






1. 导包
日常导包
根据工具包可以看出使用的是seaborn和matplotlib进行可视化分析
使用标签编码和标准化对数据进行特征处理
使用xgboost进行训练预测
使用混淆矩阵,准确率,F1-Score等进行结果可视化展示
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import chardet
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.metrics import accuracy_score, classification_report, roc_curve, auc
from sklearn.metrics import confusion_matrix
- 数据读取
先获取数据对应的编码方式,再使用数据对应的编码方式读取数据
file_path = '/home/mw/input/depression4298/Depression_Students.csv'
with open(file_path, 'rb') as file:
raw_data = file.read()
detected_encoding = chardet.detect(raw_data)['encoding']
# 读取数据
data = pd.read_csv(file_path, encoding=detected_encoding)
# 展示数据
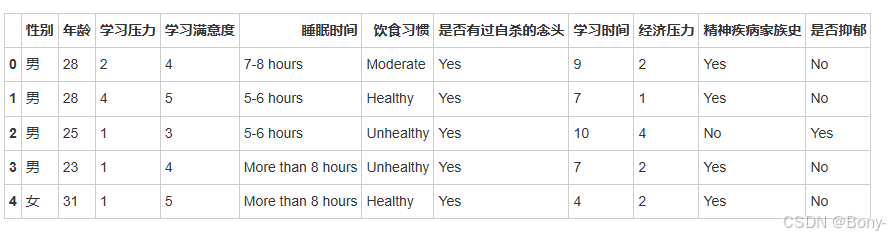
data.head()
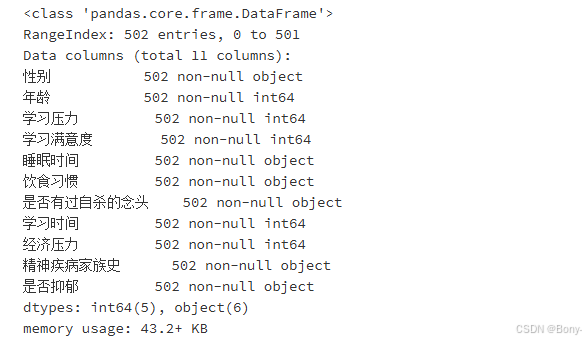
data.info()
3. 数据可视化分析
# 设置白色背景和网格线
# 可选的 style 参数值:
# white:白色背景,没有网格线。
# dark:深色背景,默认显示网格线。
# darkgrid:深色背景,带有网格线。
# whitegrid:白色背景,带有网格线。
# ticks:带有刻度线的白色背景图。
sns.set(style="whitegrid")
# 设置支持中文的字体,确保中文字符能正常显示
matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False
3.1 性别分布
数据样本性别分布
plt.figure(figsize=(10, 6))
sns.countplot(data=data, x="性别", palette="pastel")
