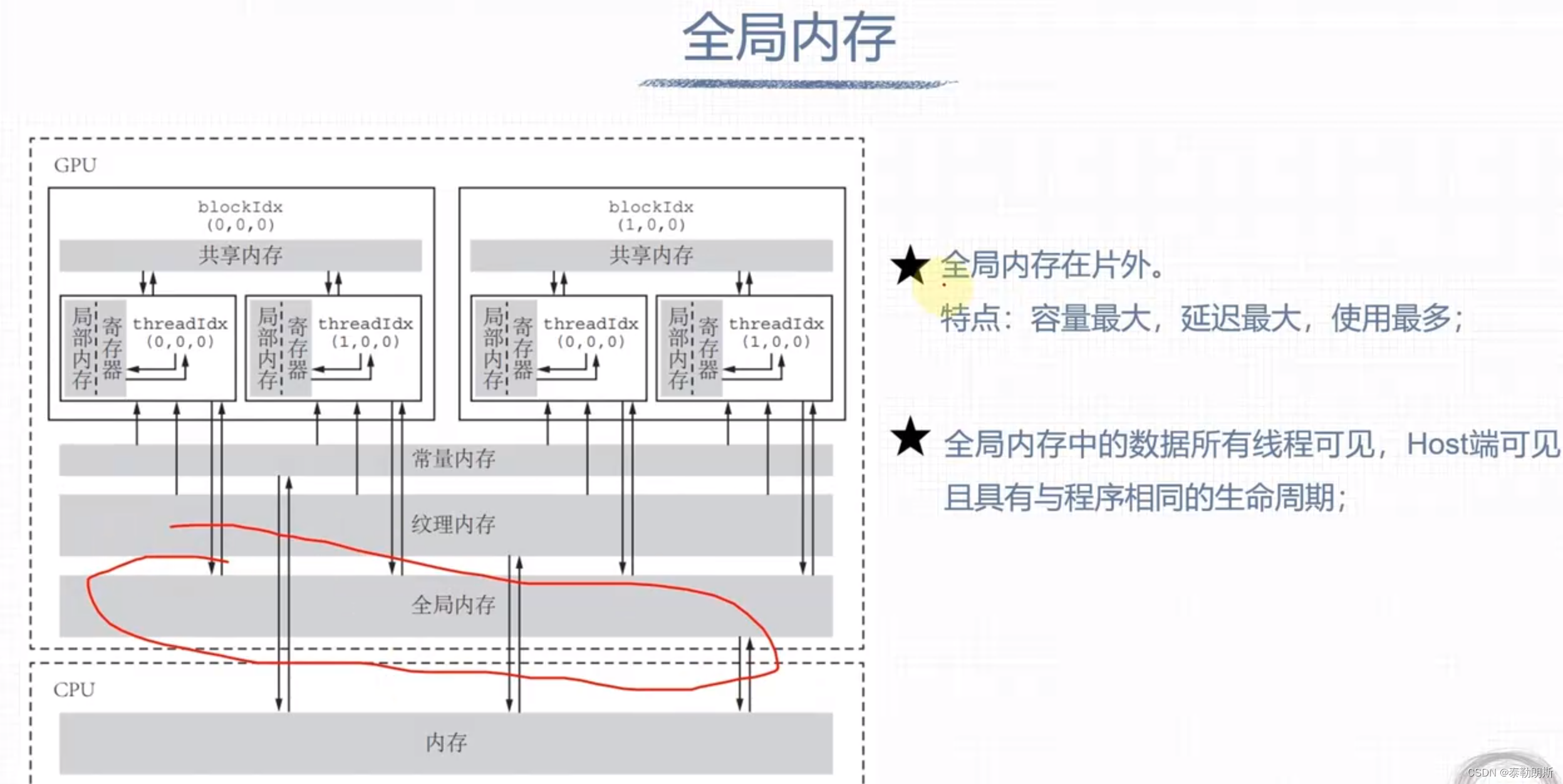
全局内存


#include <cuda_runtime.h>
#include <iostream>
#include "common.cuh"
#define CUDA_CHECK(call) __cudaCheck(call, __FILE__, __LINE__)
#define LAST_KERNEL_CHECK(call) __kernelCheck(__FILE__, __LINE__)
static void __cudaCheck(cudaError_t err, const char* file, const int line) {
if (err != cudaSuccess) {
printf("ERROR: %s:%d, ", file, line);
printf("CODE:%s, DETAIL:%s\n", cudaGetErrorName(err), cudaGetErrorString(err));
exit(1);
}
}
static void __kernelCheck(const char* file, const int line) {
cudaError_t err = cudaPeekAtLastError();
if (err != cudaSuccess) {
printf("ERROR: %s:%d, ", file, line);
