




 文章介绍了BLIP模型,一种通过结合单模态编码器、基于图像的文本编码器和解码器,以及三种损失函数来进行语言图像预训练的方法。CapFilt模块通过生成字幕和过滤噪声,提高数据质量,实验表明BLIP在大规模数据和模型扩展性上有良好表现。
文章介绍了BLIP模型,一种通过结合单模态编码器、基于图像的文本编码器和解码器,以及三种损失函数来进行语言图像预训练的方法。CapFilt模块通过生成字幕和过滤噪声,提高数据质量,实验表明BLIP在大规模数据和模型扩展性上有良好表现。
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
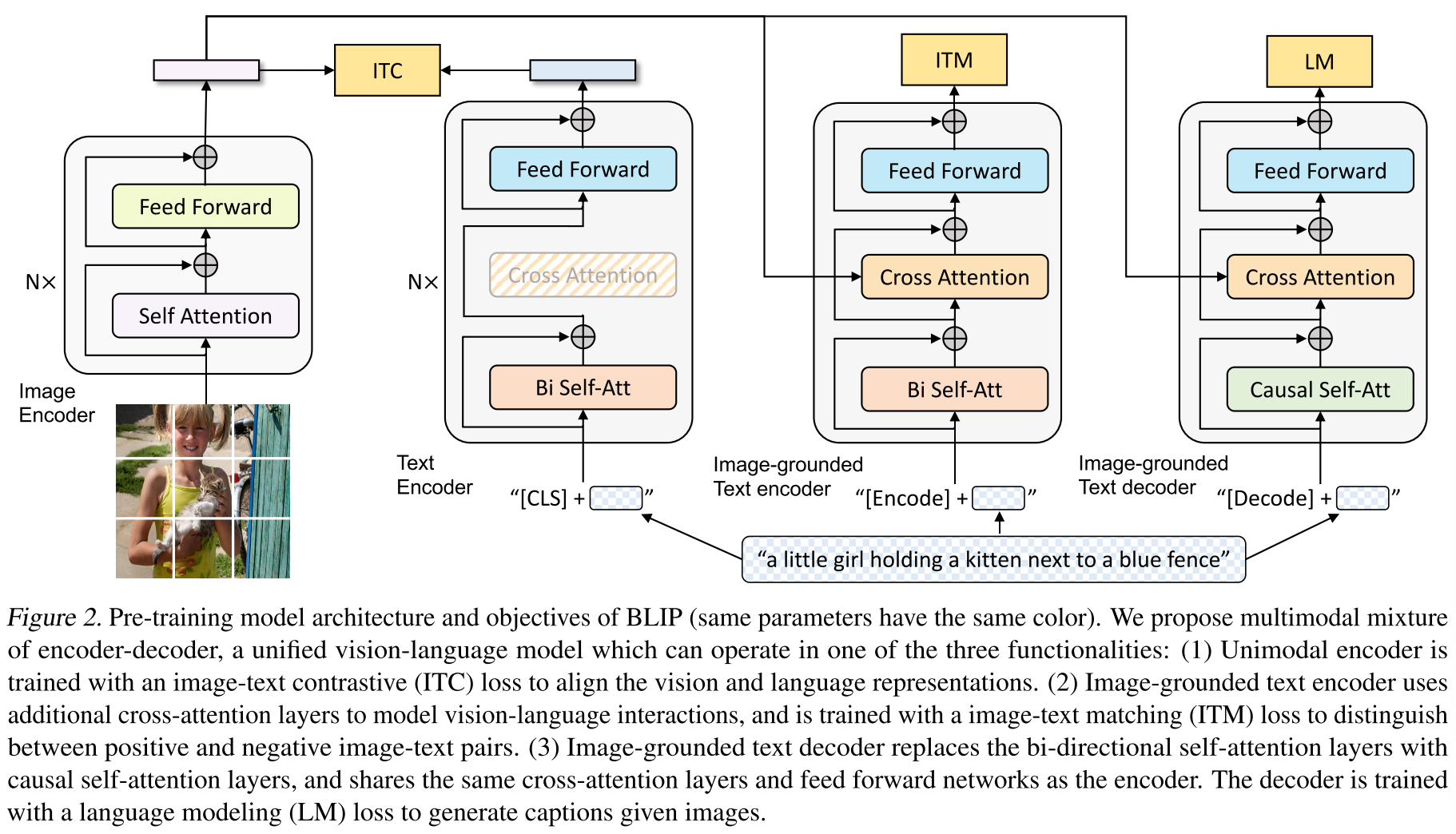
(1)单模态编码器,它分别对图像和文本进行编码。图像编码器用ViT,并使用附加的 [CLS] 标记来表示全局图像特征。文本编码器与 BERT 相同(Devlin et al., 2019),其中 [CLS] 标记附加到文本输入的开头以总结句子。
(2)基于图像的文本编码器,通过在文本编码器的每个变换器块的自注意(SA)层和前馈网络(FFN)之间插入一个额外的交叉注意(CA)层来注入视觉信息。特定于任务的 [Encode] 标记被附加到文本中,并且 [Encode] 的输出嵌入用作图像-文本对的多模态表示。
(3)基于图像的文本解码器,用因果自注意力层替换基于图像的文本编码器中的双向自注意力层。 [Decode] 标记用于表示序列的开始,序列结束标记用于表示序列的结束。
三个损失:
Image-Text Contrastive Loss (ITC)
Image-Text Matching Loss (ITM):
&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2308
2308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