# 添加顶部数值标签
ax = sns.countplot(data=data, x="性别", palette="pastel")
for p in ax.patches:
ax.annotate(f'{p.get_height()}',
(p.get_x() + p.get_width() / 2., p.get_height()),
ha = 'center', va = 'center',
fontsize=12, color='black',
xytext=(0, 5), textcoords='offset points')
plt.title("性别分布", fontsize=14)
plt.xlabel("性别", fontsize=12)
plt.ylabel("人数", fontsize=12)
plt.show()
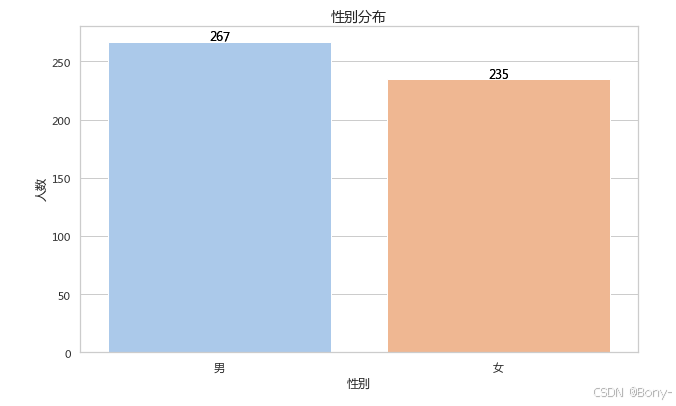
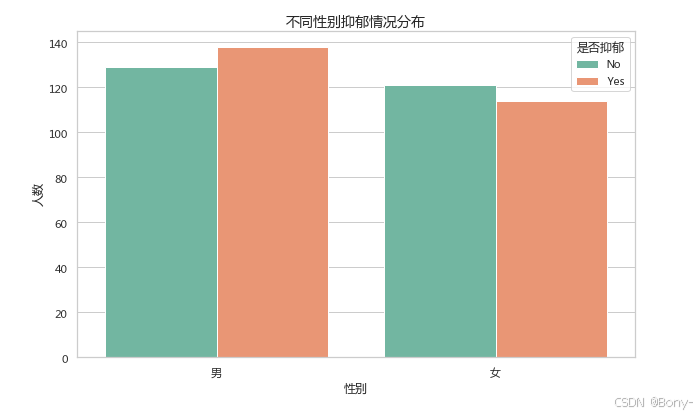
3.2 不同性别抑郁情况分布
plt.figure(figsize=(10, 6))
sns.countplot(data=data, x="性别", hue="是否抑郁", palette="Set2")
plt.title("不同性别抑郁情况分布", fontsize=14)
plt.xlabel("性别", fontsize=12)
plt.ylabel("人数", fontsize=12)
plt.legend(title="是否抑郁")
plt.show()
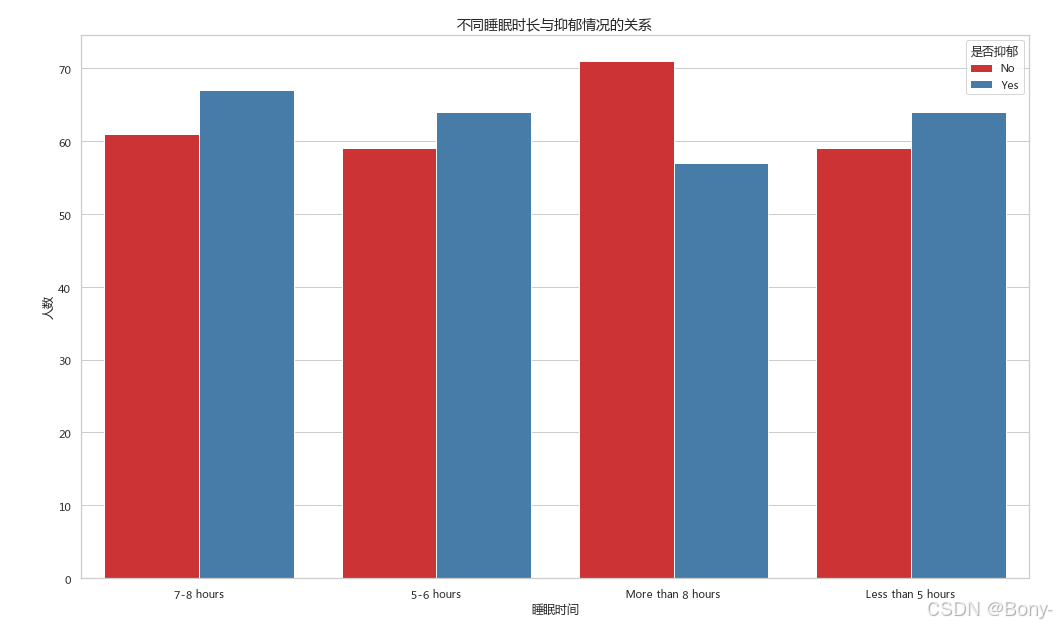
3.3 不同睡眠时长与抑郁情况的关系
plt.figure(figsize=(17, 10))
sns.countplot(data=data, x="睡眠时间", hue="是否抑郁", palette="Set1")
plt.title("不同睡眠时长与抑郁情况的关系", fontsize=14)
plt.xlabel("睡眠时间", fontsize=12)
plt.ylabel("人数", fontsize=12)
plt.legend(title="是否抑郁")
plt.show()
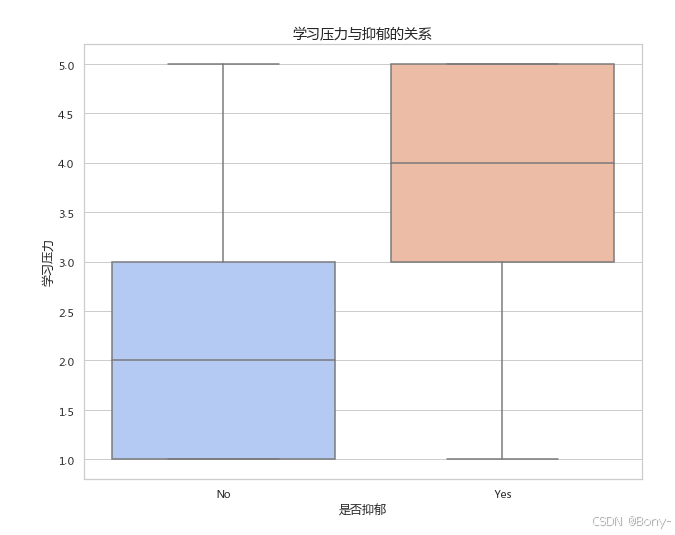
3.4 学习压力与抑郁的关系
从这个图可以看出,学习压力是抑郁的主要因素
plt.figure(figsize=(10, 8))
sns.boxplot(data=data, x="是否抑郁", y="学习压力", palette="coolwarm")
