







yolov7代码仓库:
GitHub - WongKinYiu/yolov7: Implementation of paper - YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors本人认为yolov7有三个重要的配置文件
第一个是cfg→training下面的yolov7配置文件具体见本人写的博客yolov7.yaml文件详解_把爱留给SCI的博客-CSDN博客
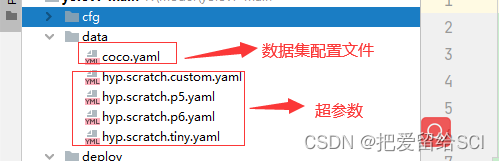
第二个是data文件下的数据相关配置文件和超参数配置文件
train参数详解🚀
1、weights(权重)
parser.add_argument('--weights', type=str, default='yolov7.pt', help='initial weights path')网络权重,默认是'yolov7.pt'可根据需求设置不同尺寸大小的权重
2、cfg(权重的一些重要信息文件)
parser.add_argument('--cfg', type=str, default='yolov7.yaml', help='model.yaml path')指定模型配置文件路径的;源码里面提供了几个配置文件,配置文件里面指定了一些参数信息和backbone的结构信息。
3、data(数据)
# COCO 2017 dataset http://cocodataset.org
# download command/URL (optional)
download: bash ./scripts/get_coco.sh
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ./coco/train2017.txt # 118287 images
val: ./coco/val2017.txt # 5000 images
test: ./coco/test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# number of classes
nc: 80
# class names
names: [ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush' ]里面核心信息是数据集的种类以及每个种类对应的名称
4、hyp(超参数)
里面包含了超参数的信息
5、 epochs(训练的代数)
parser.add_argument('--epochs', type=int, default=300)一般默认为300轮
6、batch-size
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')每批次的输入数据量;default=-1将时自动调节batchsize大小,default=16,代表一次输入16张图片进行训练。
7、img-size
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')训练集和测试集输入的图片像素大小
8、rect
parser.add_argument('--rect', action='store_true', help='rectangular training')是否采用矩阵推理的方式去训练模型
采用矩阵推理的话就不要求送入的训练的图片是正方形了
9、resume(断点训练)
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')断点续训:即是否在之前训练的一个模型基础上继续训练,default 值默认是 false
假如你想进行断点训练,那就先将default=True
随后输入
python train.py --resume +训练的模型保存的路径10、nosave
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')是否保存最后一轮的pt文件,我们默认保存的是best.pt和last.pt
11、notest
parser.add_argument('--notest', action='store_true', help='only test final epoch')只在最后一轮计算mAP值;在我们平时的训练中我们在每一轮训练结束的时候都会计算mAP值,如果开始此参数,那么只在最后一轮计算mAP值。不建议动此参数
12、noautoanchor
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')是否禁用自动锚框;默认是开启的,可以简化训练过程;
在这里解释一下anchor
人工标注的边框(bounding box,有时简写bbox 或者 box)是人告诉机器的正确答案叫ground truth bounding box,简写 gt bbox或者gt box,表示已知正确的意思。
程序生成的一堆box,想要预测正确的gt box,这些生成的box叫anchor。
在这里介绍两个指标
bpr(best possible recall)
aat(anchors above threshold)
当配置文件中的anchor计算bpr(best possible recall)小于0.98时才会重新计算anchor。
best possible recall最大值1,如果bpr小于0.98,程序会根据数据集的label自动学习anchor的尺寸
13、evolve
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')超参数进化,模型提供的默认参数是通过在COCO数据集上使用超参数进化得来的(由于超参数进化会耗费大量的资源和时间,如果默认参数训练出来的结果能满足你的使用,使用默认参数也是不错的选择)
14、bucket
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')谷歌云盘;通过这个参数可以下载谷歌云盘上的一些东西。
15、cache-images
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')是否提前缓存图片到缓存,以加快训练速度,默认为False
16、image-weights
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')是否启用加权训练图像,默认为Flase,主要为了解决样本图片不平衡问题;开启后会对上一轮训练不好的图片,在下一轮中增加权重。
17、device
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')训练模型的设备,大佬们才会用的参数
18、multi-scale
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')采用多尺度训练,默认是False,设置几种不同的图片输入尺度,训练时每隔一定的ierations随机选取一种尺度训练
19、single-cls
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')设定训练的数据集是单类别还是多类别,默认为多类别
20、adam
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')选用Adam优化器
21、sync-bn
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')同步Batch Normalization,是否跨多设备进行Batch Normalization
22、local_rank
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')DDP参数,请勿修改
使用DDP进行单机多卡训练时,通过多进程在多个GPU上复制模型,每个GPU都由一个进程控制,同时需要将参数local_rank传递给进程,用于表示当前进程使用的是哪一个GPU。
详情见:PyTorch单机多卡训练(DDP-DistributedDataParallel的使用)备忘记录_Curya的博客-CSDN博客
23、workers
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')指数据装载时cpu所使用的线程数,默认为8。
在这里说一下和batch--size的区别,batch--size是指训练一组放入多少张照片,消耗的是GPU
此参数workers消耗的是CPU
24、project
parser.add_argument('--project', default='runs/train', help='save to project/name')训练模型存放的路径
25、entity
parser.add_argument('--entity', default=None, help='W&B entity')wandb 库对应的东西
26、name
parser.add_argument('--name', default='exp', help='save to project/name')用于设定保存的模型文件名
27、exist-ok
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')用于设定预测结果的保存存在位置情况
一般为true
当为 false,在新命名的文件夹下保存
当为 true,在 name 指定文件夹下保存,源码中保存在 exp 文件夹下
28、quad
parser.add_argument('--quad', action='store_true', help='quad dataloader')简单理解,生效后可以在比前面 “--img-size” 部分设置的训练测试数据集更大的数据集上训练。
好处是在比默认 640 大的数据集上训练效果更好
副作用是在 640 大小的数据集上训练效果可能会差一些
29、linear-lr
parser.add_argument('--linear-lr', action='store_true', help='linear LR')用于对学习速率进行调整
默认为 false,含义是通过余弦函数来降低学习率。
30、label-smoothing
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')用于对标签进行平滑处理。
作用是防止在分类算法中过拟合情况的产生。
31、upload_dataset
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')wandb 库对应的东西,不必考虑
32、bbox_interval
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')wandb 库对应的东西,不必考虑
33、save_period
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')用于记录训练日志信息,int 型,默认为 -1
34、artifact_alias
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')可能以后更新的参数
35、freeze
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone of yolov7=50, first3=0 1 2')“冻结”层指的是该层不参加网络训练,yolov7的冻结层是50层
















 1849
1849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