printf("CODE:%s, DETAIL:%s\n", cudaGetErrorName(err), cudaGetErrorString(err));
exit(1);
}
}
__device__ int d_x = 1;
__device__ int d_y[2];
__global__ void kernel(void)
{
d_y[0] += d_x;
d_y[1] += d_x;
printf("d_x = %d, d_y[0] = %d, d_y[1] = %d.\n", d_x, d_y[0], d_y[1]);
}
int main(int argc, char **argv)
{
int devID = 0;
cudaDeviceProp deviceProps;
CUDA_CHECK(cudaGetDeviceProperties(&deviceProps, devID));
std::cout << "运行GPU设备:" << deviceProps.name << std::endl;
int h_y[2] = {10, 20};
CUDA_CHECK(cudaMemcpyToSymbol(d_y, h_y, sizeof(int) * 2));
dim3 block(1);
dim3 grid(1);
kernel<<<grid, block>>>();
CUDA_CHECK(cudaDeviceSynchronize());
CUDA_CHECK(cudaMemcpyFromSymbol(h_y, d_y, sizeof(int) * 2));
printf("h_y[0] = %d, h_y[1] = %d.\n", h_y[0], h_y[1]);
CUDA_CHECK(cudaDeviceReset());
return 0;
}
下面是编译cmake
# 最低版本要求
cmake_minimum_required(VERSION 3.20)
# 项目信息
project(global_memory LANGUAGES CXX CUDA)
set(CMAKE_EXPORT_COMPILE_COMMANDS ON)
set(CMAKE_CUDA_STANDARD 14) # 用于指定CUDA编译器应该使用的CUDA C++标准的版本
set(CMAKE_CUDA_STANDARD_REQUIRED ON) # 表明如果找不到指定版本的CUDA编译器,将发出错误
set(CMAKE_CXX_STANDARD 14) # 用于指定 C++ 编译器应该使用的 C++ 标准版本
set(CMAKE_CXX_STANDARD_REQUIRED ON) # 表明如果找不到指定版本的 C++ 编译器,将发出错误
set(CMAKE_CUDA_FLAGS "${CMAKE_CUDA_FLAGS} -O3 -arch=sm_86 --ptxas-options=-v")
# set(CMAKE_CUDA_FLAGS_DEBUG="-G -g -O0")
find_package(CUDA REQUIRED)
if (CUDA_FOUND)
message(STATUS "CUDA_INCLUDE_DIRS: ${CUDA_INCLUDE_DIRS}")
