










AI Agent概述
AI Agent旨在理解、分析和响应人类输入,像人类一样执行任务、做出决策并与环境互动。它们可以是遵循预定义规则的简单系统,也可以是根据经验学习和适应的复杂、自主的实体;可以是基于软件的实体,也可以是物理实体。它们被用于各种领域,包括机器人、游戏、虚拟助理、自动驾驶汽车等。这些智能体可以是反应性的(直接对刺激做出反应)、深思熟虑的(计划和决策),甚至具有学习能力(根据数据和经验调整它们的行为)。
为什么需要AI Agent
为什么大语言模型(LLM)刚流行不久,就需要AI Agent呢?
因为在特定行业场景中,通用大模型具有的泛化服务特性,很难在某些特定领域知识问答、内容生成、业务处理和管理决策等方面精准满足用户的需求;同时LLM仅限于它们所训练的知识,并且这些知识很快就会过时。
LLM的一些缺点:
- 会产生幻觉。
- 结果并不总是真实的。
- 对时事的了解有限或一无所知。
- 很难应对复杂的计算。
这些缺点就是AI Agent的用武之地,它可以利用外部的知识库、长短期记忆以及其他外部工具来克服这些限制。
这里的工具是什么呢?工具就是代理用它来完成特定任务的一个插件、一个集成API、一个代码库等等,例如:
- 搜索:获取最新信息
- Python REPL:执行代码
- Wolfram:进行复杂的计算
- 外部API:获取特定信息
- 向量数据库:进行记忆存储
AI Agent 和大模型的还有一个区别在于,大模型与人类之间的交互是基于 prompt 实现的,用户 prompt是否清晰明确会影响大模型回答的效果。而 AI Agent的工作仅需给定一个目标,它就能够通过控制端、感知端、执行端的配合来针对目标独立思考并做出行动。
AI Agent的类型
