







名词解释:
Machine Learning Aided Load Balance Routing Scheme Considering Queue Utilization, MLQU:考虑队列利用率的基于机器学习的负载均衡路由算法
QoS-oriented Adaptive Routing Scheme Based on Deep Reinforcement Learning, QAR:面向QoS的基于深度强化学习的自适应路由算法
Principal Component Analysis, PCA:主成分分析
QoS Routing Strategy with Resource Allocation, QRRA:基于资源分配的QoS路由算法
Deep Deterministic Policy Gradient, DDPG:深度确定性策略梯度
Non-deterministic Polynomial-Hard, NP-Hard:多项式时间复杂度归约
摘要:文章提出一种考虑队列利用率的基于机器学习的负载均衡路由算法MLQU,并在此基础上提出面向QoS的基于深度强化学习的自适应路由算法QAR,主要贡献可以归纳为四点:(1)构建了基于抖动图的网络模型和基于泊松过程的数据流模型,从而更好地结合网络元素和数据流信息确定QoS值,得到一个可以有效表示网络拓扑的低维向量。(2)MLQU算法利用网络流量预测模型感知未来网络态势,确定高效灵活 的智能路由方案。其中神经网络采用数据流请求、网络拓扑和路由器队列利用率作为输入,预测下一时刻队列利用率。(3)利用排队论建模基于资源分配的QoS路由问题,提出基于资源分配的QoS路由算法。(4)QAR算法采用深度 确定性策略梯度捕捉网络状态以及数据流的动态变化,完成面向QoS的自适应负载均衡路由。仿真结果表明,本文提出的算法在丢包率、吞吐量和队列时延方面均优于传统策略。
第一章 绪论
1.1 课题研究的背景和意义
QoS路由问题属于特殊的组合优化问题,同时考虑多个QoS约束很难制定最优路由策略,无法在多项式时间复杂度内归约NP-Hard。即使基于时延限制的最优路由方案制定,也要对所有满足时延上限约束的路径进行比较得到费用最小的那条,求解过程也是NP难的。
现阶段负载均衡智能路由算法的主要问题有三点:(1)节点表示学习中网络数据结构往往是稀疏的,因此保留结构属性以及可扩展性是一个很大的挑战。(2)现有智能路由算法需要大量网络场景中的数据驱动,给出的策略往往基于数据,仍然需要很长时间才可以落地到真实环境中。(3)如何更好的适应数据流请求评价指标的多样性以及复杂网络环境中的高动性?
1.2 国内外研究现状
1.2.1 最短路径路由算法
Dijkstra算法:集中式算法,路由器根据整个物理网络的拓扑结构计算最短路径,对变化响应更快,可以给路由过程提高更多的控制,但需要更强的处理能力。路由过程可以基于链路带宽、线路费用以及拥塞避免等各种优先级别。路由器启动后,先计算到邻节点的距离并与邻节点进行信息交互,然后将自己到邻节点的距离广播给全部路由器。各个路由器都保存完整的网络拓扑图,直接使用算法确定数据流请求的最短路径。
Bellman-Ford(BF)算法:分布式路由算法,路由器无需获得整体拓扑,即可搜索最短路径。根据源节点到目的节点的跳数进行分组传送路由,由各相邻的路由器提供跳数作为流表信息。路由器保存一张路由表,相邻的路由器之间会实时沟通路由表中的数据。表的每行对应网络中的一个路由器,包含目的路由器的网口号和对应的距离两个信息。每个路由器根据收集到的信息,对到达目的路由器的距离不断进行更新。
1.2.2 QoS路由算法
QoS路由方法LARAC:使用拉格朗日松弛求解延迟受限的最小费用路由问题,在理论上最优解的基础上,通过进一步放松路径的最优性,权衡控制算法的运行时间与路由结果的质量。
1.3 研究内容和创新点
(1)根据已知的网络节点链路连通情况得到底层网络拓扑图,利用主成分分析方法PCA对底层网络进行降维得到一个低维底层拓扑特征。(2)MLQU利用神经网络预测下一时刻的队列利用率,根据预测结果进行负载均衡路由。(3)QRRA是依赖于网络环境和负载设计的启发式算法,对多个路由器级联的路径进行数学建模以及简化得到一个排队系统,从而确定其可用性以及对应的资源分配方案。(4)QAR基于DDPG算法确定以及调整具体的可行路由方案来适应实时动态变化的网络状态以及数据流请求。
MLQU算法首先选择简单的神经网络对数据流模式、当前队列利用率情况以及网络拓扑情况进行一个全面的分析,从而准确预测物理网络中各个路由器的下一时刻队列利用率。
QRRA算法首先基于抖动图构建网络模型和基于Poisson过程构建数据流模型,然后结合网络元素和数据流信息,在给定的排队时延和丢包率约束下选择可行路径集,最后通过最大化物理网络的可用资源实现负载均衡。
QAR算法基于DDPG模型确定以及调整具体可行的路由方案来适应实时变化的网络状态以及数据流请求。数据包进入路由器后,根据QAR算法预测结果进行下一跳路由动作,然后网络环境会给当前智能体反馈对应的奖励值,最终完成DDPG模型的更新。
第三章 基机器学习的负载均衡路由策略
3.1 队列利用率预测模块
利用神经网络进行路由器队列利用率预测,对模型进行设计以及初始化,通过最小化损失函数训练预测模型,筛选出一个泛化性强的模型实现准确预测。