plt.title("学习压力与抑郁的关系", fontsize=14)
plt.xlabel("是否抑郁", fontsize=12)
plt.ylabel("学习压力", fontsize=12)
plt.show()
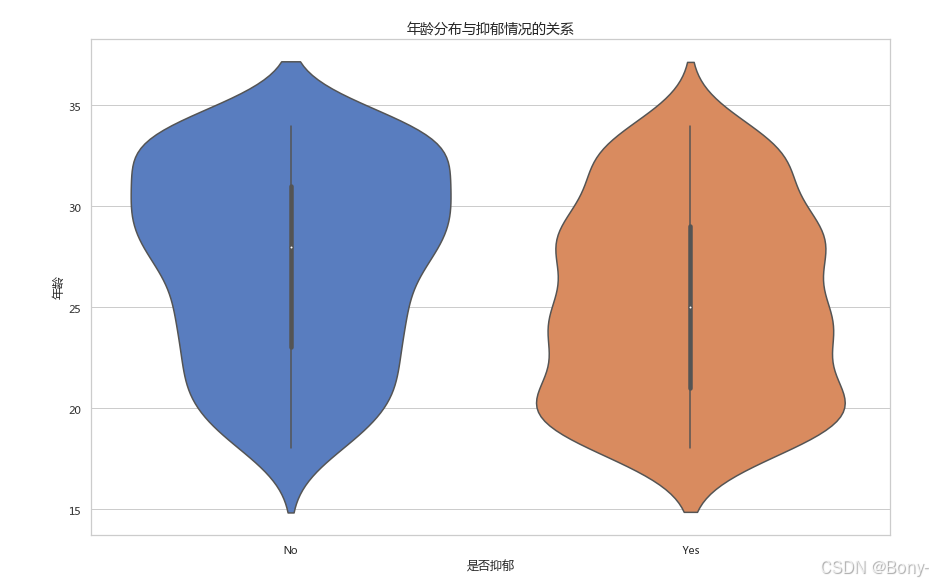
3.5 年龄分布与抑郁情况的关系
绘制小提琴图:年龄分布与抑郁情况的关系
plt.figure(figsize=(12, 8))
sns.violinplot(data=data, x="是否抑郁", y="年龄", palette="muted")
plt.title("年龄分布与抑郁情况的关系", fontsize=14)
plt.xlabel("是否抑郁", fontsize=12)
plt.ylabel("年龄", fontsize=12)
plt.tight_layout()
plt.show()
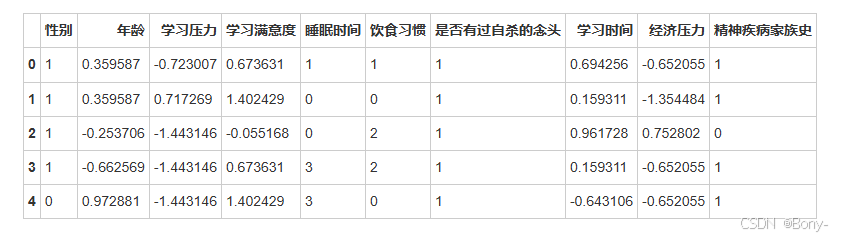
4. 特征编码
使用标签编码和数据标准化
# 创建标签编码器
label_encoder = LabelEncoder()
# 将类别变量转换为数值
data['性别'] = label_encoder.fit_transform(data['性别'])
data['是否抑郁'] = label_encoder.fit_transform(data['是否抑郁'])
data['睡眠时间'] = label_encoder.fit_transform(data['睡眠时间'])
data['饮食习惯'] = label_encoder.fit_transform(data['饮食习惯'])
data['是否有过自杀的念头'] = label_encoder.fit_transform(data['是否有过自杀的念头'])
data['精神疾病家族史'] = label_encoder.fit_transform(data['精神疾病家族史'])
# 标准化数值变量
scaler = StandardScaler()
data[['年龄', '学习压力', '学习满意度', '学习时间', '经济压力']] = scaler.fit_transform(data[['年龄', '学习压力', '学习满意度', '学习时间', '经济压力']])
5. 模型训练
先划分数据集,再使用xgboost进行训练
# 特征和目标变量
X = data.drop('是否抑郁', axis=1) # 去掉目标变量
