









目录
3 Notations and Problem Formulation
4.1 Motif and Motif-Augmented Attributed Network Construction
4.2 Hybrid-Order Attributed Network Encoder
4.3 Hybrid-Order Attributed Network Decoder
4.4 Loss Function and Anomaly Detection
基于属性网络的混合阶异常检测
Hybrid-Order Graph Attention Network, HO-GAT:混合阶图注意力网络
摘要:基于属性网络的异常检测近年来收到了越来越多的关注。现有的检测方法大多只检测异常节点而不能检测异常子图。文章定义了一个新的基于属性网络的混合阶异常检测问题,以同时检测异常节点和子图。为此,提出一种新的深度学习模型——混合阶图注意力网络HO-GAT,该模型可以同时检测属性网络中的异常节点和模体实例。为了模拟节点和模体实例之间的相互影响,将节点表示和模体实例表示的学习过程集成到一个新的混合阶自注意力机制的统一图注意力网络中。在学习了节点表示和模体实例表示后,设计两个解码器分别重构节点和模体实例的属性信息以及它们之间的混合阶拓扑结构,将重构误差作为节点和模体实例的异常分数。在真实数据集上进行大量实验证实HO-GAT的有效性。
1 Introduction

大多数方法只关注单个节点级别的异常检测,只能从拓扑结构或属性相似程度上检测异常节点,无法检测到异常子图。然而,在拓扑结构或属性相似度方面检测偏离其他子图的异常子图是很重要的。例如:在社交商务平台上,一群用户可能会产生虚假的产品评论、评级和点击,从而提高目标商品的利润或达到某种恶意目的。检测垃圾用户群形成的异常子图,可以显著提高社交商务平台的服务水平。检测异常子图涉及到学习节点与子图之间以及子图之间的关系,是比检测异常节点更具挑战性的问题。目前在异常子图的检测需要基于查询的监督信息,无法在无监督的情况下检测异常子图,并且也不能同时检测异常节点和子图。
文章首次提出了一种基于属性网络的混合阶异常检测问题,目标是检测出在拓扑结构或属性相似度上明显偏离其他节点和子图的异常节点和子图,即除了检测常规定义的结构异常节点和属性异常节点外,还需要同时检测新定义的结构异常子图和属性异常子图。由于拓扑结构和节点属性中编码了异构但相关的信息,节点和子图的异常得分在拓扑结构和属性相似度方面相互影响,检测结构异常子图和属性异常子图使基于属性网络的异常检测更具挑战性。此外,与单个节点不同的是,应该检测哪些类型的异常子图是不清楚的。
为此文章提出一种新的混合阶图注意力网络HO-GAT深度学习模型,该模型能够同时检测属性网络中的结构/属性异常节点和结构/属性异常子图。子图的目标类型主要集中在广泛研究的高阶结构,把motif定义为复杂网络中出现的密集子图,其数量会显著高于相同节点的随机网络中的密集子图。密集子图是复杂网络的构建块,因此检测构建块的异常实例是合理的,即HO-GAT旨在同时检测结构/属性上异常节点和异常密集子图实例。
为了考虑节点和密集子图之间相互影响的情况下,低维节点表示和密集子图实例表示的学习过程集成到一个统一的图注意力网络,同时设计一个混合阶自注意力机制来捕获:1)节点到节点;2)节点到密集子图实例;3)密集子图实例到节点;4)密集子图实例到密集子图实例。在学习了节点表示和密集子图实例表示后,两个解码器重构原始节点和密集子图实例的属性信息以及节点和密集子图实例之间的混合阶拓扑结构。最后,将节点拓扑结构/属性信息和密集子图实例拓扑结构/属性信息的重构误差分别作为节点和密集子图实例的异常评分。
文章的主要贡献如下:
(1)首次定义了一种新的基于属性网络的混合阶异常检测问题,旨在检测拓扑结构或属性相似度上与其他节点和密集子图显著偏离的异常节点和异常子图。
(2)提出一种新的混合阶图注意力网络HO-GAT深度学习模型,能够同时检测结构/属性异常节点和结构/属性异常子图。
(3)在几个真实的数据集上进行了大量实验,验证了本文提出模型的有效性。
2 Ralated Work

