







一、环境
- windows10
- python3.7
- mysql8(本地+阿里云)
二、出现的问题及注意事项
- 这是一个小组任务,而且对于每个人来说都是全新的知识,但是在前期没有充分沟通学习方式,导致大家各自学习,走了许多弯路。
- 爬下来的数据在处理上欠考虑,给后续步骤带来麻烦。
- 完成本组任务后和博物馆信息组的同学交流,发现还存在反爬技术。对此我的想法是,我学的东西能够完成我的任务,那就没必要深入学习爬虫,毕竟这不是我的主要兴趣而每个人的时间都是有限的。这个学期各种事情都堆在一起,很考验时间管理的能力,要分清主次,一门2.5学分的选修课不值得我花那么多时间。
- 当然要向别人学习,别的团队做得更好那就向他们学习。但是也不要一味和别人比较,“他强由他强,清风拂山冈”。别的团队学习了怎么应对反扒,不意味着我们也需要去学,还是那句话,我们学的东西足够达到一个还能过得去的程度,这就可以了。毕竟,这是软件工程课,爬虫、前后端其实都不是重点,既然老师不负责任地布置了这种大作业,那我也没必要认真对待。别人是大佬,别的组有大佬,他们做得好,这和我没关系。
三、爬虫思路
由于本人是初学者,有说的不对的地方敬请指正。
首先,要找一个教程,B站上有很多,不要看书或者看博客,因为视频能展示更多信息,很多会踩的坑是很难用文字一一表述出来的,那样会使文章显得臃肿,而在视频里可能就是半分钟的debug,而且视频能帮你快速建立对新知识的整体认识。举例来说,在学习的前期,我们组的每一个人都以为爬虫可以一套代码爬很多网站,在中期,其他组(前端、后端)的同学说数据库里新闻太少、博物馆信息太少,我们也得和他们解释,爬虫没有那么智能,对于不同的网站(通常页面结构不同)需要不同的爬虫代码,想爬一个网站就得先查看它的页面结构。你看,这么简单的道理,对于新手来说确实是一个认知上的障碍。下图中,一个个html标签组成了这个网页,不同的网页用的标签是不同的。
第二,现代网页很少有不用AJAX动态加载的,也就是说对一个url发请求不会得到想要的信息。拿新闻来说,我们选择对新华网上博物馆的新闻进行爬取,在新华网(或者人民网、腾讯新闻等)搜索栏输入“故宫博物院”会跳转到一个网页,这个网页就是动态加载出来的。很多文字教程并没有讲这个,而只是讲怎么爬一个静态的html页面。上图中,是没办法通过对该页面的网址作解析得到所选的<a></a>标签的。事实上,我之前一直认为遇到任何问题都应该到官网找答案,但是在beautifulsoup、scrapy官网耗了很久,虽然会看到一些dynamic load之类的词,但实际上并不清楚,同样的事视频里10分钟就讲完了,这不比看官方文档快?下图中,切换到network标签,选择XMR,刷新页面,就可以看到抓到一个包,在header中可以看到实际上我们要发请求的网址,以及需要哪些参数。
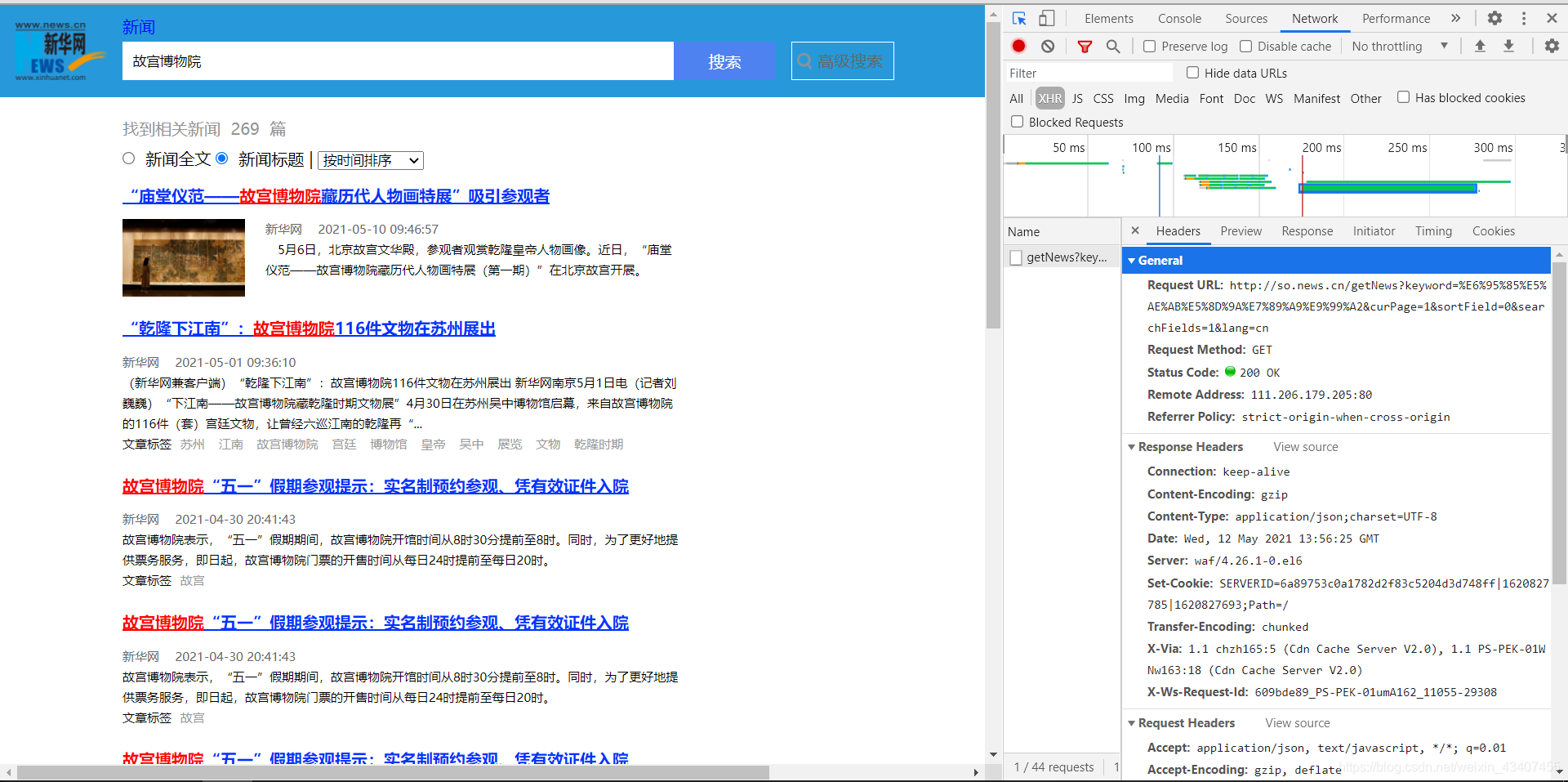
第三,对于动态请求的页面的处理,简单来说就是加载这个页面的时候,我们并不从这个页面的html获取数据,实际上是向某个地址(人民网用的是elasticsearch)发送了带有一些参数的请求,我们就是要获取这个地址,并根据需要更换参数。在这次作业中,博物馆的名字就是一个参数,搜索的博物馆的新闻一页放不下的时候,页码也是一个参数。页面结构、获取所谓的请求地址都是用浏览器的“开发者工具"的。要获取返回的数据,你可以在上图中切换到与header同级的response标签,你会看到一个JSON格式的字符串,格式化以后看得清楚一点(如下图)。这一条所说的你只要在那些教程里看上一两个视频就都会了。

