







 本文介绍了一种名为ONE-PEACE的通用预训练模型,它能够处理多种模态的数据,通过跨模态对比学习和单模态噪声消除学习进行对齐,以实现模态间的高效交互。模型包括VisionAdapter、AudioAdapter和LanguageAdapter,分别针对图像、音频和文本进行独立编码后融合。
本文介绍了一种名为ONE-PEACE的通用预训练模型,它能够处理多种模态的数据,通过跨模态对比学习和单模态噪声消除学习进行对齐,以实现模态间的高效交互。模型包括VisionAdapter、AudioAdapter和LanguageAdapter,分别针对图像、音频和文本进行独立编码后融合。
ONE-PEACE: EXPLORING ONE GENERAL REPRESENTATION MODEL TOWARD UNLIMITED MODALITIES
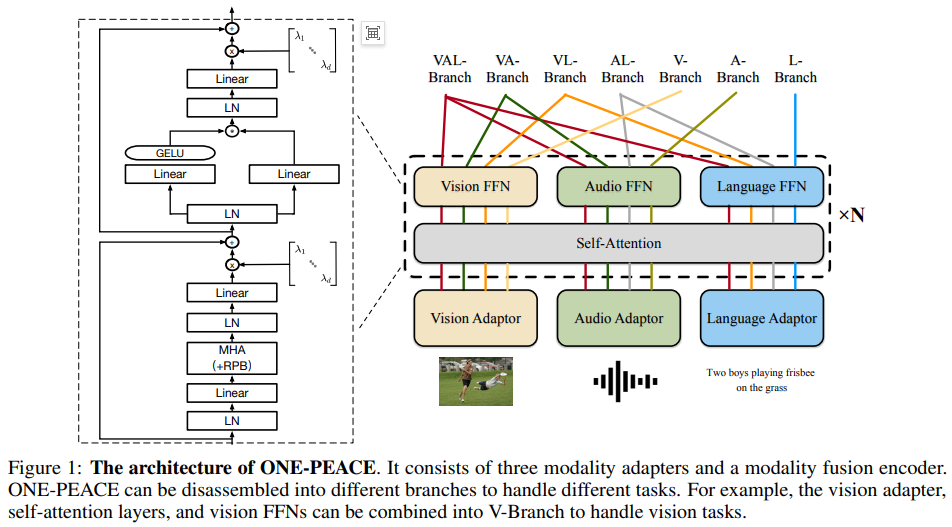
适应不同模态并且支持多模态交互。
预训练任务不仅能提取单模态信息,还能模态间对齐。
预训练任务通用且直接,使得他们可以应用到不同模态。
各个模态独立编码,然后模态融合。
Vision Adapter:使用hierarchical MLP (hMLP) stem对图像分块,直到patch size 16 × 16,不同块之间没有交互。然后打成patch 特征序列,再加一个类别前缀向量,并加上绝对位置编码。得到:![]()
Audio Adapter (A-Adapter):16kHz采样,归一化数据,使用卷积提取相对特征。得到:![]()
Language Adapter (L-Adapter):先变成subword sequence-->加上[CLS] and [EOS]-->embeddings-->absolute positional embeddings-->![]()
预训练任务包括:cross-modal contrastive learning and intra-modal denoising contrastive learning
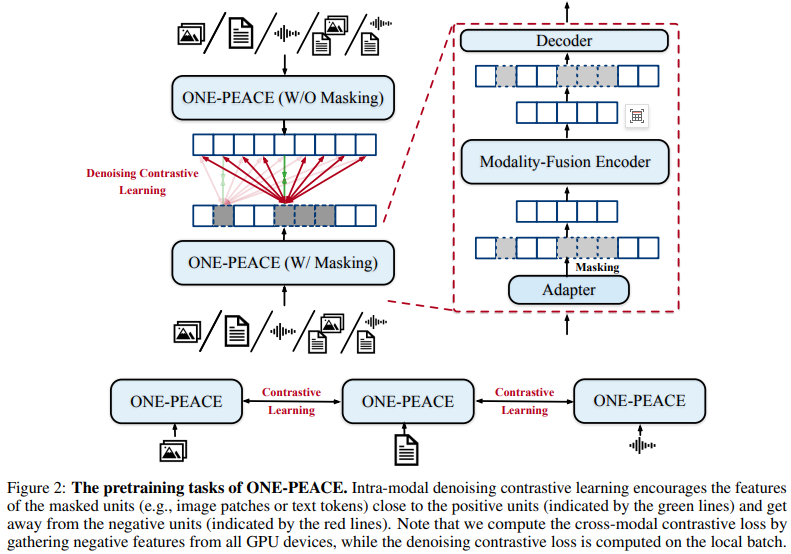
Cross-Modal Contrastive Learning:不同模态之间语义空间对齐。
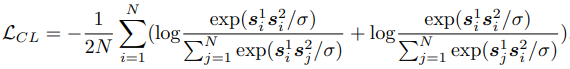
Intra-Modal Denoising Contrastive Learning:单模态内部更精细的细节。















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