3.2 负载均衡路由
MLQU综合考虑面向目的节点的路由条数、动态属性队列利用率和静态属性网络节点重要性三个指标,组合得到一个值进行路由决策。即根据路由器 当时刻队列利用率
和下一时刻队列利用率
计算一个组合值
:
其中分别对应
的权重系数,满足
。设置
。
确定了网络中所有节点的值后,路由器
从邻节点
中找到所有可用的下一跳路由
:
其中 表示路由器
到目的路由的距离不多于
,
说明路由器
的队列有可用的缓存资源。每个路由器在离散时间
选择下一跳:
MLQU路由方案允许每个路由器选择可用资源最大且到目的节点距离相同或更小的邻节点作下一跳。虽然所选的下一跳可能不满足最小路由跳数,但是加入了路由器可用缓存资源的考虑。
3.3 实验结果分析
3.3.1 仿真环境与数据
使用Python的网络库Networkx调用随机算法生成一个网络拓扑作为路由算法的仿真环境,为避免网络过于稀疏,设置每个节点的度为3,在30个节点和45条链路组成的网络中测试。网络中所有节点代表可以生成、转发和处理数据包的路由器,可用CPU资源是5个数据包/秒,队列缓存空间是8个数据包,缓存填满后数据包被丢弃。考虑整个网络的可用资源,设置数据包的生成速率为30个数据包/秒,队列利用率更新频率为1次/秒。
3.3.2 模型设置

3.3.3 实验结果
比较四种路由方案在不同数据流模式的平均丢包率、最差吞吐量以及平均时延。


图3-8:MLQU算法考虑到路由器的队列利用率,可以很好地避免数据包传输到可用缓冲资源较少的路由器,具有较低的丢包率。
图3-9:MLQU和DLQU同时考虑了当前和预测的队列利用率,因此最差吞吐量最高,较好实现了高效的负载均衡路由。
图3-10:MLQU和DLQU的平均时延比BF多20%,作为更优丢包率和吞吐量性能的折中,稍高的平均时延是可以接受的。
第四章 基于资源分配的QoS路由策略
4.1 泊松过程
4.1.1 数据流模型
排队系统的容量N是服务器C和缓存器的数据包之和,路由器在系统容量到达上限时丢弃数据包。数据流请求满足两个特征:(1)不重叠时间内到达的分组数是彼此独立的随机变量;(2)时间间隔 内到达的分组遵循
的泊松分布:
网络提供的服务满足参数 的指数分布,记作
:
若排队系统中的数据包少于等于C,有些服务器将处于空闲状态,否则数据包将在缓存队列等待服务。我们的目标是在保证数据流请求服务的同时最大化网络资源利用率。

4.1.2 排队论模型
给定数据流请求,需要选择合适的路径在满足约束的前提下最大化可用资源,尽可能多地为
提供带宽、服务器和缓存资源,从而保障网络的QoS。网络节点可以看作具有一般截断功能的多通道队列,给定服务器数
,缓存队列
,系统容量
的排队系统,可以确定状态空间
上的服务率
:
以及转移矩阵:
状态概率 满足以下公式:
其中 是排队系统在
时刻有
个数据包的概率。通过长期迭代,系统将处于稳定状态
。
简化状态概率的表示,分配给每个队列状态一个参数
:
于是得到状态概率:
其中是数据流请求的密度,根据上式可得排队系统空闲的概率:
队列长度用在缓存器中等待传输的数据包表示:
排队时延 与队列长度
成正比:
其中数据包的实际到达率 ,当且仅当所有服务器都繁忙且缓存队列可用时数据包才会等待。
4.2 基于资源分配的QoS路由

