







在深度学习中,神经网络的训练主要依赖于反向传播算法,通过计算模型预测值与正确标签的差异,来调整模型参数以优化性能。自动微分能够自动计算函数在某点处的导数值,大大简化了反向传播的实现过程。本文将通过一个简单的教程,介绍如何在MindSpore中使用函数式自动微分,并探讨其在神经网络训练中的应用。
1. 函数与计算图
为什么要构建计算图?
构建计算图是为了以图论的方式表示数学函数,这样可以更直观地理解和操作复杂的数学运算。在深度学习中,计算图是表达神经网络模型的统一方法,有助于简化模型的构建和调试过程。
在本教程中,我们将根据下面的计算图构造计算函数和神经网络。
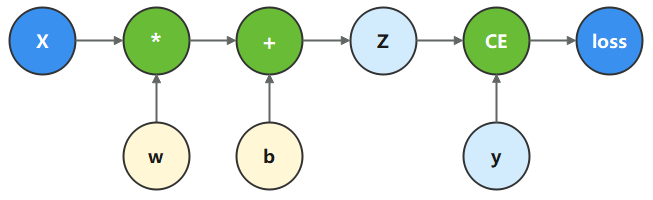
在这个模型中,
x
x
x 为输入,
y
y
y 为正确值,
w
w
w 和
b
b
b 是我们需要优化的参数。
import numpy as np
import mindspore
from mindspore import nn, ops, Tensor, Parameter
x = ops.ones(5, mindspore.float32) # 输入张量
y = ops.zeros(3, mindspore.float32) # 期望输出
w = Parameter(Tensor(np.random.randn(5, 3), mindspore.float32), name='w') # 权重
b = Parameter(Tensor(np.random.randn(3,), mindspore.float32), name='b') # 偏置
根据计算图描述的计算过程,构造计算函数:
def function(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss
loss = function(x, y, w, b)
print(loss)
2. 微分函数与梯度计算
为什么要使用 grad 函数?
grad 函数用于自动计算函数的导数值,这在优化模型参数时非常重要。通过 grad 函数,我们可以轻松获得参数对损失函数的导数,从而进行梯度下降等优化操作。
为了优化模型参数,需要求参数对loss的导数:
∂
loss
∂
w
\frac{\partial \operatorname{loss}}{\partial w}
∂w∂loss 和
∂
loss
∂
b
\frac{\partial \operatorname{loss}}{\partial b}
∂b∂loss。MindSpore 提供了 grad 函数来实现这一功能。
grad_fn = mindspore.grad(function, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
3. Stop Gradient
为什么要使用 stop_gradient?
在某些情况下,我们希望在计算梯度时忽略某个输出项的影响。这时可以使用 stop_gradient 操作来截断梯度流,从而只计算我们关注的部分对参数的导数。这在复杂模型中非常有用,可以灵活控制梯度的传播路径。
当我们希望函数输出多项时,微分函数会求所有输出项对参数的导数。此时如果想实现对某个输出项的梯度截断,可以使用 ops.stop_gradient 接口。
def function_with_logits(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss, z
grad_fn = mindspore.grad(function_with_logits, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
def function_stop_gradient(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss, ops.stop_gradient(z)
grad_fn = mindspore.grad(function_stop_gradient, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
4. 辅助数据 (Auxiliary data)
grad 和 value_and_grad 提供 has_aux 参数,当其设置为 True 时,可以自动实现前文手动添加 stop_gradient 的功能。
为什么要设置 has_aux=True?
has_aux=True 参数用于自动实现辅助数据的梯度截断功能。当函数有多个输出时,设置 has_aux=True 可以确保只有第一个输出(通常是损失值)参与梯度计算,而其他输出作为辅助数据返回。这简化了代码编写,避免了手动添加 stop_gradient 的麻烦。
grad_fn = mindspore.grad(function_with_logits, (2, 3), has_aux=True)
grads, (z,) = grad_fn(x, y, w, b)
print(grads, z)
5. 神经网络梯度计算
为什么要封装前向计算函数?
在使用 nn.Cell 构建神经网络时,我们需要将前向计算和损失函数的调用封装为一个前向计算函数。这是因为 value_and_grad 等函数式自动微分接口需要一个完整的函数来计算前向传播和损失值,从而进行梯度计算。封装前向计算函数可以使代码更清晰、结构更合理。
我们可以通过 nn.Cell 构造神经网络,并使用函数式自动微分来实现反向传播。
首先构造单层线性变换神经网络:
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.w = w
self.b = b
def construct(self, x):
z = ops.matmul(x, self.w) + self.b
return z
实例化模型和损失函数:
model = Network()
loss_fn = nn.BCEWithLogitsLoss()
def forward_fn(x, y):
z = model(x)
loss = loss_fn(z, y)
return loss
grad_fn = mindspore.value_and_grad(forward_fn, None, weights=model.trainable_params())
loss, grads = grad_fn(x, y)
print(grads)
通过本文的详细介绍和代码示例,相信你已经掌握了在MindSpore中使用函数式自动微分的基本方法和技巧。从计算图的构建到梯度的计算,再到神经网络的实际应用,MindSpore提供了丰富而灵活的工具来简化这一过程。希望你能在实际项目中灵活应用这些知识,不断优化和提升你的深度学习模型。无论是初学者还是有经验的开发者,函数式自动微分都将是你深度学习工具箱中的一把利器。















 1228
1228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









