







(一)信息熵
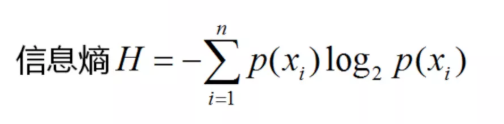
(二)信息增益( ID3算法 )

Gain(A)=I(A) -H(A)
信息增益的理解: 对于待划分的数据集D,其 entroy(前)是一定的,但是划分之后的熵 entroy(后)是不定的,entroy(后)越小说明使用此特征划分得到的子集的不确定性越小(也就是纯度越高),因此 entroy(前) - entroy(后)差异越大,说明使用当前特征划分数据集D的话,其纯度上升的更快。而我们在构建最优的决策树的时候总希望能更快速到达纯度更高的集合,这一点可以参考优化算法中的梯度下降算法,每一步沿着负梯度方法最小化损失函数的原因就是负梯度方向是函数值减小最快的方向。同理:在决策树构建的过程中我们总是希望集合往最快到达纯度更高的子集合方向发展,因此我们总是选择使得信息增益最大的特征来划分当前数据集D。
缺点:信息增益偏向取值较多
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3622
3622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









