







首先我们要知道带雾图像和深度是有关系的,具体关系如公式1,2。但是这种模型容易受到雾浓度不均匀的影响,因此去雾性能收到限制。因此本文从深度和雾的关系出发,同时对两个任务进行优化,相互促进。
端到端的模型,摆脱了大气散射模型的限制,取得了更好的去雾效果,是现在的主流方法。

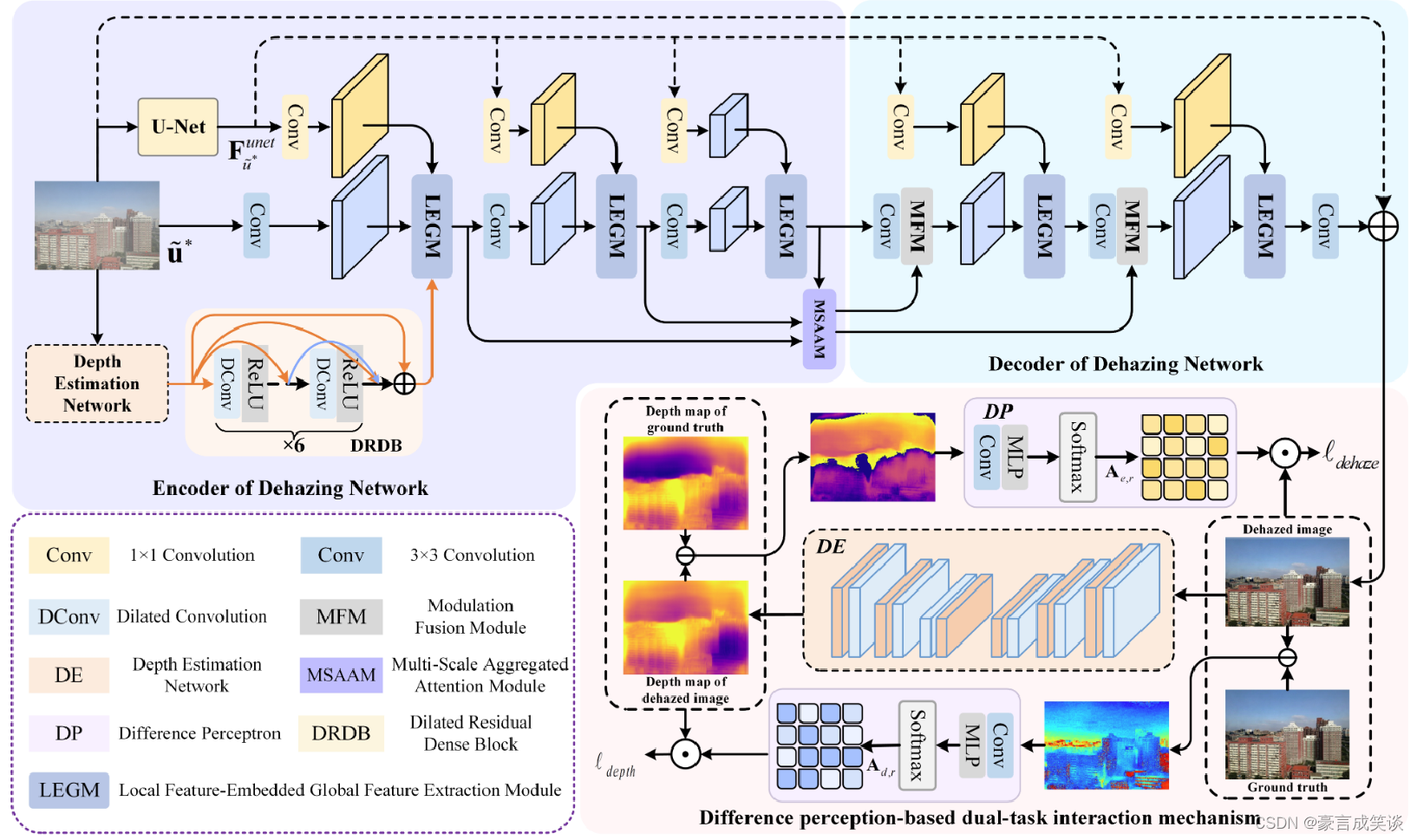
模型结构
去雾模型
编码部分:
从图中我们可以看出,带雾的图像被输入到两个分支中。
UNet:提取图像的多尺度特征,同时,计算公式5所示损失。该损失限制带雾图像的特征和去雾图像的特征相同,也就是说,希望网络提取受雾影响小的特征,更好的解码得到去雾图像。
![]()
LEGM:结构如上图中(a)所示 ,即一个自注意力模块。即将两种特征连接后,计算空间注意力。
MASSM:结构如(b)所示。得到的多尺度特征,经过GAP(全局平均池化)和全连接后,得到注意力A,得到不同尺度特征的权重。
解码部分:
MFM:根据编码阶段的多尺度特征计算通道注意力。
深度估计模型:
扩张残差卷积。
误差感知驱动的深度估计
我们得到的去雾图像和GT之间的误差,可以反映去雾不理想的区域,这些区域也是深度估计困难的区域。通过限制去雾图像估计得到的深度,进一步提高了去雾模型性能,同时引入了去雾图像,提高深度估计的性能。

损失函数:

去雾模型的损失函数。权重为深度估计的误差经过卷积得到。VGG表示预训练模型的特征损失,使得去雾图像的特征靠近GT特征,远离带雾图像的特征。
损失包括UNet,depth,dehaze。
实验结果
这里部分对比方法没有用到深度信息。
消融实验:
排除了MSSAM和DE、DP,用求和代替LEGM、MFM,得到base模型,+表示在上一行的模型上添加该模块。
















 4025
4025











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