message(STATUS "CUDA_LIBRARIES: ${CUDA_LIBRARIES}")
message(STATUS "CUDA_LIBRARY_DIRS: ${CUDA_LIBRARY_DIRS}")
else()
message(FATAL_ERROR "Cannot find CUDA")
endif()
# 添加可执行文件
add_executable(global_memory global_memory.cu common.cuh)
target_include_directories(global_memory PRIVATE ${CUDA_INCLUDE_DIRS})
# 链接库
target_link_libraries(global_memory PRIVATE ${CUDA_LIBRARIES})

共享内存

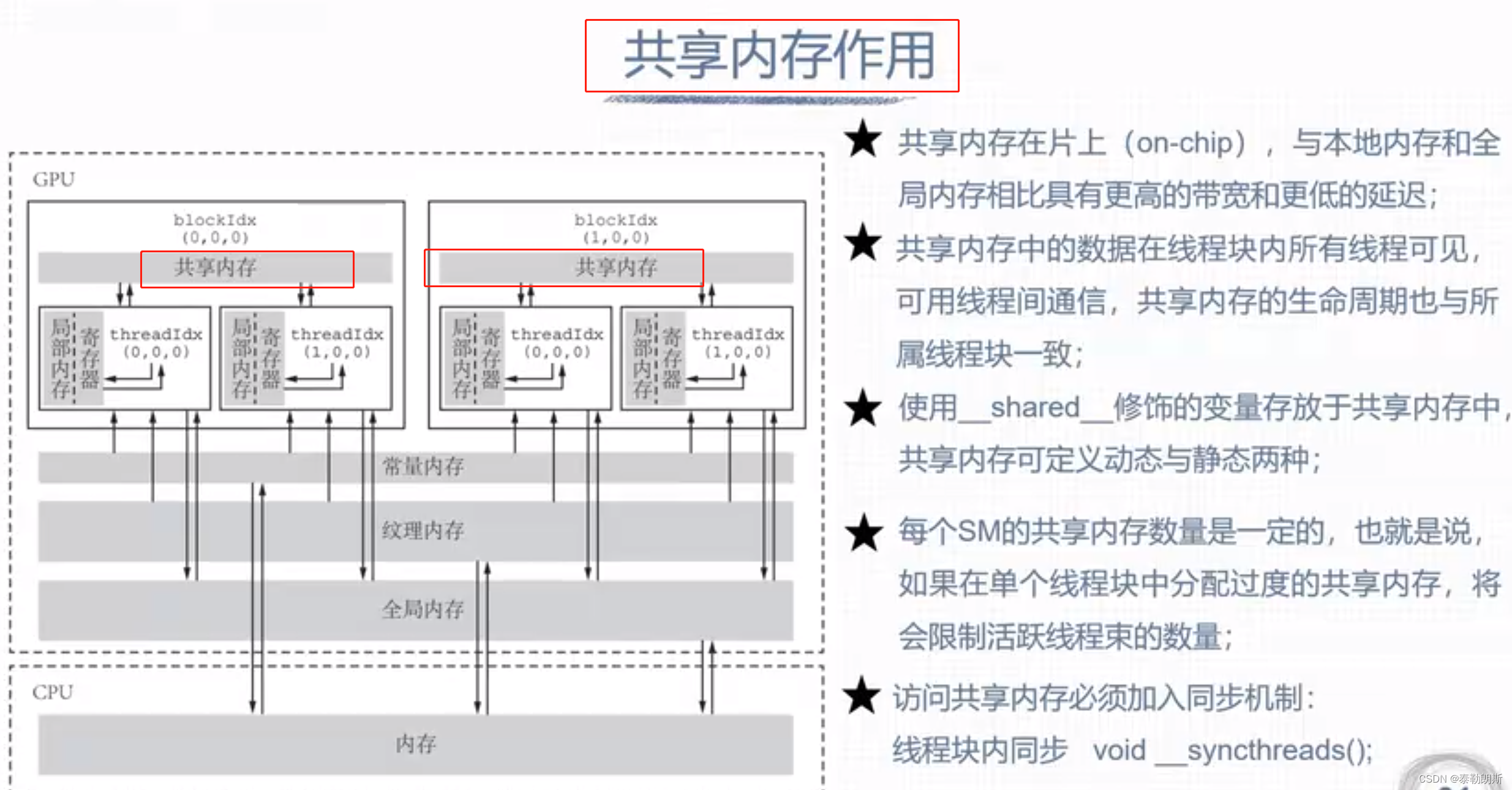
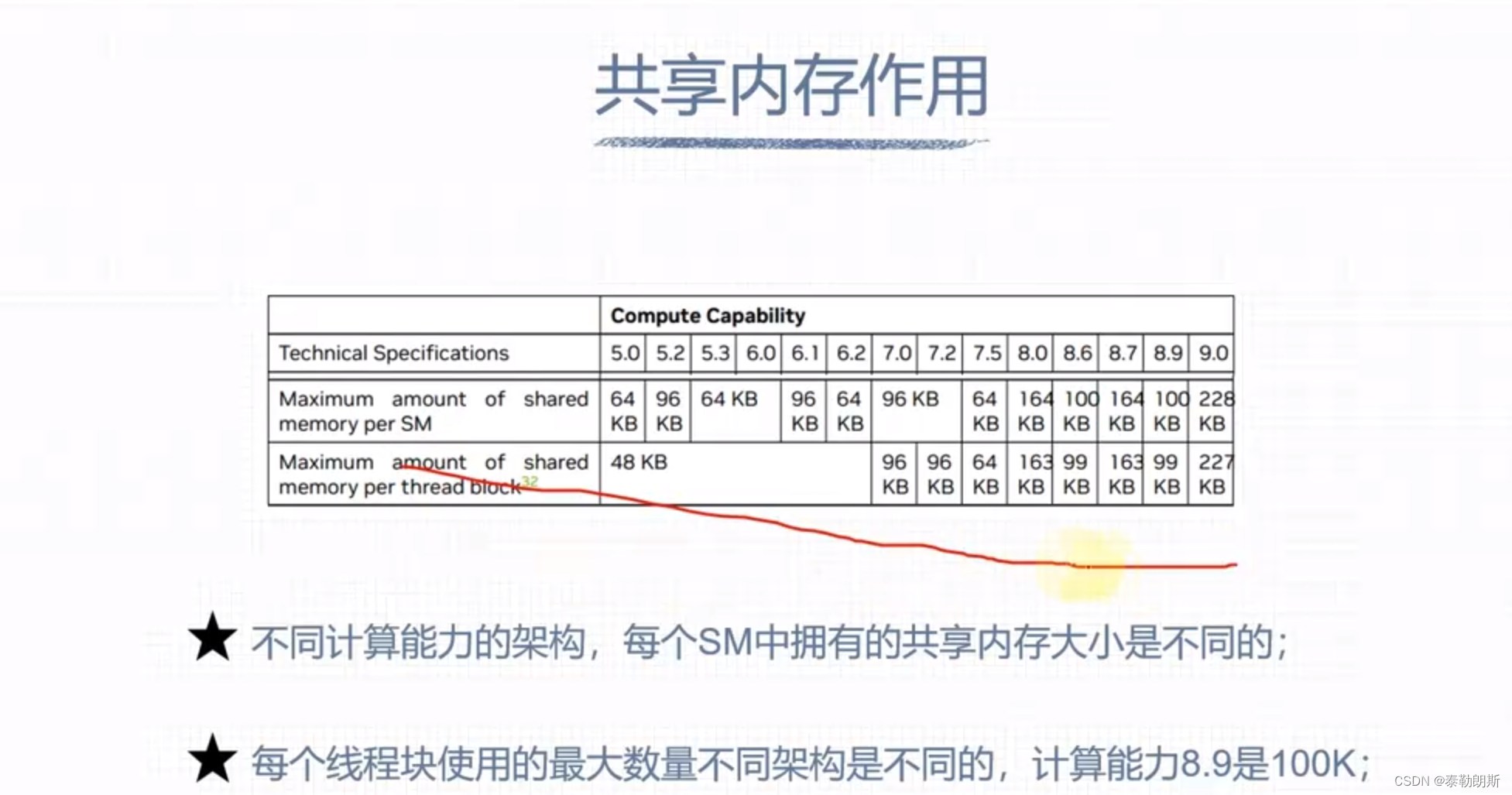


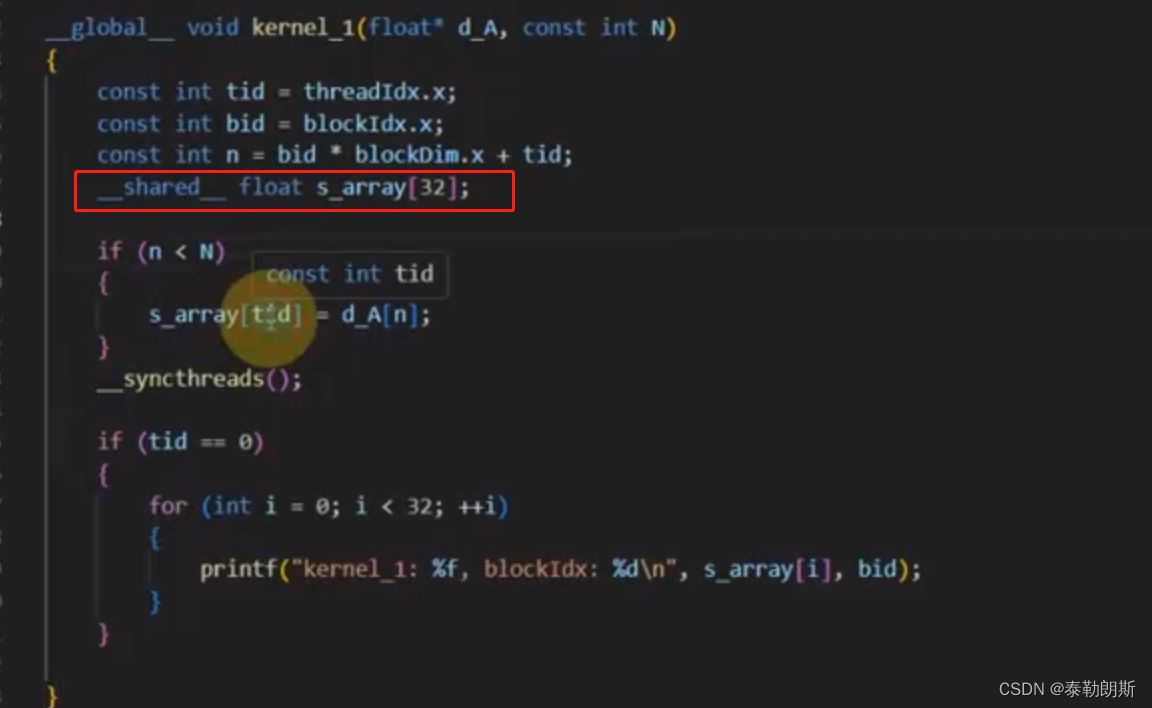
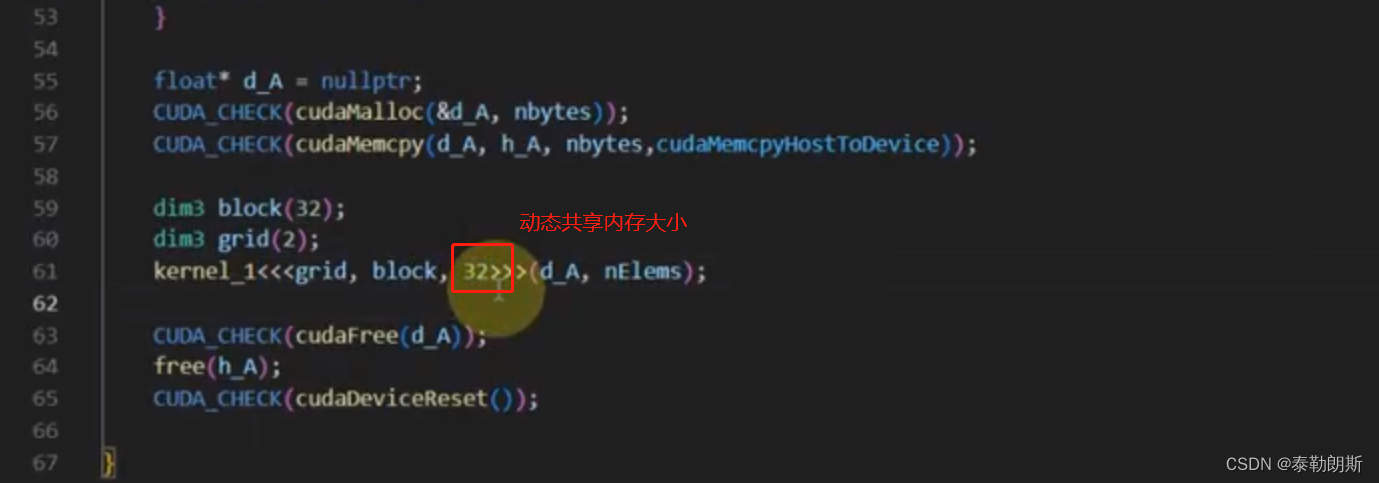
注意上图中s_array大小是32,为什么是32? kernel<<<2,32>>>
另外__synchthreads只能同步一个线程块的线程
#include <cuda_runtime.h>
#include <iostream>
#include "common.cuh"