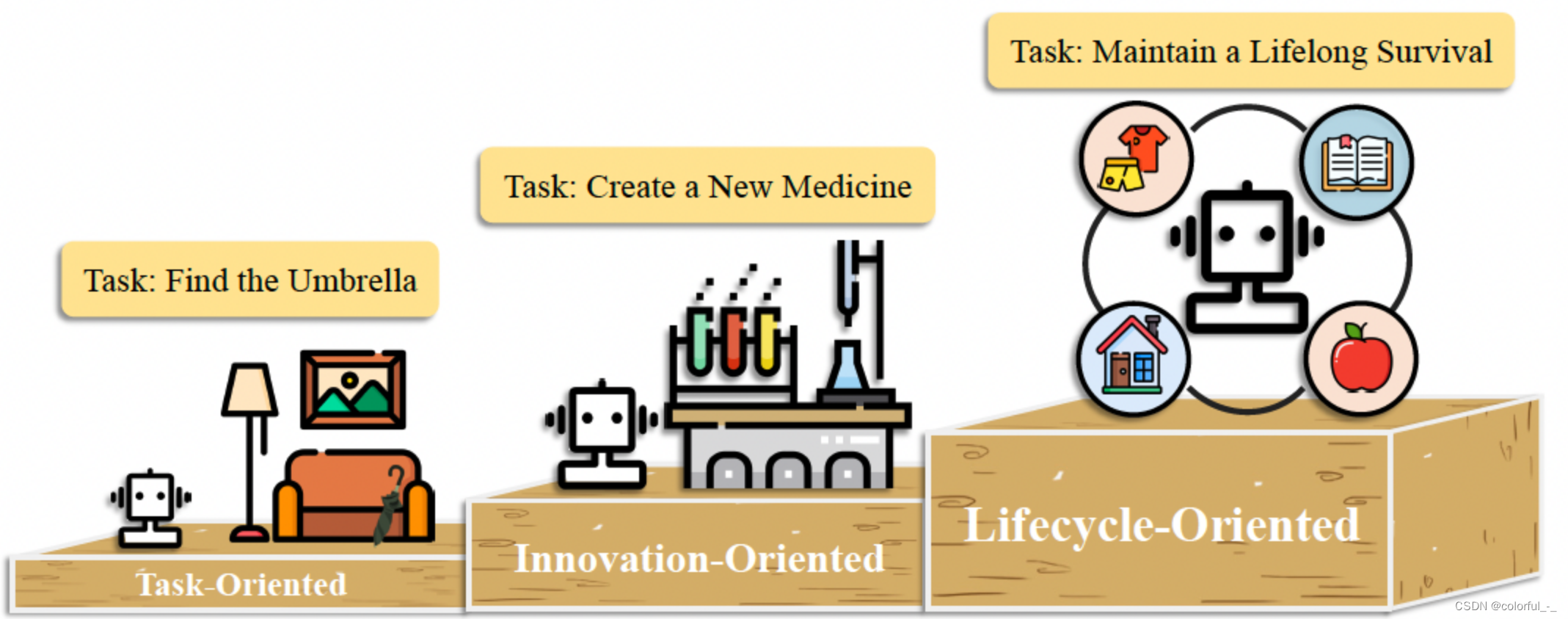
从工作模式来看,AI智能体可以分为单Agent、多Agent、混合Agent(人机交互Agent)三种类型:
单Agent:这种代理侧重于执行单一任务或一系列相关任务,且不需要与其他智能体进行交互。单个代理可以根据任务执行不同的操作,如需求分析、项目读取、代码生成等。例如手机上的Siri或Google Assistant,你可以要求它设置闹钟、查询天气、播放音乐等,每个请求都是由单个AI代理独立处理的,它根据你的命令执行特定的任务。
单智能体的核心在于 LLM 与感知、行动的配合。LLM 通过理解用户的任务,推理出需要调用的工具或行动,并基于调用或行动结果给用户反馈。但是对于很多场景来说,单智能体能做的还是太有限了。以写稿为例,完成的操作流程中该场景至少需要4个智能体:
- Researcher: 根据需求,上网搜各种资料,并把内容扒下来、进行总结。
- Editor: 根据需求和 Researcher 提供的资料,给出稿件的方向和框架。
- Writer: 根据 Editor 的指示,完成稿件撰写。
- Reviewer: 审稿,提出修改意见,返回给 Writer 做改进。
上面这4个智能体,既是4个角色,也是写稿工作流中的4个步骤。显然,单个智能体无法胜任。而且,类似 Reviewer 这样的角色还能让 LLM 自我审核、防止“脑残”。
多角色、复杂流程,需要多个 Agent 协作才能胜任,因此需要构建多智能体系统。多智能体系统会为不同的 Agent 赋予 不同的角色定位, 通过 Agent 之间的 协作来完成复杂的任务。 而在完成任务的过程中,相比于单智能体来说,与用户的交互会更少一些。 多智能体场景主要关注智能体们如何有效地协调并协作解决问题,根据任务的协作方式来看可以分为合作型和对抗型:
