







RIRE数据集可以在官网获取(https://bafybeih23xv6uamx7k27wk4uvzkxdtdryqeok22hpl3ybideggcjhipwme.ipfs.dweb.link/rire)
由于数据集没有封装在一个文件夹下,因此需要单个重复下载,以其中两个为例,下载后的数据集如下所示。

在工程目录下新建文件夹datafile,将下载后的数据集(.tgz)直接放进去,不用进行解压。注意datafile文件夹与代码同级目录。
每一个.tgz文件夹解压后,包含了下面的文件
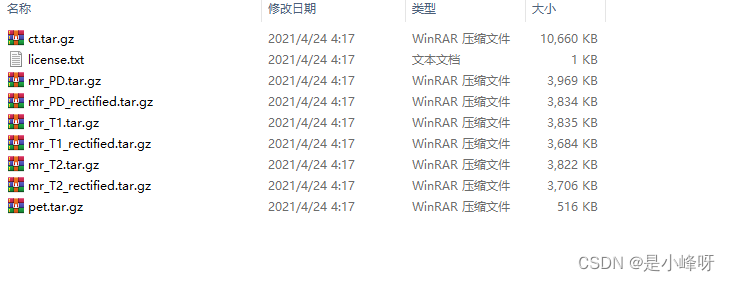
下面的每一个.tar.gz压缩文件继续解压后,里面包含了下面的文件
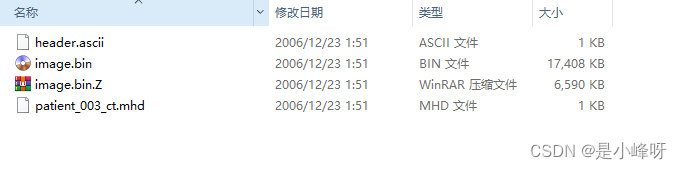
我们的目标就是将里面的所有.tar.gz转换为一个个的nii文件。上面介绍了那么多,下面直接上代码。
import tarfile
import gzip
import os
import re
import SimpleITK as sitk
# 转换文件的存放路径,
'''
-datafile|
-patient_003.tgz|
-patient_007.tgz|
'''
# 将RIRE数据集(.tgz格式的压缩文件)直接放在datafile目录下
root_path = "./datafile"
abs_path = os.path.abspath(root_path.split("/")[0]).replace("\\", "\\\\")
abs_path = abs_path + "\\\\" + root_path.split("/")[1]
files_name = os.listdir(abs_path)
files_path = [abs_path + "\\\\" + name for name in files_name]
flag = False
untgz_file_path = [path.split(".")[0] for path in files_path]
untgz_file_path = list(set(untgz_file_path))
for path in files_path:
if os.path.exists(path.split(".")[0]):
flag = True
if not flag:
for path in files_path:
tar = tarfile.open(str(path))
tar.extractall(root_path)
# 解压缩.tgz文件
def untar(fname, dirs):
t = tarfile.open(fname)
t.extractall(path=dirs)
# 解压缩.gz文件
def un_gzfile(gz_path):
# 异常处理
try:
# 压缩文件解压
for f in os.listdir(gz_path):
if ".gz" in f:
g = gzip.GzipFile(mode="rb", fileobj=open(gz_path+"\\"+f, 'rb'))
open(gz_path+"\\"+f.replace(".gz", ""), "wb").write(g.read())
except Exception as e:
print(e)
else:
print("文件解压成功!")
all_files = []
all_files_path = []
dir_flag = False
for path in untgz_file_path:
lsdir = os.listdir(path)
dirs = [path + "\\\\" + i for i in lsdir if os.path.isdir(os.path.join(path, i))]
all_files_path.append(dirs)
if len(dirs) > 0:
dir_flag = True
for path in untgz_file_path:
files = os.listdir(path)
sub_file = []
sub_file_path = []
un_gzfile(path)
for item in files:
if not dir_flag:
if item.split(".")[1] == "tar":
sub_file.append(path + "\\\\" + item)
