




 文章详细介绍了Affinity Propagation(AP)聚类算法,这是一种基于图论的无监督学习方法。AP通过计算样本间的吸引度和归属度进行迭代更新,不需要预设类别数量,适用于各种数据集。在scikit-learn库中使用AP进行聚类,并讨论了算法的参数选择和性能特点。
文章详细介绍了Affinity Propagation(AP)聚类算法,这是一种基于图论的无监督学习方法。AP通过计算样本间的吸引度和归属度进行迭代更新,不需要预设类别数量,适用于各种数据集。在scikit-learn库中使用AP进行聚类,并讨论了算法的参数选择和性能特点。
欢迎关注”生信修炼手册”!
Affinity Propagation简称AP, 称之为近邻传播算法, 是一种基于图论的聚类算法。将所有样本点看做是一个网络中的节点,图示如下
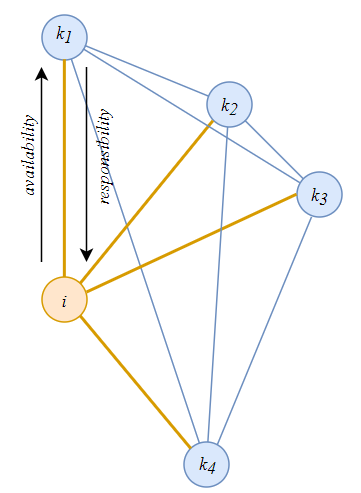
在样本点构成的网络中,每个样本点都是潜在的聚类中心,同时也归属于某个聚类中心点,对应这样的两面性,提出了以下两个概念
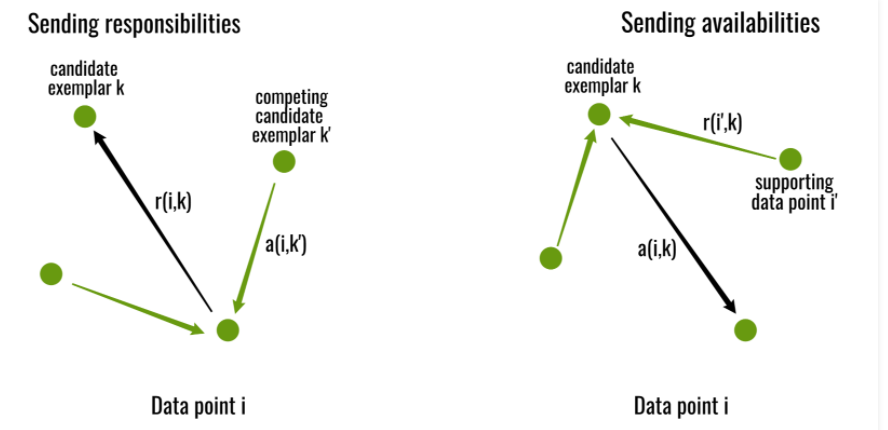
1. responsibility, 吸引度,对于(i, k)而言,定量描述样本k作为样本i的聚类中心的程度
2. availability,归属度,对于(i, k)而言,定量描述样本i支持样本k作为其聚类中心的程度
具体的定义方式如下
1. Similarity
相似度,这里的定量方式是欧氏距离的负数,公式如下
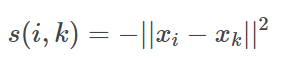
之所以如此定义,是为了对称性的考量,图这个数据结构的最常见表示方式就是邻接矩阵了,图示如下
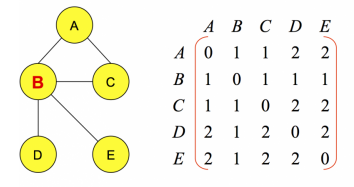
基于相似度,我们可以得到样本点之间的相似度矩阵。在该相似度矩阵中,对角线的值为样本自身的距离,理论上是0,但是为了后续更好的应用相似度来更新吸引度和归属度,引入了preference参数。
这个参数就是定义相似度矩阵中对角线上的值,是认为设定的,比如可以取相似度的均值或者中位数。在scikit-learn中,默认用的就是中位数。
这个参数会影响聚类的类别数目,该值越大,聚类的类别数越多。
2. Responsibility
吸引度,公式如下
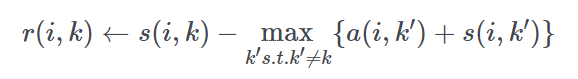
3. Availability
归属度,公式如下
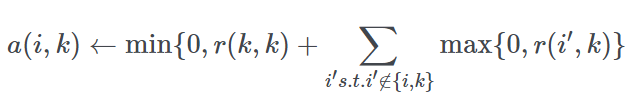
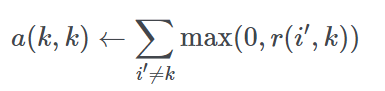
对于网络中的所有节点,借助邻接矩阵的思想,我们可以计算得到吸引度矩阵R和归属度矩阵A。
AP算法通过迭代的方式来达到聚类效果,每次迭代其实就是更新上述两个矩阵的值, 在更新的时候,引入了一个叫做dumping factor的参数来控制更新的幅度,公式如下
r(i,k)new = λ*r(i,k)old + (1-λ)*r(i,k)
a(i,k)n 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