__global__ void kernel_1(float* d_A, const int N)
{
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int n = bid * blockDim.x + tid;
__shared__ float s_array[32];
if (n < N)
{
s_array[tid] = d_A[n];
}
__syncthreads();
if (tid == 0)
{
for (int i = 0; i < 32; ++i)
{
printf("kernel_1: %f, blockIdx: %d\n", s_array[i], bid);
}
}
}
int main(int argc, char **argv)
{
int devID = 0;
cudaDeviceProp deviceProps;
CUDA_CHECK(cudaGetDeviceProperties(&deviceProps, devID));
std::cout << "运行GPU设备:" << deviceProps.name << std::endl;
int nElems = 64;
int nbytes = nElems * sizeof(float);
float* h_A = nullptr;
h_A = (float*)malloc(nbytes);
for (int i = 0; i < nElems; ++i)
{
h_A[i] = float(i);
}
float* d_A = nullptr;
CUDA_CHECK(cudaMalloc(&d_A, nbytes));
CUDA_CHECK(cudaMemcpy(d_A, h_A, nbytes,cudaMemcpyHostToDevice));
dim3 block(32);
dim3 grid(2);
kernel_1<<<grid, block>>>(d_A, nElems);
CUDA_CHECK(cudaFree(d_A));
free(h_A);
CUDA_CHECK(cudaDeviceReset());
}
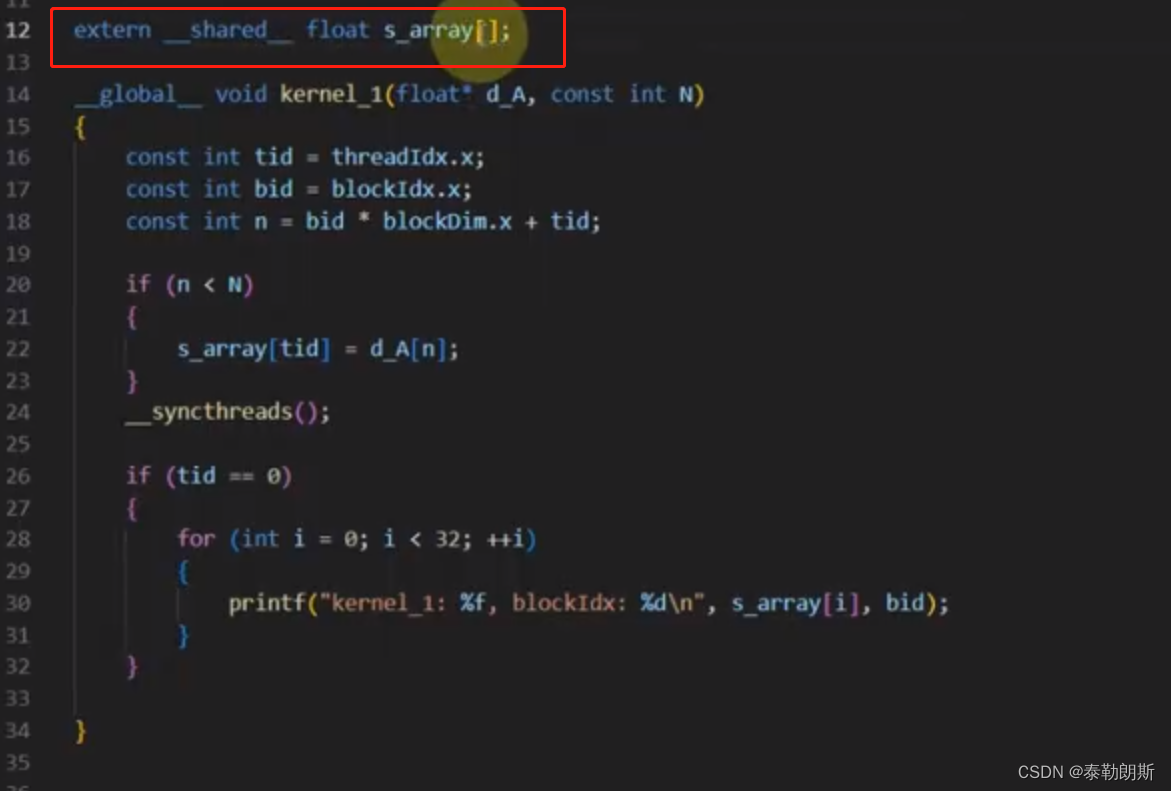
动态共享内存
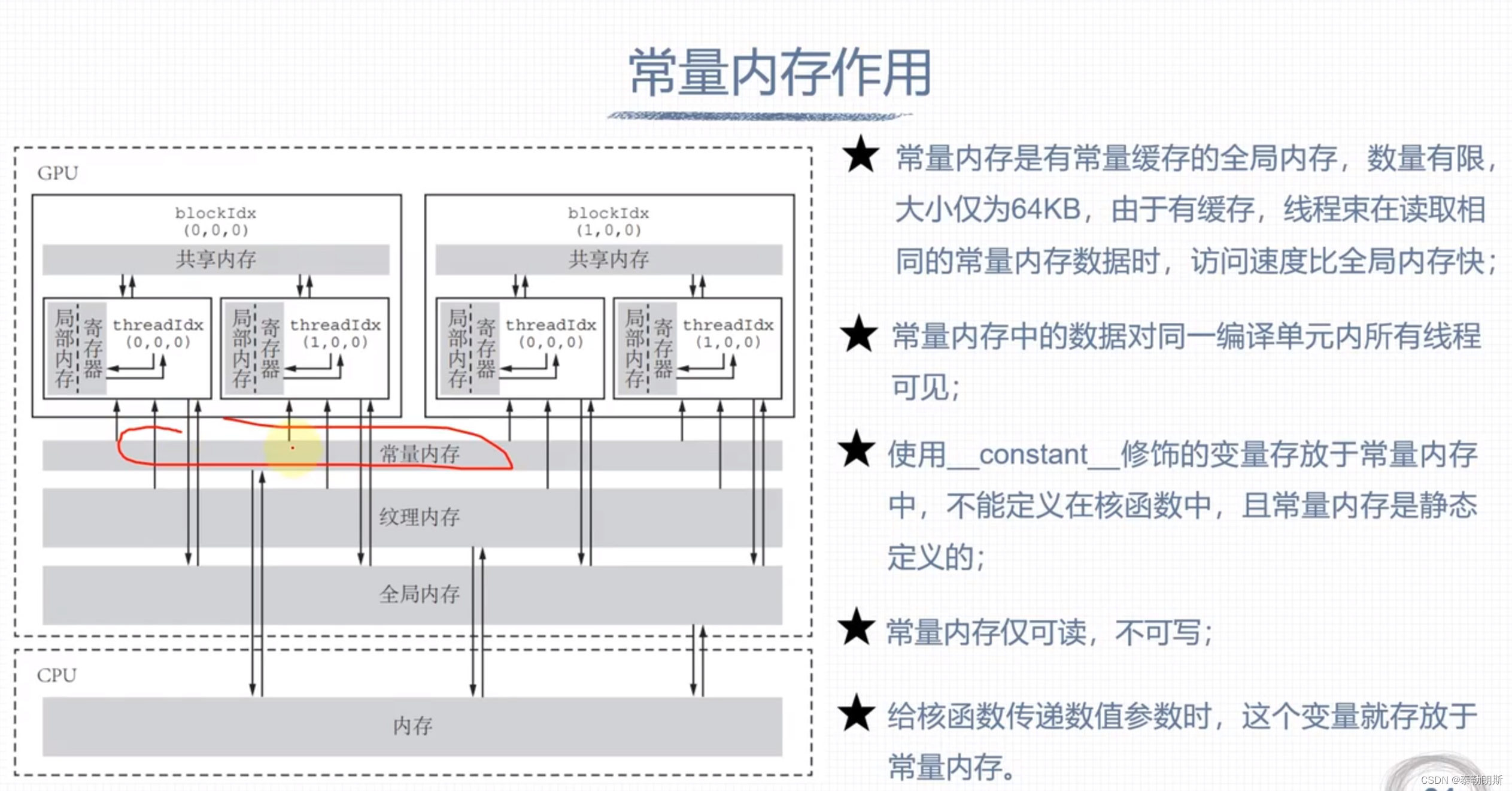
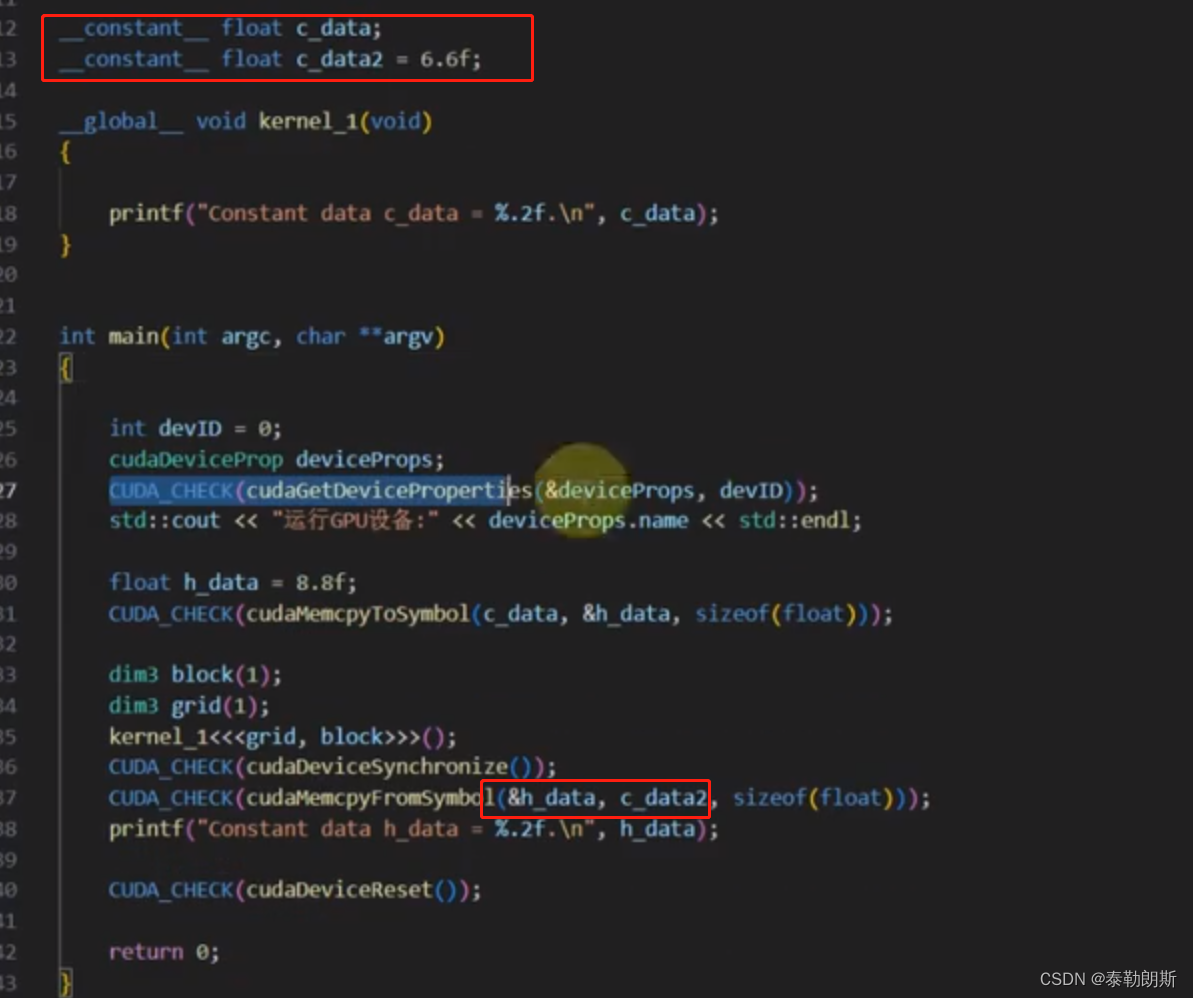
常量内存
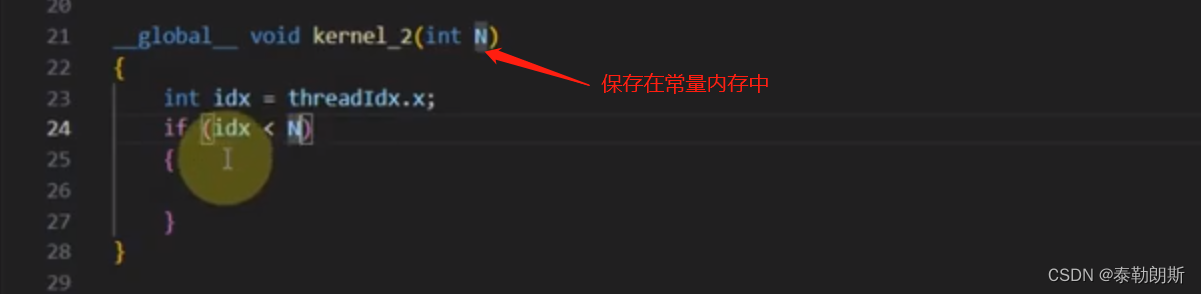

GPU缓存




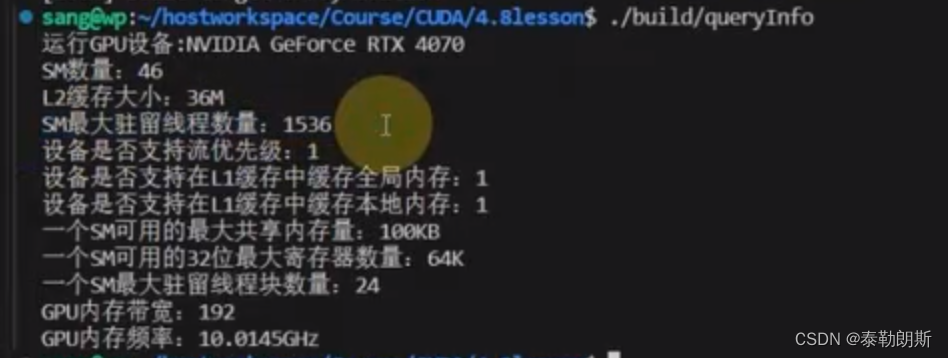
GPU计算资源分配


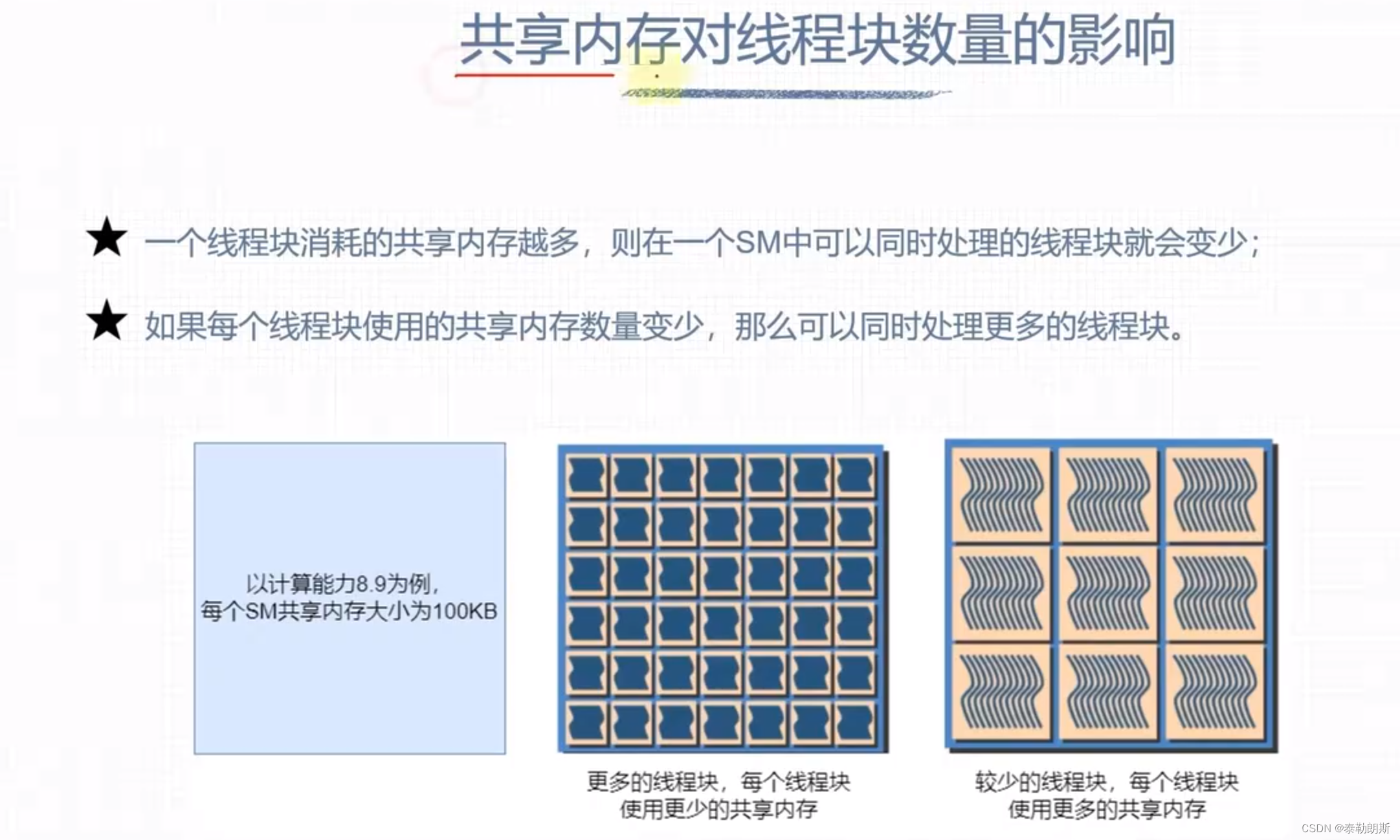

int main(int argc, char **argv)
{
int devID = 0;
cudaDeviceProp deviceProps;
CUDA_CHECK(cudaGetDeviceProperties(&deviceProps, devID));