untar(path + "\\\\" + item, path)
sub_file_path.append(path + "\\\\" + item.split(".")[0])
all_files.append(sub_file)
print(all_files_path)
# mhd转换为nii格式
def mhd2nii(path, rootdir):
modalitydir = path
imagepath = os.path.join(modalitydir, 'image.bin')
if len(path.split("_")) == 2:
modality = str(str(path.split("_")[1]).split("\\")[0]) + "_" + str(str(path.split("_")[1]).split("\\")[2])
print(modality)
subject = str(str(path.split("_")[0]).split("\\")[-1])
elif len(path.split("_")) == 3:
modality = str(str(path.split("_")[1]).split("\\")[0]) + "_" + str(str(path.split("_")[1]).split("\\")[2]) + "_" + str(str(path.split("_")[2]))
print(modality)
subject = str(str(path.split("_")[0]).split("\\")[-1])
else:
modality = str(str(path.split("_")[1]).split("\\")[0]) + "_" + str(str(path.split("_")[1]).split("\\")[2]) + "_" + str(str(path.split("_")[2])) + "_" + str(str(path.split("_")[3]))
print(modality)
subject = str(str(path.split("_")[0]).split("\\")[-1])
# rootdir = "./"
_subjectstr = "traing"
_modalitystr = "test"
if not os.path.exists(imagepath):
os.system(f'gunzip {imagepath}.Z')
print(f'-> unzipped {modality}')
source_path = os.path.join(modalitydir, f'{subject}_{modality}.mhd')
# target_path = os.path.join(rootdir, f'{_subjectstr(subject)}_{_modalitystr(modality)}.nii')
target_path = os.path.join(rootdir, f'{(subject)}_{(modality)}.nii')
if not os.path.exists(target_path):
sitk.WriteImage(sitk.ReadImage(source_path), target_path)
print(f'-> converted {modality}')
# 首先解压所有的tgz文件,然后进入到每一个tgz文件内解压每一个.tar.gz文件,最后记录每一个文件的文件目录,循环处理每一个文件目录进行mhd文件的转换
for item in all_files_path:
print(item)
root_path = "./traing"
for sub_item in item:
mhd2nii(sub_item, root_path)
我以两个为例进行的代码调试,调试的结果如下所示
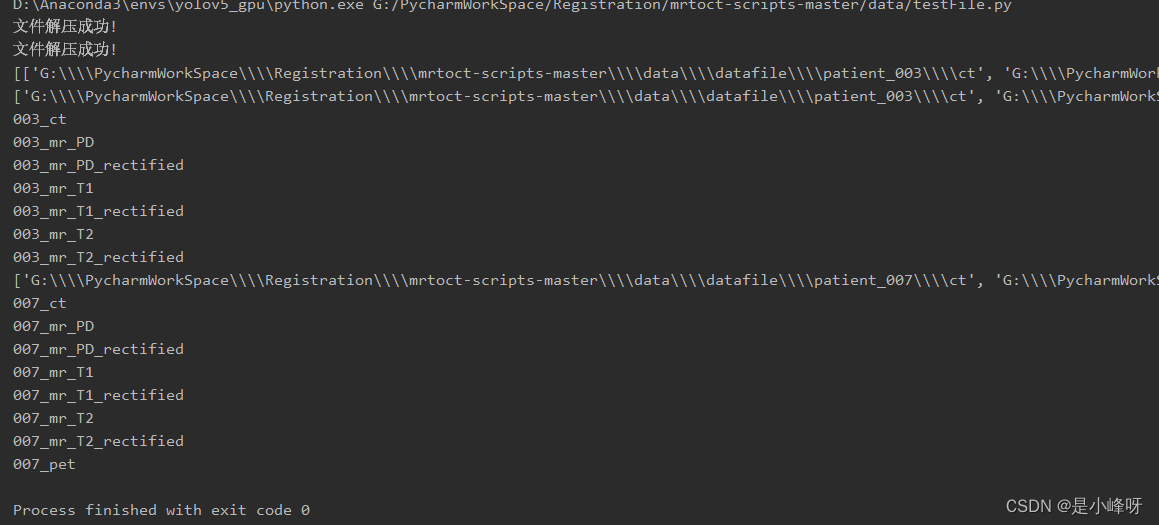
转换后的结果保存在代码同级目录下的traing文件夹中,解压后没有区分文件夹,需要的话可以自行修改代码,结果如下。
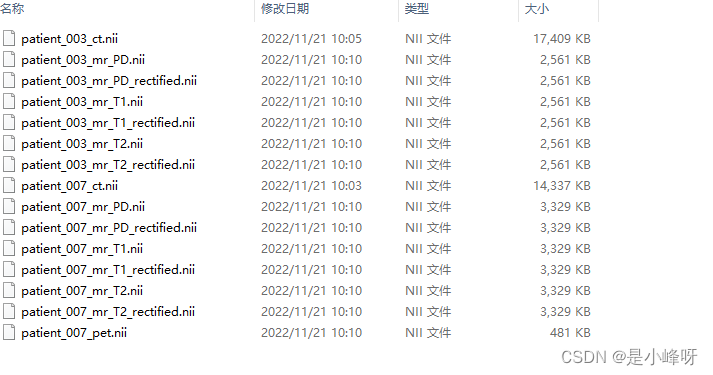
同时,由于对于文件夹执行了操作,会发现datafile文件夹里面所有的压缩文件被自动解压。
















 1053
1053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