第五章 面向QoS基于DDPG的自适应路由策略
第四章中 QRRA 算法仅针对一个数据流请求进行路由,然而每个请求的路由决策都会影响网络中其他数据流的服务。
5.1 强化学习框架
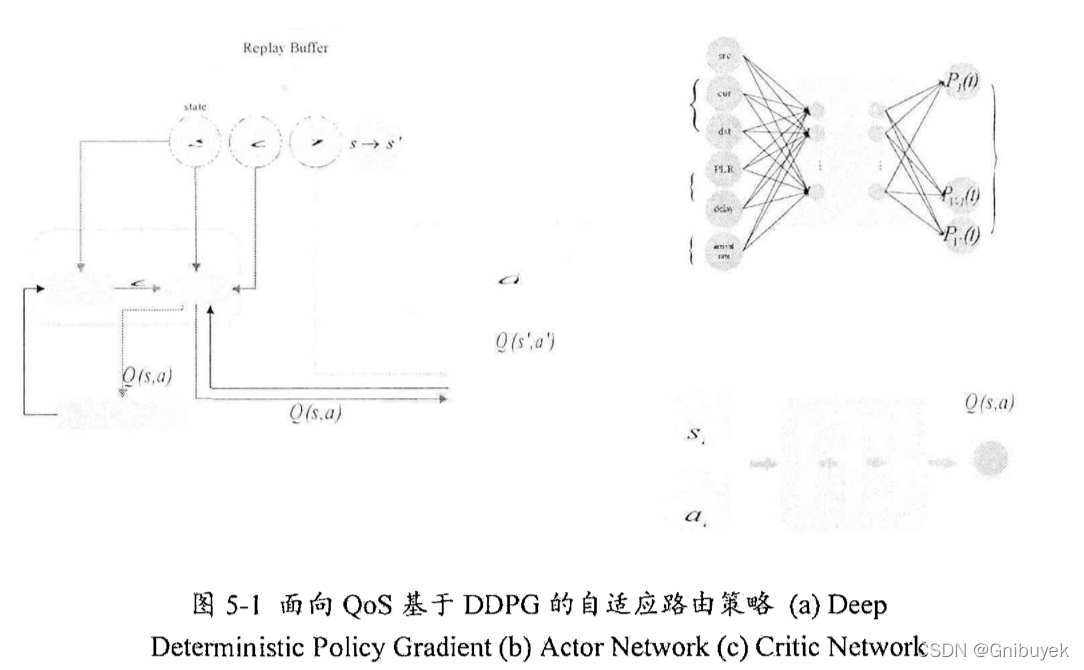
DDPG是一种深度强化学习策略,利用低维观测信息学习得到高效的策略。其框架由基于演员-评论家算法的主网络和目标网络组成,Actor Network和Critic Network分别代表ac算法中的演员和评论家。Actor Network旨在根据当前网络状态确定最佳动作,其输入是实时网络状态,输出是每个路由器被选择的概率
。Actor Network内部的参数
利用策略梯度进行更新,通过激活函数 softmax 确保输出值的总和等于1,从而决定下一时刻施加到真实网络环境中的最优动作。Critic Network旨在根据状态和相应的QoS路由操作,给Actor Network的表现打一个分数
,然后根据系统给出的奖励值调整打分策略,即Critic Network的参数。
5.2 面向QoS基于DDPG的自适应路由算法
5.2.1 DDPG
DDPG模型的关键部分是Actor Network和Critic Network,特别是其主网络和目标网络的更新。
Primary Actor Network(Actor_P):根据给定数据流请求和网络状态,得到下一跳选择动作的概率分布
:
用于从数据包当前位置的相邻路由器中选择概率最大的路由器作下一跳。给定状态,Actor_P旨在最大化长期累积奖励的期望值,即Critic_P的预测值:
目标函数的梯度与 值对
求导等效,因此Actor_P会根据Critic_P计算得到的目标奖励
,通过反向传播更新网络参数:
Primary Critic Network(Critic_P)旨在获得用于更新Actor_P的 值。Critic_P的更新与DQN相似,损失函数
,其中
。DDPG算法只需通过Target Critic Network(Critic_T)评估Target Actor Network(Actor_T)得到的
,无需遍历动作空间即可获得
。因此可以通过最小化损失函数来更新Critic_P的参数:
Target Network(Critic_T,Actor_T) 根据输入的状态得到策略以及对应的奖励
训练Critic_P。
5.2.2 奖励函数