std::cout << "运行GPU设备:" << deviceProps.name << std::endl;
std::cout << "SM数量:" << deviceProps.multiProcessorCount << std::endl;
std::cout << "L2缓存大小:" << deviceProps.l2CacheSize / (1024 * 1024) << "M" << std::endl;
std::cout << "SM最大驻留线程数量:" << deviceProps.maxThreadsPerMultiProcessor << std::endl;
std::cout << "设备是否支持流优先级:" << deviceProps.streamPrioritiesSupported << std::endl;
std::cout << "设备是否支持在L1缓存中缓存全局内存:" << deviceProps.globalL1CacheSupported << std::endl;
std::cout << "设备是否支持在L1缓存中缓存本地内存:" << deviceProps.localL1CacheSupported << std::endl;
std::cout << "一个SM可用的最大共享内存量:" << deviceProps.sharedMemPerMultiprocessor / 1024 << "KB" << std::endl;
std::cout << "一个SM可用的32位最大寄存器数量:" << deviceProps.regsPerMultiprocessor / 1024 << "K" << std::endl;
std::cout << "一个SM最大驻留线程块数量:" << deviceProps.maxBlocksPerMultiProcessor << std::endl;
std::cout << "GPU内存带宽:" << deviceProps.memoryBusWidth << std::endl;
std::cout << "GPU内存频率:" << (float)deviceProps.memoryClockRate / (1024 * 1024) << "GHz" << std::endl;
CUDA_CHECK(cudaDeviceReset());
return 0;
}


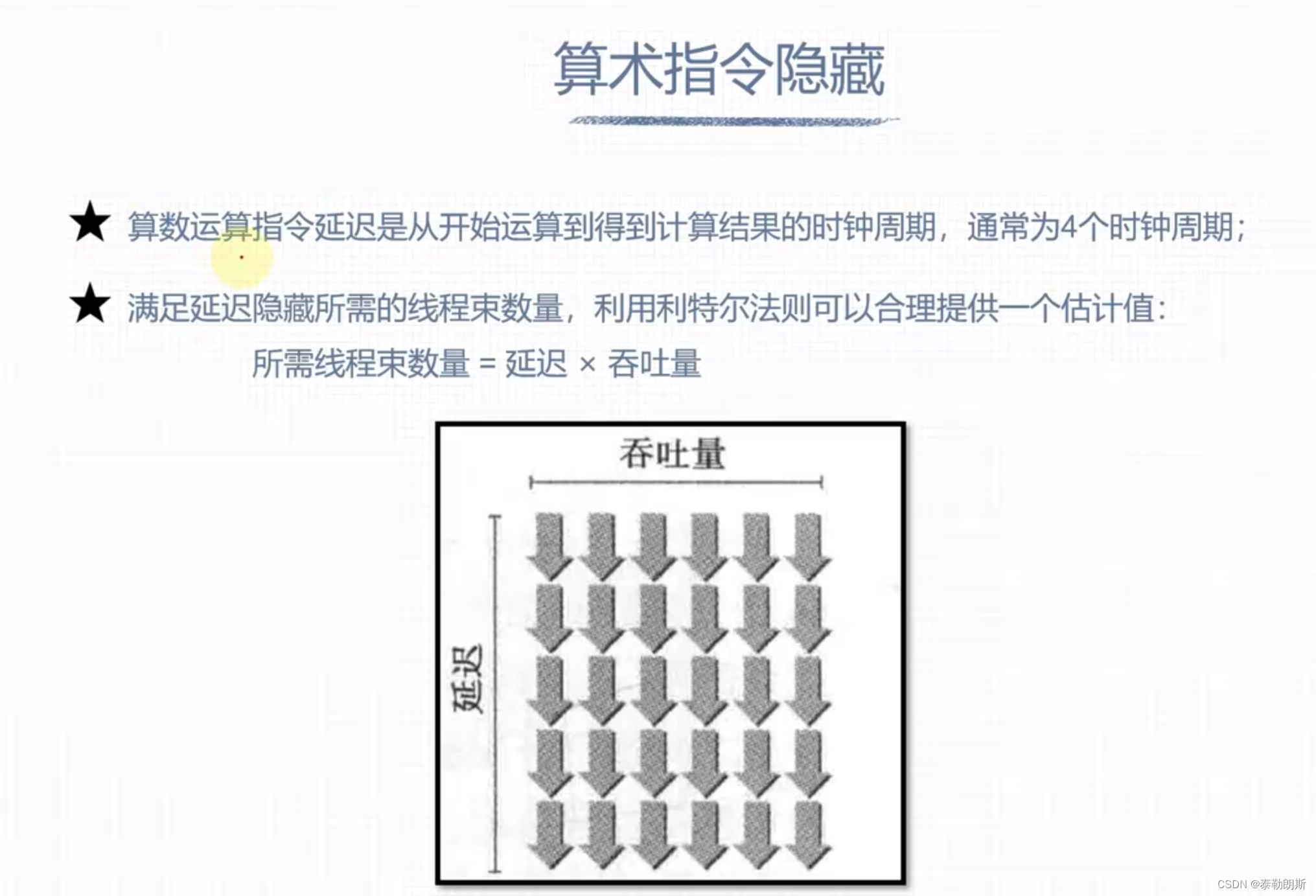
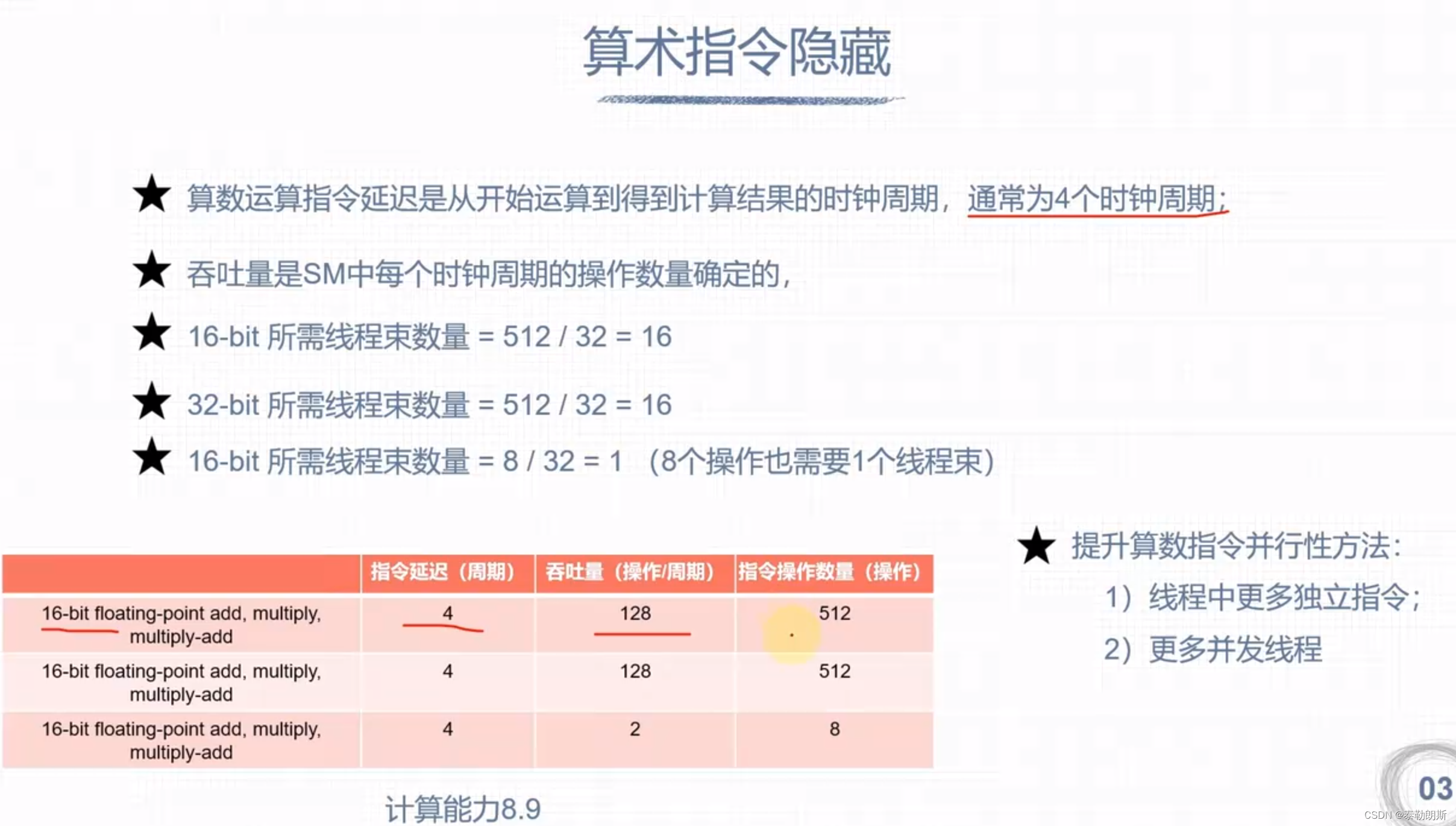
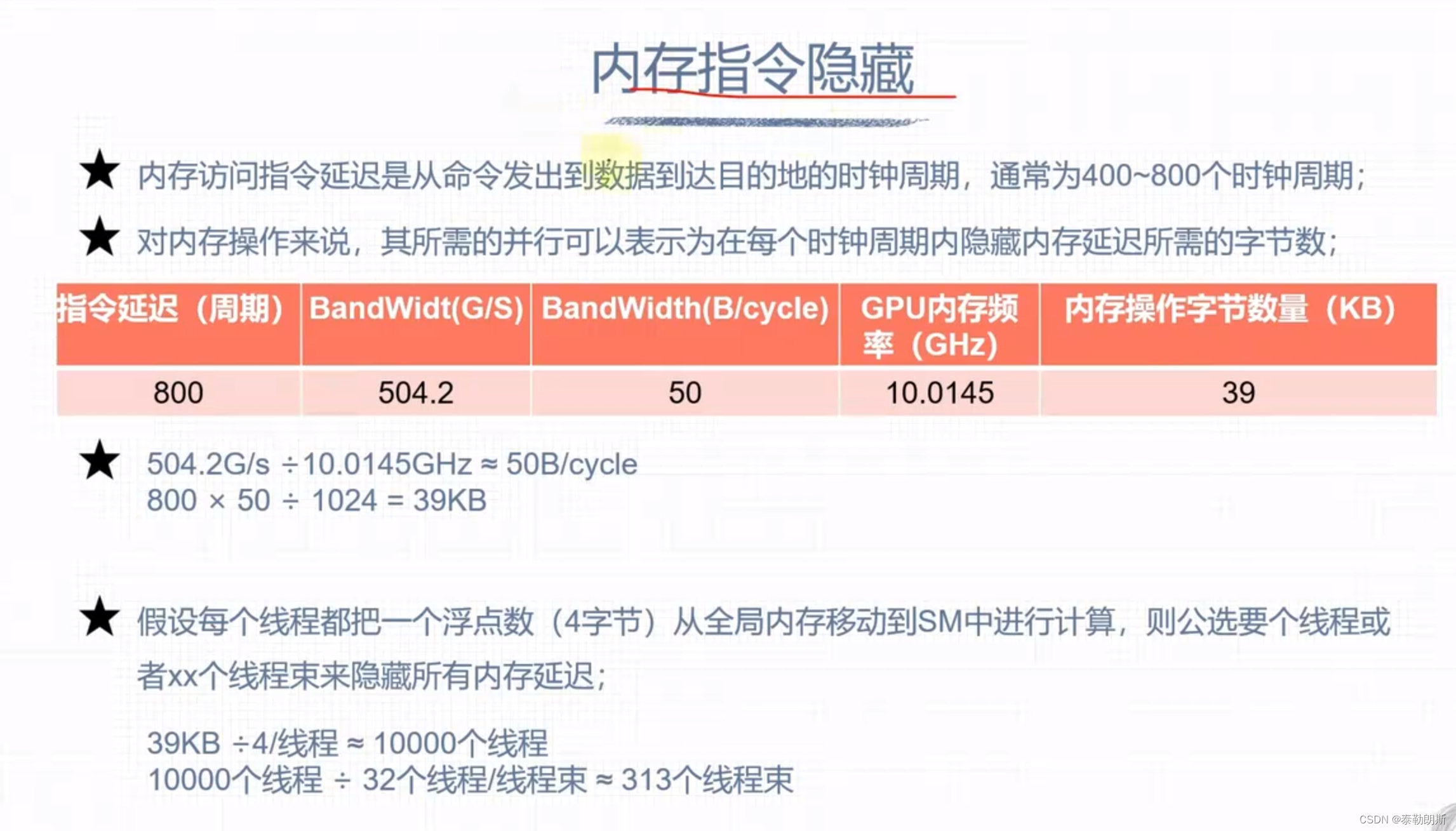
延迟隐藏


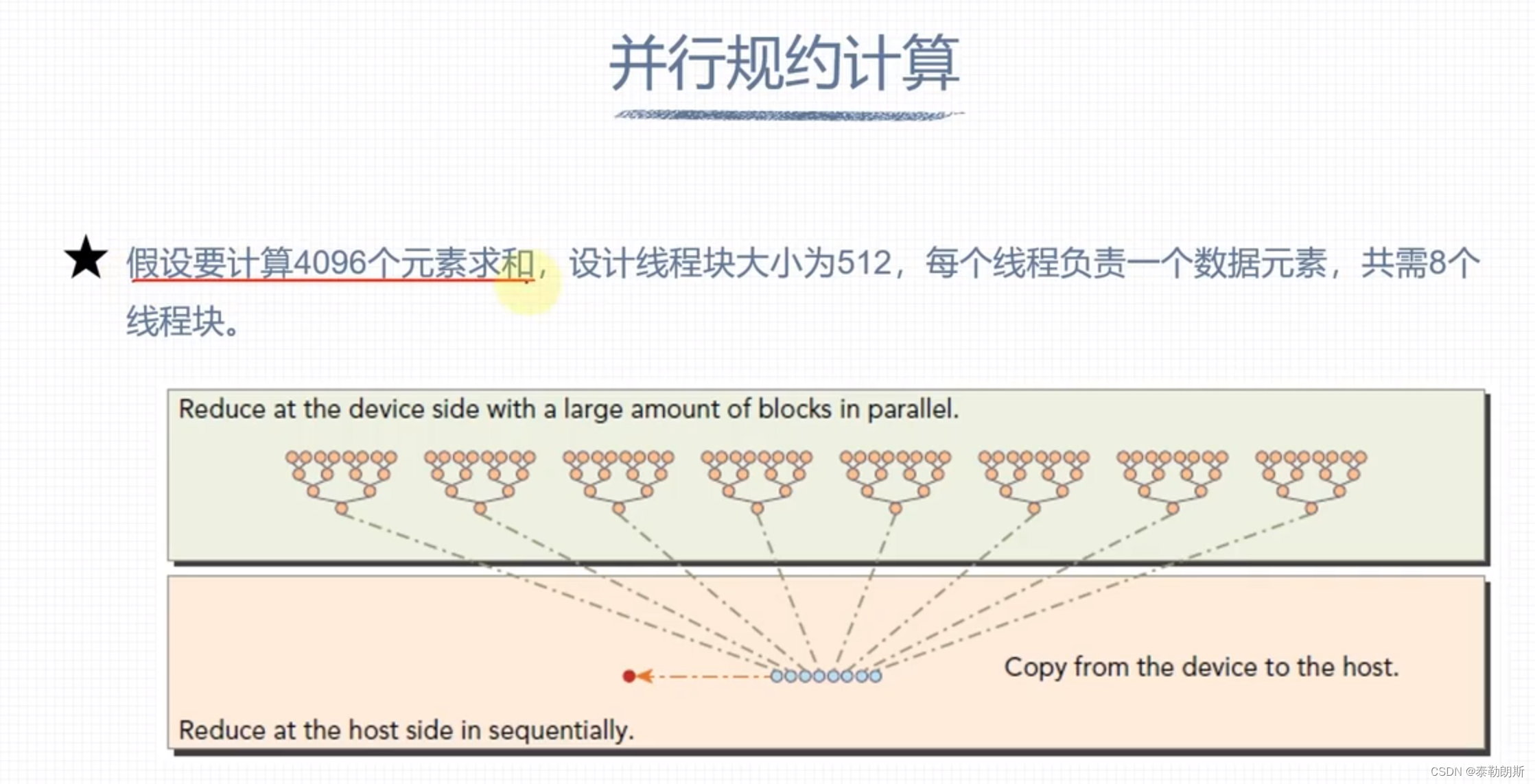
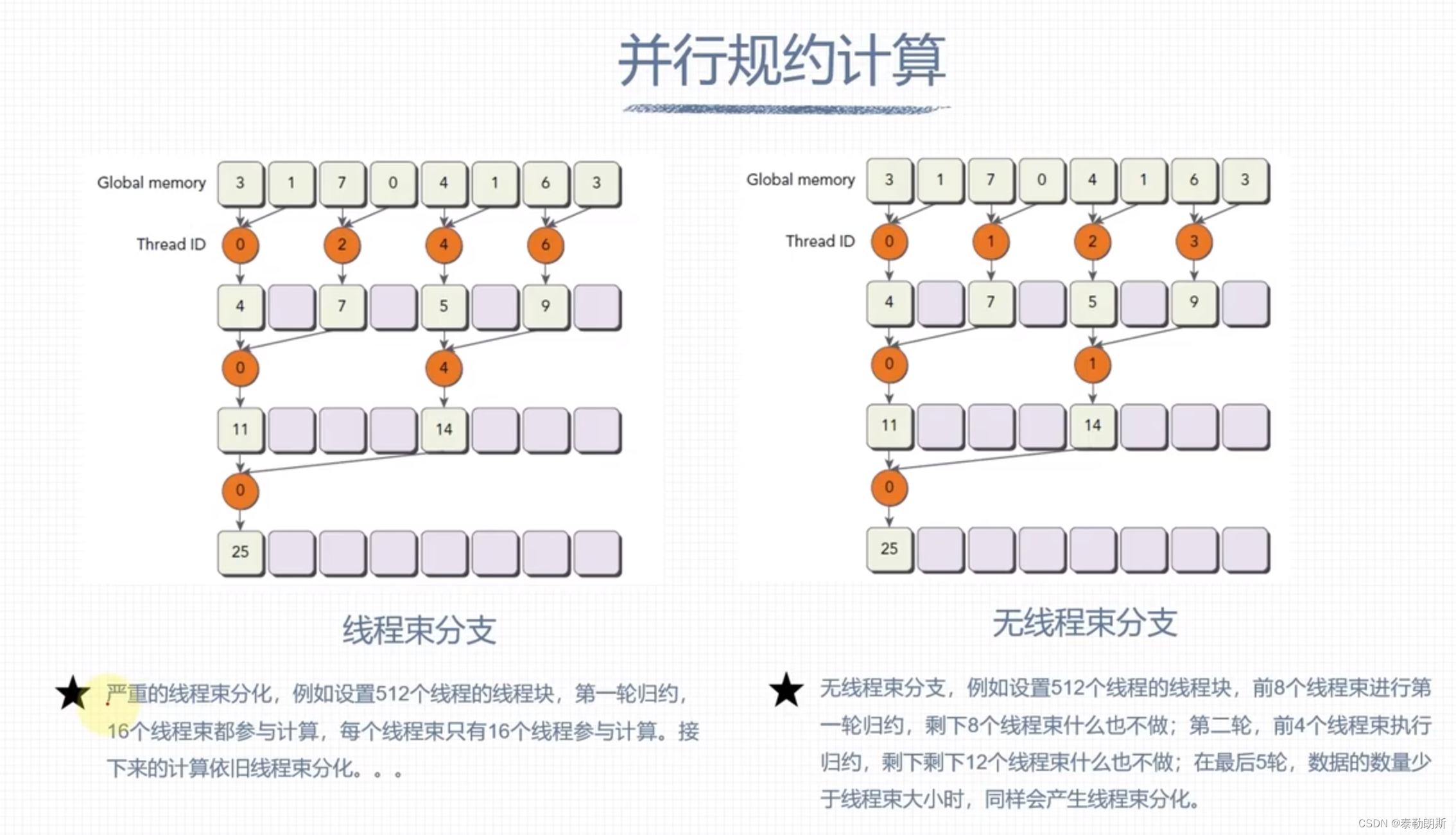
避免线程束分化


















 720
720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}