第四,动态请求的页面上有我们所需的各条新闻的链接,当我们获取这些动态加载出来的链接之后,就可以按照解析静态网页的方式解析这些网址了。新华网、人民网都是分主站新闻、地方频道的,别的细分种类还包括视频新闻等,他们的结构是不同的。在本次任务中,我们选择了先只爬主站新闻,后面再加入了地方频道(我们只需要往数据库里存文本和图片地址,不考虑视频),事实上,新华网的地方频道也是由两种主要结构和其他一些乱七八糟的结构(这些就不爬了)组成的。这都是在爬取的过程中发现的,没有什么捷径。
第五,发送请求的是requests包,解析返回来的数据的是beautifulsoup包,本次任务并没有用到scrapy(一个框架,而不只是包)和selenium(最复杂也最强大)。主要就是用find,find_all,select等方法找标签,具体学习上beautifulsoup官网或别的文字教程即可(这个可以有)。
第六,考虑到网页动态返回的数据格式(一般是json),处理数据、保存文件、传数据库的统一性,最好都使用json格式存储数据。
第七,编码相关的问题遇到多次,这里充分体现了面向百度/谷歌编程的重要性。
- 有很多地方涉及到编码的问题,不报错,你都不知道你看到的是不是你看到的,也不知道为什么你看到的不是你想看到的。
- 网页返回的数据有的是gbk,有的是utf-8;用powershell运行程序时的活动页代码(chcp)默认是936(简体中文),有时要切换成65001(utf-8);vscode默认显示编码是utf-8,而有的时候又需要切换成gbk才能正常显示中文文件;requests请求回来的数据照理说是utf-8(ajax请求头里写了返回数据的编码格式),vscode编码也是utf-8,但会乱码;读写json文件要指定编码;python文件要指定编码(以前听都没听说过);json(javascript)中布尔真是true,python中布尔真是True。以下问题都是我遇到的,具体报什么错已经不完全记得了。
- 打开json文件时要指定open()编码为utf-8(虽然这应该是默认值),同时json.dump()中要把ensure_ascii置为False,否则就只会正常写入ASCII码范围内的字符,不在其列的中文字符就会以\xxxx乱码的形式出现,这时就算再用gbk或utf-8读也没用,因为这时存的就是\xxxx这个字符串。
with open(f"新华网_{keyword}.json", 'w', encoding="utf-8") as f:
json.dump(all_news, f, ensure_ascii=False)
response = requests.get(url, headers=headers)之后要加response.encoding = response.apparent_encoding,我试过不加,或指定为utf-8和gbk,都会乱码,只能用apparent_encoding,方法是网上找的,原理不清楚。- 因为要进行文本情感倾向分析,所以需要将大段的新闻内容(字符串)传给函数。字符串比较短的时候什么事都没有,比较长就会报“Non-UTF-8 code starting with”的错,但我是以同一个字开头的啊,只是长度变长了而已。解决方法是在文件最开头(如果开头有注释的话也得在其之后,反正就是在第一行)加上