5.2.3 QAR路由算法

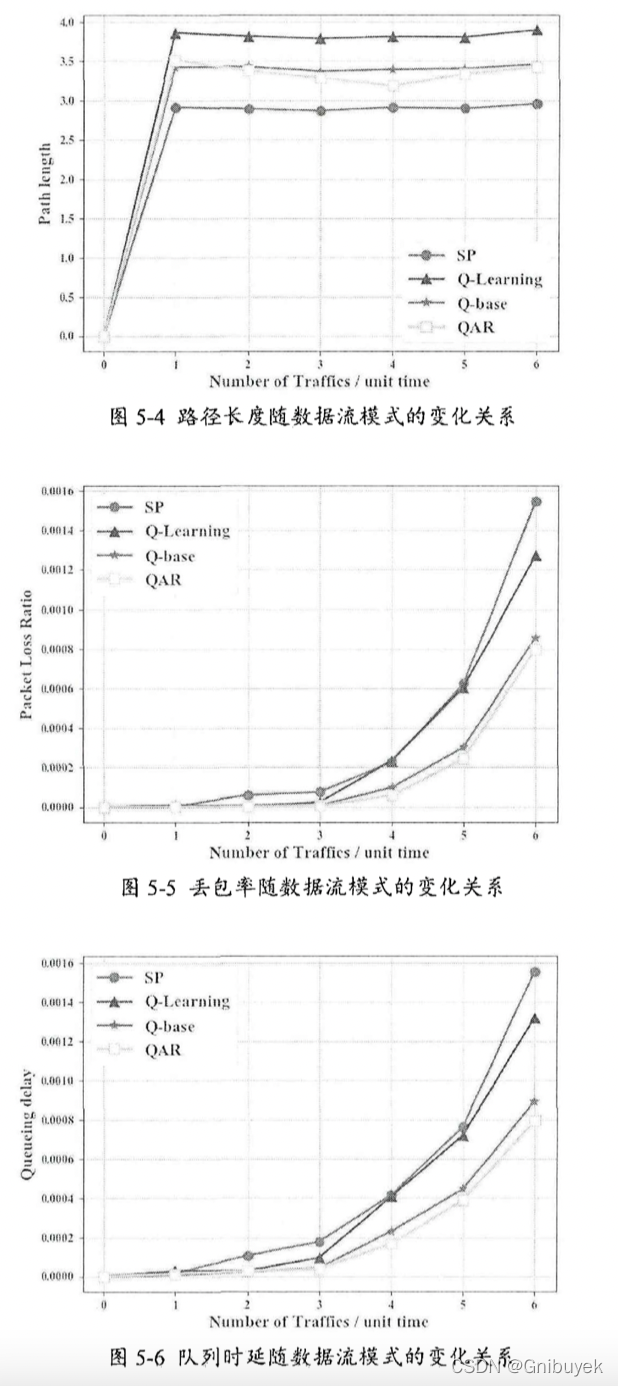
5.3 实验结果分析
设计了三个对比实验评估QAR路由算法:最短路径路由算法SP(基准)、采用Q-Routing算法将Q-Learning用于路由,并以0.1的概率进行探索、Q-base。
第六章 总结与展望
4个创新点:
(1)为了确定QoS值与网络不同资源之间的关系,构建了基于抖动图的网络模型和基于泊松过程的数据流模型,更好地结合网络元素和数据流信息。由于传统的网络节点重要性指标包含的信息有限,因此在拓扑提取中引入PCA方法,得到一个低维向量矩阵,有效表示每个路由器的连通性。
(2)数据流请求和网络状态蕴涵了网络运行的关键信息,因此对网络流量的分析与预测十分重要。考虑到数据流的动态性,使用机器学习探索数据流模式,网络拓扑和路由器队列状态之间的关系。MLQU算法采用神经网络预测下一时刻的队列利用率,并将其用于负载均衡智能路由决策。
(3)针对不同的网络环境,监督学习需要处理大量的数据,进行模型的重新训练以及适配,因此需要一种基于强化学习的路由方案。同时为了保证该方案的可靠性和可解释性,需要一种启发式路由策略。QRRA算法数据建模基于资源分配的QoS路由问题,并利用启发式方法简化问题从而在有限时间内给出可行解。
(4)每个数据流请求的到来以及离开都会造成物理网络的变化,本文提出的QAR算法基于DDPG模型设计状态空间、动作空间以及奖励函数,从而捕捉网络状态以及数据流请求的动态变化完成高效的自适应负载均衡智能路由。
4个展望:
(1)网络状态对负载均衡智能路由算法非常重要,之后将抽取更多路由器以及链路的特征,从而得到更好的训练结果。根据网络链路带宽得到的邻接矩阵,构造包含链路信息的特征向量,从而减少带宽不足导致的丢包。
(2)PCA可以高效地提取数据特征,目前被广泛用于数据降维以及分析。之后将尝试其他方法来获得底层网络拓扑的有效表示,如等距特征映射、局部线性嵌入,从而保留物理网络非线性变换得到的拓扑信息。
(3)关注算法对多样化服务性能优化目标通用性的验证。
(4)关注仿真环境的设计构建,从而减少甚至消除仿真平台与真实环境间的差距。















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









