







 本文探讨了强化学习中的模仿学习,包括行为克隆、DAGGER算法、逆强化学习(IRL)和生成对抗模仿学习(GAIL)。介绍了将模仿学习与强化学习结合的方法,如预训练和调整、IL与Off-Policy RL的融合,并通过案例研究展示了运动模仿。同时,讨论了模仿学习面临的数据限制和非马尔科夫行为等问题。
本文探讨了强化学习中的模仿学习,包括行为克隆、DAGGER算法、逆强化学习(IRL)和生成对抗模仿学习(GAIL)。介绍了将模仿学习与强化学习结合的方法,如预训练和调整、IL与Off-Policy RL的融合,并通过案例研究展示了运动模仿。同时,讨论了模仿学习面临的数据限制和非马尔科夫行为等问题。
目录
Introduction & Behavioral Cloning
DAGGER algorithm to improve BC【就是在BC中引入了online iteration,2011】
(1)最简单直接的结合:预训练和调整 Pretrain and Finetune【应用十分广泛】
(2)IL 结合 Off-Policy RL:算是对 Pretrain and Finetune 的改进
一个有趣的 Case Study—— motion imitation
课程大纲
模仿学习介绍
行为克隆 BC 和 DAGGER 算法
逆强化学习 IRL 和 生成对抗模仿学习GAIL
改进模仿学习的性能
把模仿学习和强化学习结合
Introduction & Behavioral Cloning
从最简单的行为克隆方法开始介绍:比较简单的思想就是把策略的学习当做有监督的学习来进行,例如学习出来策略网络
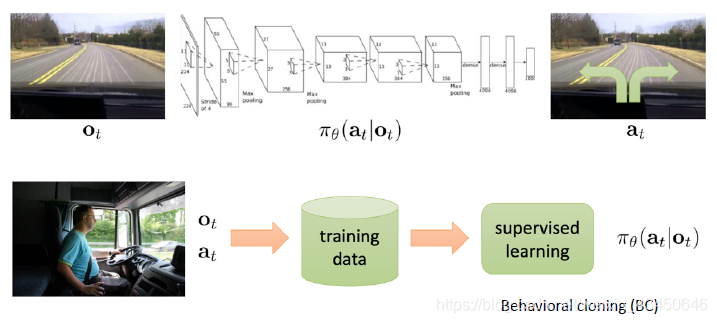
这样直接把它当做一个有监督的问题来解决的话其实是有问题的:数据的分布假设相矛盾 —— 有监督学习假设数据是 IID 的,但是一个时序的决策过程采集到的数据是有关联的;而且如果模型进入到 off-course 状态(训练时没见到过的状态)时不知道怎么回来
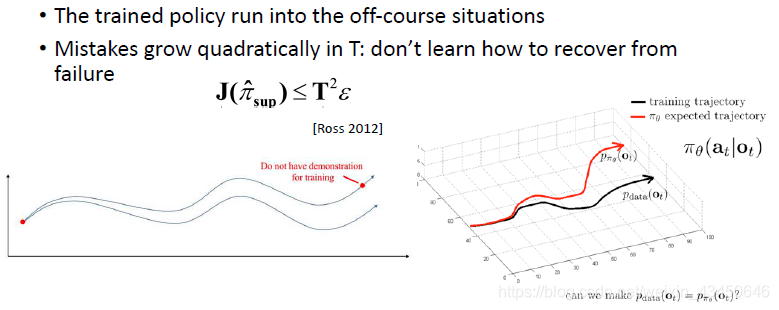
一个可能的解决方案就是:不断添加数据,变成 online 的过程
DAGGER algorithm to improve BC【就是在BC中引入了online iteration,2011】


DAGGER 的缺点在于第三步实在是太耗费时间了,可以改进 DAGGER 吗?第三步是不是可以用其他的算法来打标签呢?