# -*- coding:utf-8 -*-。 - 阿里云NLP服务返回的json格式(其实是bytes格式,要用json.loads转)有问题,将一系列键值对装在双引号里成了字符串,导致没法用键值访问result的内容(正面/中立/负面)。python中用ast.literal_eval可以将字符串转成字典(详细用法就不展开了,还有其他用处),但是这时一直报“畸形的字符串”(大概是这个意思),原因就是这个方法不像json包提供的方法会处理true/True,需要先把true替换成True。
data = resp_obj["Data"].replace("true", "True")
data = ast.literal_eval(data)
- 爬下来的数据中会有换行符、缩进以及其他莫名奇妙的字符,全都删掉。(影不影响文意就不管了,反正只是作业,不用搞那么仔细)
p_text = p.text.replace("\u3000", "").replace('\n', "").replace('\r', "").replace('\t', "").replace('\xa0', "")
- 真的遇到很多问题和报错,现在也记不起来了,等记起来再补上。
第八,文本情感倾向分析直接调用阿里云的服务,相关操作按文档来就行(别的也找不到什么资料)。百度、腾讯、华为等其他公司也有这种开放的AI能力提供,也可以选择。
第九,为避免数据库里出现重复记录,要实现增量更新。实现思路是:每次爬取前都会先扫描当前目录下的json文件(如果有news_inserted.json也要读入),读取它们的内容,获取标题(后面会用到,因为某个标题可能对应多个报道同一个新闻的不同页面,对这些新闻得去重,靠的是标题),统计新闻条数,然后写入news_inserted.json,将其他json移入当前目录下的子文件夹backup。每次爬完后都可能在当前目录下产生“新华网_XXX.json”文件,json2mysql.py会把这些文件中的数据导入数据库,而不会把news_inserted.json中的数据导入数据库。所以爬完就要紧跟着导入,不然数据就会被归档。
四、代码
(1)爬虫
# -*- coding:utf-8 -*-
# 加入情感倾向分析(v5)
# 1、调用阿里云NLP服务实现情感倾向分析
# 2、解决编码问题,在首行加# -*- coding:utf-8 -*-。注意是有井号的,而且一定是全文的首行,即,包括文首的注释,都得在这句之后
# (1)短文本不用加也行,长文本就会报Non-UTF-8 code starting with的错误,原因我不知道
# 针对更新的需求进行调整(v4)
# 1、实现地方频道的爬取
# 2、在结果json中加入title,省去v3中提取symbol的步骤,改为判断title,相应地,要改导入数据库的文件
# 3、测试说明
# (1)先用少一点的博物馆和少一点的curPage
# (2)再加curPage
# (3)再加别的博物馆
# 针对更新的需求进行调整(v3)
# 1、每次运行这个脚本之前都要对当前目录下已有的json文件进行处理,以实现导入数据库的只有增量部分,同时保留历史版本
# 针对传数据库的要求进行调整(v2)
# 1、每条新闻的图片最多1张(可以没有,但是不能多,因为表中目前只给一个位置
# 2、每个每条记录都要完整包含来源、博物馆名字,而不是上一个版本那样一个博物馆一个json
# 3、使用navicat导入json的功能
import requests
import json
import csv
import os
import ast
from bs4 import BeautifulSoup
import shutil
from aliyunsdkalinlp.request.v20200629 import GetSaChGeneralRequest