3 Notations and Problem Formulation

定义一种新的基于属性网络的混合阶异常检测的问题:
定义1 基于属性网络的混合阶异常检测旨在同时检测出在拓扑结构或属性相似度方面显著偏离其他节点和子图的异常节点和子图。即除了检测出常规定义的结构异常节点和属性异常节点,还需要检测新定义的结构异常子图和属性异常子图。
定义2-5 Structure-Abnormal/Attributr-Abnormal Nodes/Subgraphs 指代基于拓扑结构或属性相似度显著偏离剩余网络包括其他所有节点和所有重要子图的异常节点或子图。
基于以上定义,有两个问题需要解决:一需要检测什么类型的异常子图是不清楚的,在属性网络中检测出最具代表性的子图,目前还缺乏研究([13][14][26]);二在拓扑结构或属性相似度上节点和子图的异常分数互相影响,如一些邻居节点会影响子图的异常分数([16])。
4 The Proposed Model

4.1 Motif and Motif-Augmented Attributed Network Construction
4.1.1 Motif
定义6 Motif :复杂网络中的密集子图,其出现次数明显大于具有相同节点数的随机网络;表示为,
分别是
个节点的集、
个边的集;
。使用Z-score来确认motif,即要找到Z-score最大的密集子图。文章主要研究含有3个节点、3条边的三角子图,但对其他子图也具有较好的扩展性。
定义7 Motif Instance:;节点的三元组
表示为
,即包含这三个节点的模体实例表示为
, 称作第
个模体实例。
定义8 Motif Instance Set:;包含网络中所有出现过的模体实例。
4.1.2 Motif-augmented Attributed Network Construction
Motif-augmented Attributed Network:将原始节点和模体实例作为模体增强节点,它们之间的互连结构作为连接结构,它们的属性信息作为模体增强节点属性信息。符号表示为 ,其中
分别代表模体增强的节点集、邻接矩阵以及节点属性向量集。
Motif-augmented Node Set 包含初始网络中
个节点以及
个模体实例的虚拟节点。
Motif-augmented adjacency matrix :
即如果第 个节点包含第
个模体实例,则认为第
个节点和第
个模体实例是连通的。
即如果第 个和第
个模体实例共享至少一个公共节点,则认为它们对应的虚拟节点是连通的。
Motif-augmented node attribute vector set 表示
motif-augmented节点的属性向量。前
个属性向量代表原始网络的属性向量,后
个代表模体实例的属性向量。用
表示第
个模体实例中的三个索引,如
,可以得到:
4.2 Hybrid-Order Attributed Network Encoder
HO-GAT主要关注四个方面:1)节点到节点;2)节点到模体实例;3)模体实例到节点;4)模体实例到模体实例。图注意力层用于将节点和motif实例的原始属性向量转换为低维表示向量,编码节点之间,节点和motif实例,motif实例之间的复杂关系。
图注意力层的输入是模体增强的节点特征向量集,即:
1)前个节点特征向量
表示
个原始节点的特征向量,初始化为第一个图注意力层的原始属性向量,即
2)后个节点特征向量
表示
个模体实例的特征向量,初始化为
个模体实例
的属性向量,即
图注意力层的输出是模体增强节点特征向量集,
,
图注意力层的的主要过程如下:首先使用一个经过权重矩阵 参数化的线性转换器在每一个模体增强节点上执行,即
。然后在模体增强节点上执行子注意力机制计算注意力系数:
注意力系数 代表节点
对于节点
的重要性;注意力机制
是一个经过权重向量
参数化的单层前馈神经网络,并对负输入应用斜率为0.2的非线性LeakyReLU函数:(||表示连接)
为了将模体增强属性网络的拓扑结构引入到注意力系数中,并使其在不同模体增强节点之间易于比较,使用基于邻居节点的softmax函数,将注意力系数进行归一化:
其中 表示模体增强节点
的邻居模体增强节点,且包括它自身,即:
归一化的注意力系数进一步用于计算每个模体增强节点输出的特征向量:
需要注意的是,权重矩阵和权重向量
在一个特定的图注意力层上被所有模体增强节点和模体增强节点对共享。
文章使用两个图注意力层来获取节点和模体实例之间在拓扑结构或属性相似度上的复杂交互影响。第一层的维度设置为第二层的两倍,即潜在表征的维度。经过编码后可以得到 模体增强节点的一组潜在表征集,符号表示为
,大小为
,即
。
4.3 Hybrid-Order Attributed Network Decoder
在获得潜在表征后,对模体增强属性网络进行重构,表示为 ;
表示重构的模体增强节点邻接矩阵,第
项表示模体增强节点
和节点
之间的连接强度;
表示重构属性向量;
表示第
个原始节点的重构属性向量;
表示第
个模体实例的重构属性向量。重构误差用来计算节点和模体实例的异常分数。
4.3.1 Topological Structure Reconstruction
计算两个节点潜在表征之间的内积,并应用sigmod激活函数来重构拓扑结构。