y = data['是否抑郁'] # 目标变量
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X.head()
# 初始化并训练XGBoost模型
xgb_model = xgb.XGBClassifier(random_state=42)
xgb_model.fit(X_train, y_train)

# 在测试集上进行预测
y_pred_xgb = xgb_model.predict(X_test)
# 评估模型性能
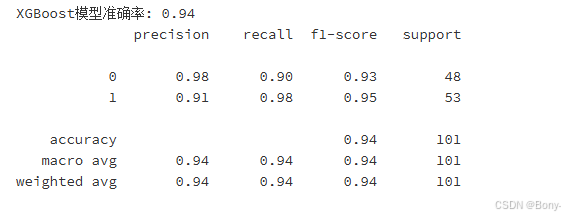
accuracy_xgb = accuracy_score(y_test, y_pred_xgb)
print(f"XGBoost模型准确率: {accuracy_xgb:.2f}")
print(classification_report(y_test, y_pred_xgb))
6. 结果可视化展示
6.1 混淆矩阵
绘制各个标签的混淆矩阵分为TT,TF,FT,FF
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred_xgb)
# 绘制混淆矩阵
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=label_encoder.classes_, yticklabels=label_encoder.classes_)
plt.title('混淆矩阵')
plt.xlabel('预测类别')
plt.ylabel('实际类别')
plt.show()

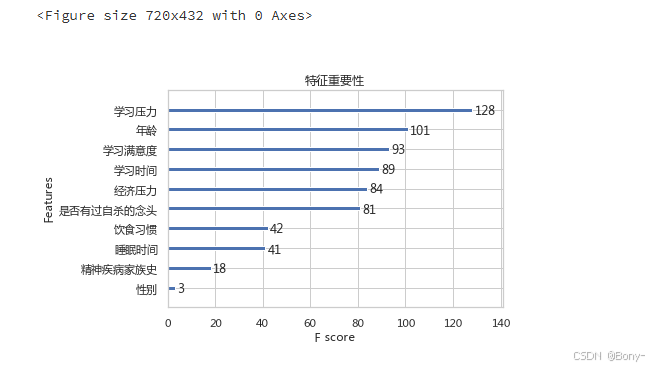
6.2 特征重要性
查看各个特征对目标变量的重要性
# 特征重要性
plt.figure(figsize=(10, 6))
xgb.plot_importance(xgb_model, importance_type="weight", max_num_features=10, title="特征重要性")
plt.show()
总结
学习压力是学生抑郁的主要影响因素
其他影响因素请看上图
# 需要数据集的请点击以下链接。
https://mbd.pub/o/bread/mbd-Z5ybm5hq


















 1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