改进DAGGER:

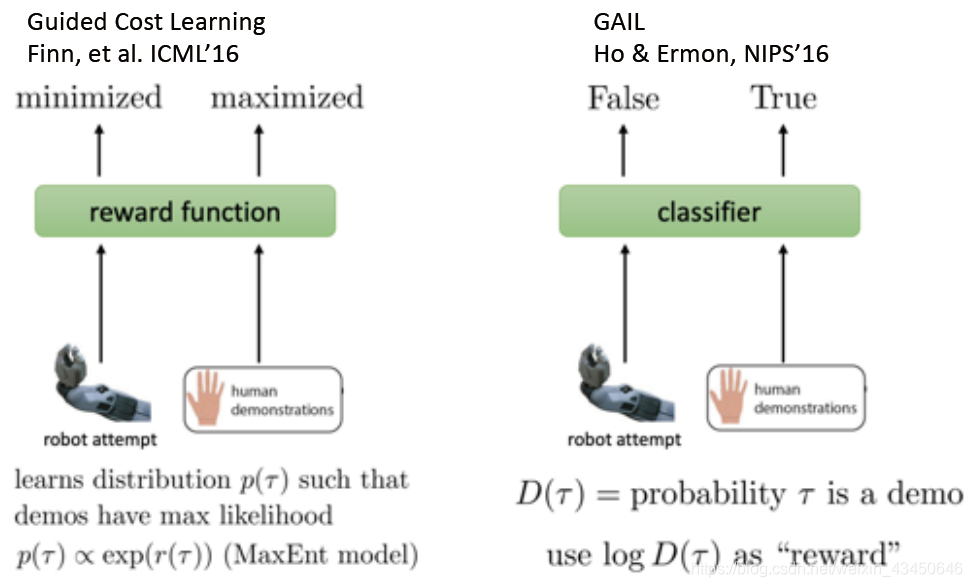
Inverse RL & GAIL
Inverse RL
IRL 与 RL 的对比:
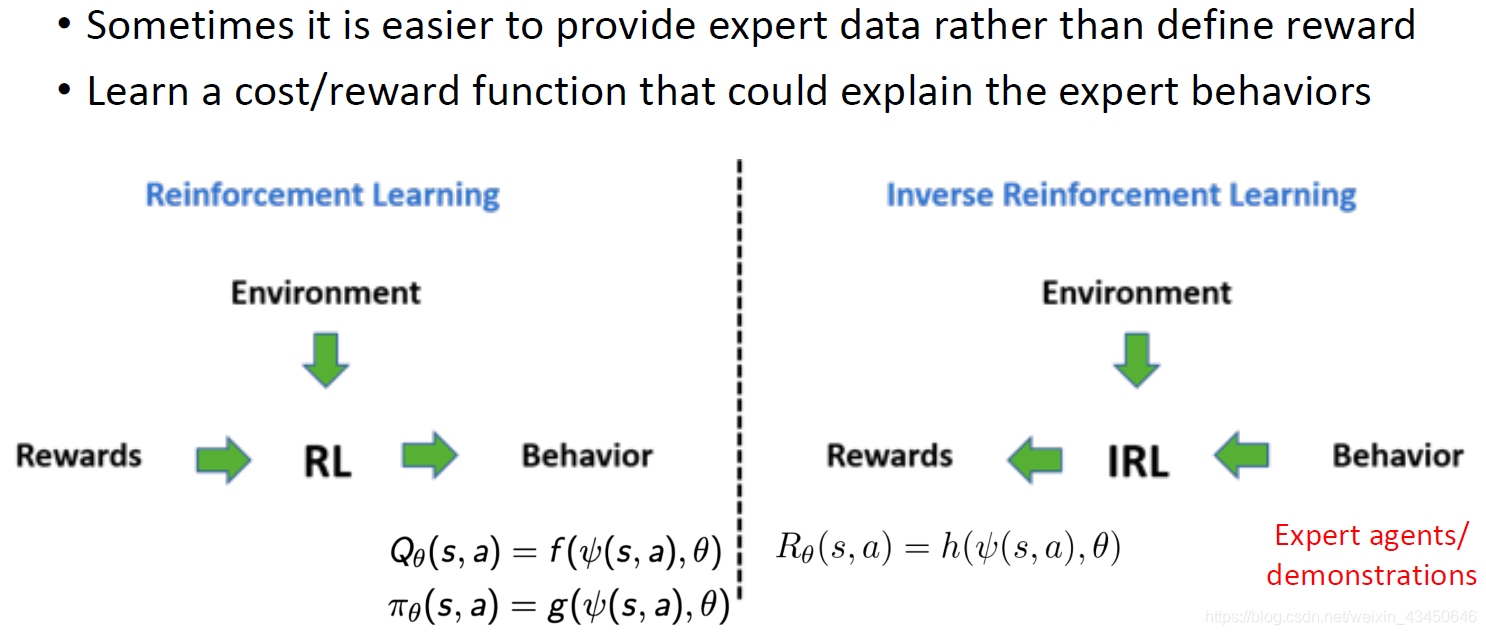
IRL的举例:
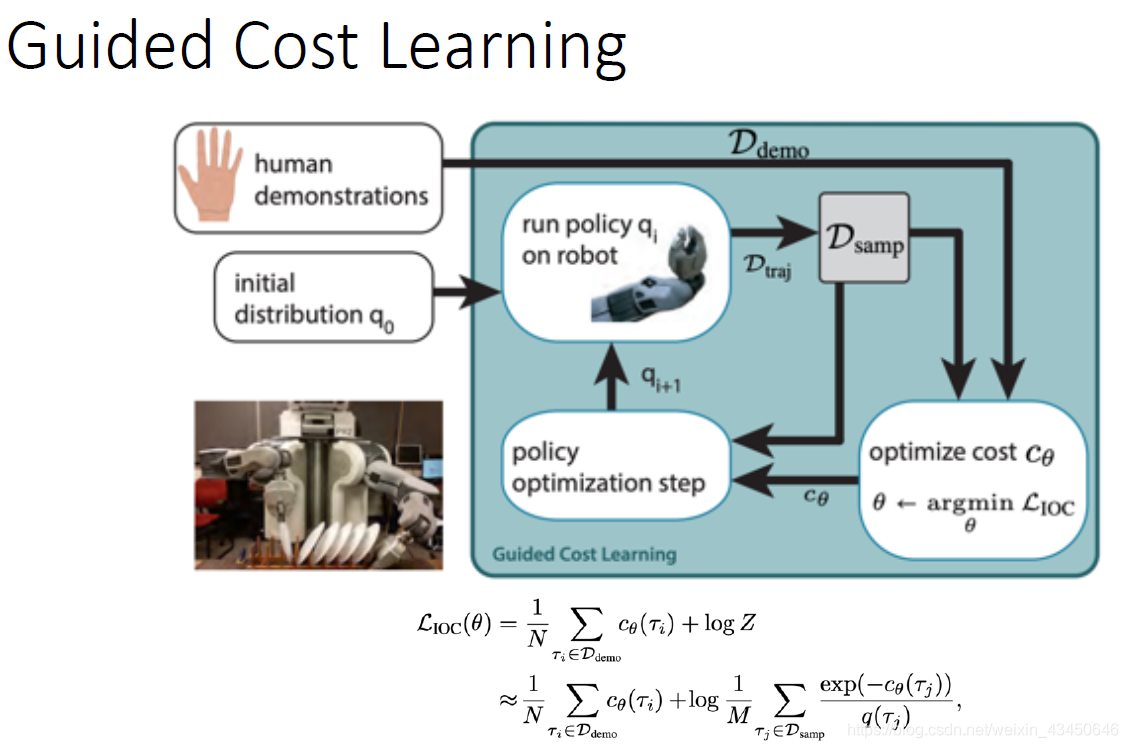
GAIL
类似于 IRL,GAN 学习了一个目标函数用于生成模型,GAIL 模仿了 GAN 的思想

Connection between IRL & GAIL
改进模仿学习的性能
怎样提升我们的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