即第个模体增强实例的重构邻接矩阵为
。
4.3.2 Attribute Information Reconstruction
用全连接层重构 个原始节点以及
个模体实例的属性向量。对第
个原始节点进行重构:
其中 分别是可学习的权重矩阵和偏差。对第
个模体实例重构:
4.4 Loss Function and Anomaly Detection
4.4.1 Loss Function
HO-GAT模型的损失函数包括两部分:结构重构损失和属性重构损失。
对于结构重构损失,目标是最大化似然函数:
即最小化它的负对数似然误差:
对于属性重构误差,计算原始属性向量和重构属性向量的差值之和:
因此总的损失函数方程如下,其中 为正则化项以避免过拟合,
为HO-GAT模型中所有参数,
为超参数,设置为0.0015:
4.4.2 Anomaly Detection
根据重构误差对异常进行排序,即重构误差越大,该对象越有可能是异常。定义四种异常类型对应的异常分数如下:
1)Structure-Abnormal Nodes:第个原始节点
的结构异常分数
2)Attribute-Abnormal Nodes:第个原始节点
的属性异常分数
3)Structure-Abnormal Motif Instances: 第个模体实例
的结构异常分数
4)Attribute-Abnormal Motif Instances: 第个模体实例
的属性异常分数
5 Experiments
5.1 Experimental Settings
5.1.1 Datasets and Anomaly Generation
6个数据集:学者网社交网络数据集Scholat、科技情报平台合著者网络AMiner、4个超链接网页数据集WebKB
1)Scholat:学者为节点,两个学者之间的消息交互为边,使用带重启的广度优先搜索保留不大于50度的节点。利用PCA方法对相关学者的个人简介进行学者节点的属性向量表示。经过预处理和子集选择,包含2022个节点、2500条边和329个三角型模体实例。节点属性向量的维度为500,模体增强后边的数量为8361条。
2)Aminer:节点表示作者,边表示节点之间的合著关系,使用带重启的广度优先搜索保留不大于50度的节点。节点属性向量是作者出版物关键词的BOW表示。经过预处理和子集选择,包含2079个节点、3812条边和2611个三角型模体实例。节点属性向量的维度为133,模体增强后边的数量为55486条。
3)WebKB:四个数据集Cornell、Texas、Washington、Wisconsin分别包含195、187、203和265个网页。每个网页为一个节点,将两个网页之间的超链接看作节点的边;属性向量为0/1值的单词向量,表示大小为1703的字典中每个单词在网页中不存在/存在,即节点属性维度为1703。Cornell有195个节点、283条边、59个模体实例和819条模体增强边;Texas有187个节点、280条边、67个模体实例和1866条模体增强边;Washington有230个节点、366条边、99个模体实例和3065条模体增强边;Wisconsin有265个节点、459条边、120个模体实例和3039条模体增强边。
通过收集/生成结构异常节点(结构异常模体实例),使其拓扑结构明显偏离其他节点和三角模体实例。用分别表示结构异常节点和结构异常模体实例的百分比。首先生成属性异常模体实例,从实验目的考虑,设置属性异常模体实例的比例与结构异常模体实例相同,即
;同理属性异常节点的百分比为
。对每个候选属性异常模体实例
,从数据集中随机选取50个模体实例,基于Euclidean距离选取与
平均属性向量偏差最大的模体实例
,将候选属性异常模体实例
包含的三个节点属性向量替换为模体实例
的三个节点属性向量;这样就生成一个属性异常模体实例
。在生成属性异常模体实例的过程中,也生成一些属性异常节点;为保持占比一致,需要生成更多恶的属性异常节点。对每个候选属性异常节点
,从数据集中随机选取50个节点, 基于Euclidean距离选取与
属性向量偏差最大的
,将候选属性异常节点
的属性向量替换为
的属性向量。
5.1.2 Baselines and Settings
1)AMEN:采用集成模块化和加权属性相似度检测属性网络上的异常领域,只能检测到异常子图,不能发现异常节点;因此将异常子图包含的节点视为异常节点,节点的异常分数等于子图的异常分数。
2)ANOMALOUS:基于CUR分解和残差分析进行属性选择和异常检测的联合建模方法。
3)Dominant:基于图卷积网络的框架,包括一个属性网络编码器和两个重构结构/属性的解码器。
4)Radar:基于属性网络残差分析的异常检测,同时考虑了属性信息的残差以及与网络信息的关联性。
方法2、3、4无法发现异常子图,因此对于任何一个三角模体实例,如果所包含的三个节点被检测为异常,则认为该三角模体实例是异常的;这个模体实例的异常分数为三个节点异常分数的平均值。HO-GAT的潜在表征维数设置为64。
5.1.3 Evaluation Measures:Precision@k、Recall@k
5.2 Comparison Results
5.2.1 Comparison Results on Scholat