from aliyunsdkcore.client import AcsClient
from aliyunsdkcore.acs_exception.exceptions import ClientException
from aliyunsdkcore.acs_exception.exceptions import ServerException
def get_url_list(origin_url):
url = origin_url
# 用开发者工具查看ajax包时,在请求头里发现请求的Content-Type的格式和编码是application/json;charset=UTF-8。不加会有乱码。
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/67.0.3396.99 Safari/537.36",
'Content-Type': 'application/json;charset=UTF-8'
}
# 存放详情页地址(静态,实际要爬的网页)的列表
url_list = []
try:
# 这里的实际请求url中就带了参数,用的是get方法
# 有的网页实际请求url中不带参数,用的是post方法,这时要把参数以data参数给出(详见视频教程)
json_urls = requests.get(url=url, headers=headers).json()
# 观察返回的json数据,发现所要的url在如下位置
results = json_urls["content"]["results"]
if results is None:
return
for result in results:
url_list.append(result["url"])
print(f"正在获取{keyword}的第{curPage}页新闻。。。")
return url_list
except Exception as e:
print(e)
# 地方频道
# eg. http://www.js.xinhuanet.com/2021-02/07/c_1127073849.htm
# http://www.zj.xinhuanet.com/2020-06/13/c_1126110863.htm
def crawl_news_A(keyword, url, article, soup, titles):
# 找标题
h1 = article.find_next("h1", id="title")
if h1 is None:
return
# 把莫名奇妙的字符去掉
title = h1.text.replace("\n", "").replace('\r', "").replace('\u3000', ",").strip().replace(' ', ",")
# 判断是不是重复,避免传进数据库很多相似度很高的新闻
if title in titles:
print("重复的新闻!")
return
# 在实际爬取过程中发现,搜索结果有时候是模糊匹配,比如搜“上海博物馆”,返回的有“上海自然博物馆”的新闻。报错中提供url,以供确认
if keyword not in title:
print(</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 778
778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