采用两组异常比进行实验。在异常节点检测方面,HO-GAT与其他四种方法相比没有明显的改进,但在模体实例的异常检测上实现了平均大于100%的改进。
5.2.2 Comparison Results on AMiner
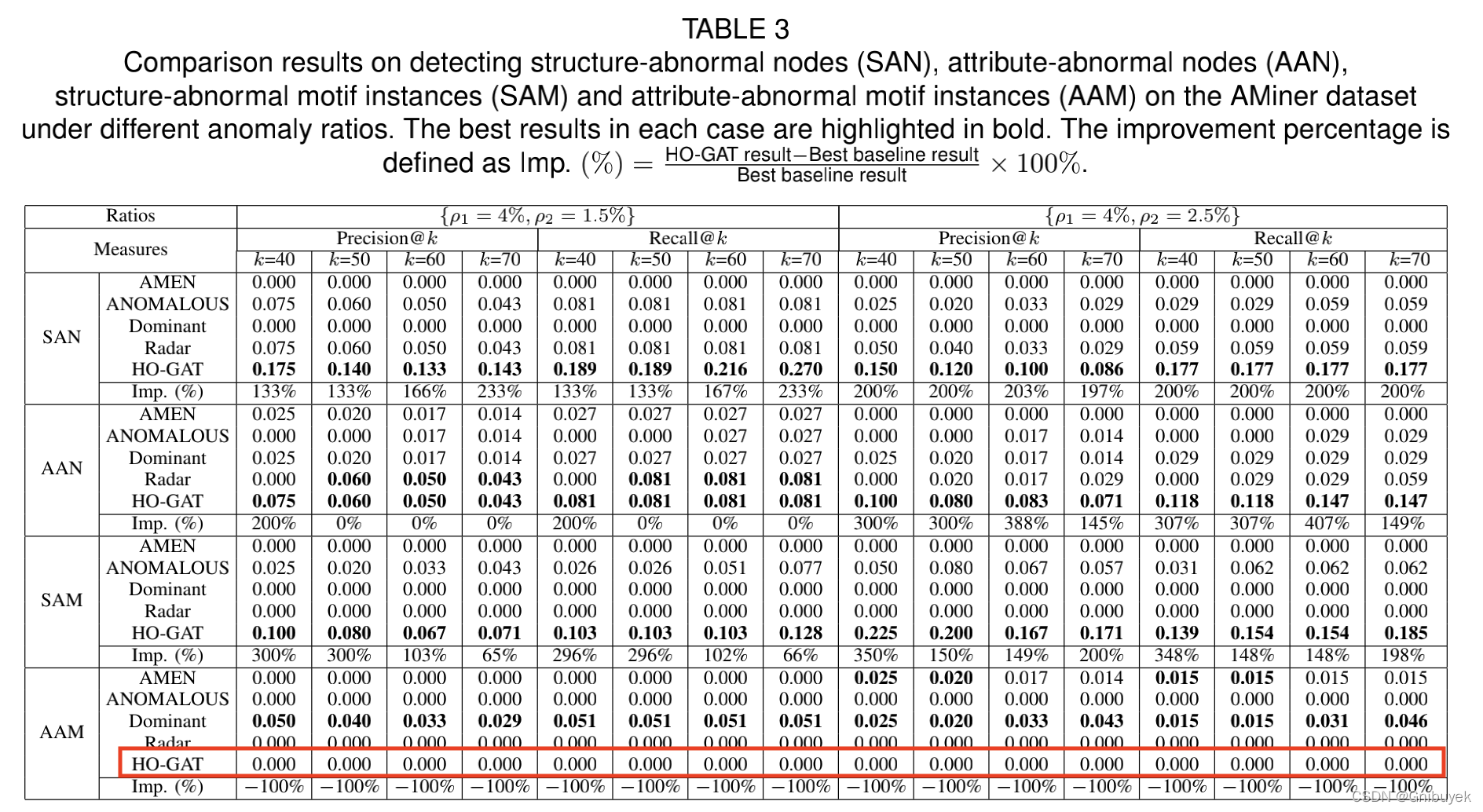
采用两组异常比进行实验。HO-GAT在异常节点检测上与其他四种方法相比只取得了很小的改进。然而在SAM任务上的性能提高也不显著,更糟糕的事,在属性异常模体实例检测任务(AAM)中无法检测到出来,精度和召回率都为0。这是因为采用的属性异常模体实例生成方法并不能生成模体实例的异常属性向量,将一个模体实例中三个节点的属性向量替换为另一个模体实例的属性向量时,其平均属性向量变化并不大,即并没有明显的偏差,因此没有被大多数方法检测到。

进一步在测试集添加随机噪音的属性向量生成的属性异常模体实例,可以看出所有关于属性异常模体实例检测的方法都有所提高,并且大多数情况下HO-GAT比其他4种方法有更大的提高。
5.2.3 Comparison Results on Four WebKB Datasets

采用异常比进行实验。与Scholat和AMiner数据集类似,HO-GAT在检测结构/属性异常节点上的改进并显著,但实现了检测结构/属性异常模体实例的明显改进。
5.3 Parameter Analysis
5.3.1 Latent Dimension

将Scholat和AMiner的异常比分别设为和
。将四个WebKB数据集的异常比设为
。大多数情况下,HO-GAT的性能对维度
的值并不敏感;然而在某些情况下使用不同维度
性能会发生变化。从表中得出表现最好的结果大多数设置了64的潜在维度,因此实验采用
。
5.3.2 Regularization Parameter

在异常比为的Scholat数据集上验证正则化参数
的影响,对比
。HO-GAT的性能在大多数情况下非常稳定,只有在属性异常节点检测上略有变化。考虑到正则化的影响,将
设置为我们尝试过的中值,即0.0015,这也是被广泛采用的默认值。
5.4 Case Study

在异常比为的Scholat数据集进行实例研究,受篇幅限制,只研究结构异常模体实例检测和属性异常模体实例检测。
图4(a)为拓扑网络图,其中模体实例2311由节点862、1059和1299组成。在异常生成过程中,去除模体实例2311与其他节点之间的边,得到孤立的模体实例。因为模体2311是所有模体实例中结构异常分数最大的,所以它可以被正确的识别为结构异常的模体实例。
图4(b)为引入属性异常后的属性网络图,其中模体实例2317有节点1054、1055和1463组成:节点的属性用色块表示,可以看到节点1054、1055和1463的属性与相邻节点有显著差异。在经过模块增强步骤后,模块实例2317仍然与其他节点模体实例的属性有所不同。因为模体实例2317在所有模体实例中属性异常得分最高,因此可以被正确的识别为属性异常模体实例。
6 Conclusions
论文定义了一种基于属性网络的混合阶异常检测问题,同时检测结构/属性异常节点和异常模体实例。为此设计了一种新的深度学习模型,混合阶图注意力网络HO-GAT。首先构造一个模体增强的属性网络,对混合阶结构和属性进行建模;然后将模体增强的属性网络输入到混合阶属性网络编码器,生成模体增强节点的潜在表征。还设计了一种新的混合阶自注意力机制,模拟节点与模体实例之间在拓扑结构/属性相似度上的复杂交互影响。在获得模体增强节点的潜在表征后,设计了混合阶属性网络解码器,重构节点和模体实例的属性信息以及它们之间的混合阶拓扑结构。最后利用重构误差分别作为节点和模体实例的异常评分。在真实数据集上进行的大量实验证实了HO-GAT的有效性。















 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