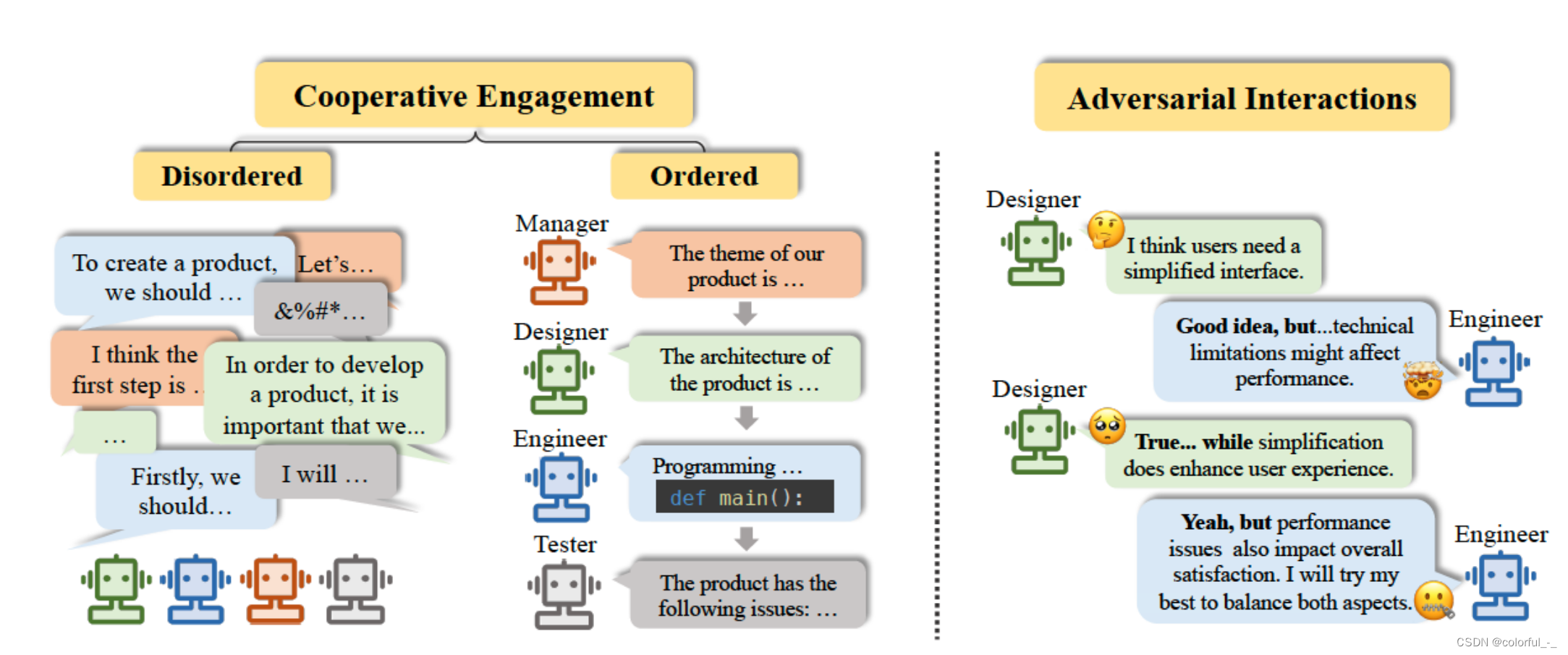
合作型互动:作为实际应用中最为广泛的类型,合作型的智能体系统可以有效提高任务效率、共同改进决策。具体来说,根据合作形式的不同,又可分为无序合作与有序合作。
当所有智能体自由地表达自己的观点、看法,以一种没有顺序的方式进行合作时,称为无序合作(动态对话拓扑)。
当所有智能体遵循一定的规则,例如以流水线的形式逐一发表自己的观点时,整个合作过程井然有序,称为有序合作(静态对话拓扑)。
对抗型互动:智能体们以一种针锋相对的对抗方式进行互动。通过竞争、谈判、辩论的形式,智能体抛弃原先可能错误的信念,对自己的行为或者推理过程进行有意义的反思,最终带来整个系统响应质量的提升。
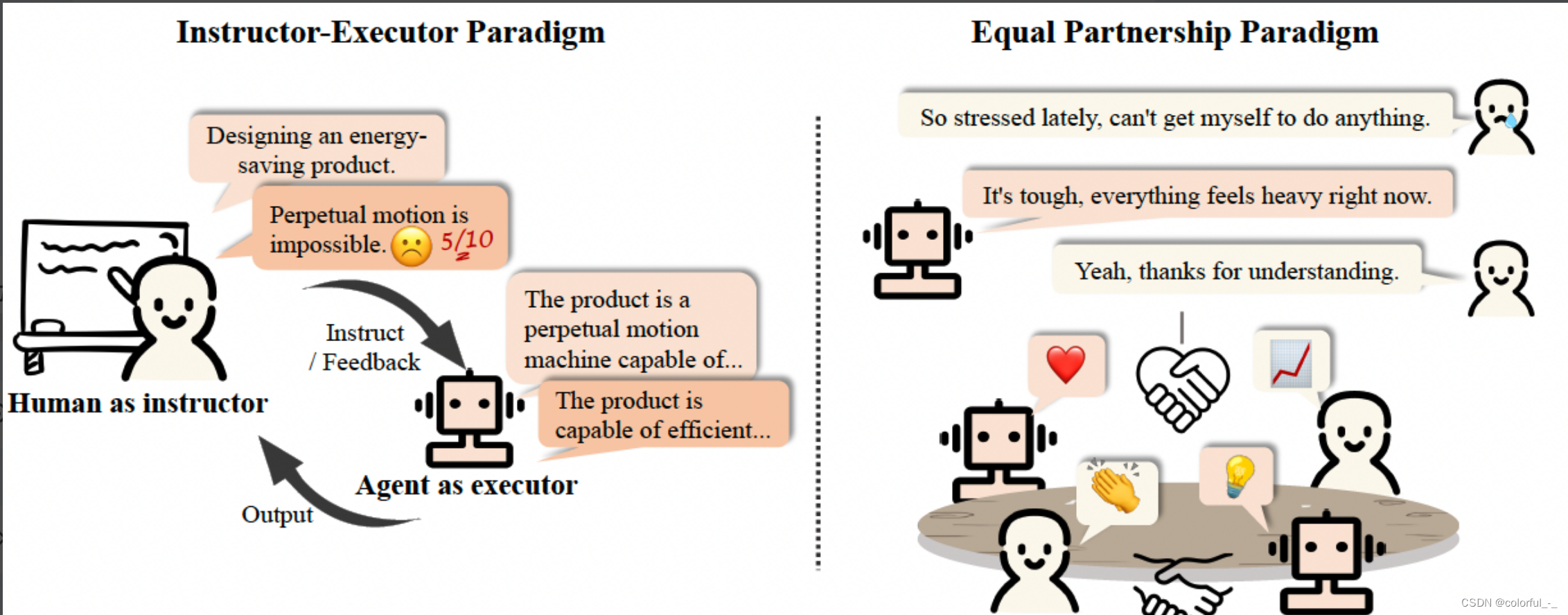
混合Agent:这种模式中,人工智能系统和人类共同参与决策过程,交互合作完成任务,强调的是人机协作的重要性和互补性。智慧医疗、智慧城市等专业领域可以使用混合智能体来完成复杂的专业工作。以智慧医疗为例,医生和AI系统共同进行病情诊断,AI系统可以快速分析病人的医疗记录、影像资料等,提供初步的诊断建议;而医生则可以基于AI的分析结果和自己的专业知识和经验,做出最终的诊断决定。
基本构成和技术原理
AI Agent的基本构成
复旦大学NLP团队在《A Survey on Large Language Model basedAutonomous Agents》一文中总结性地指出,如果基于大语言模型构建AI Agent,其总体框架由大脑、感知和行动三个关键部分组成:
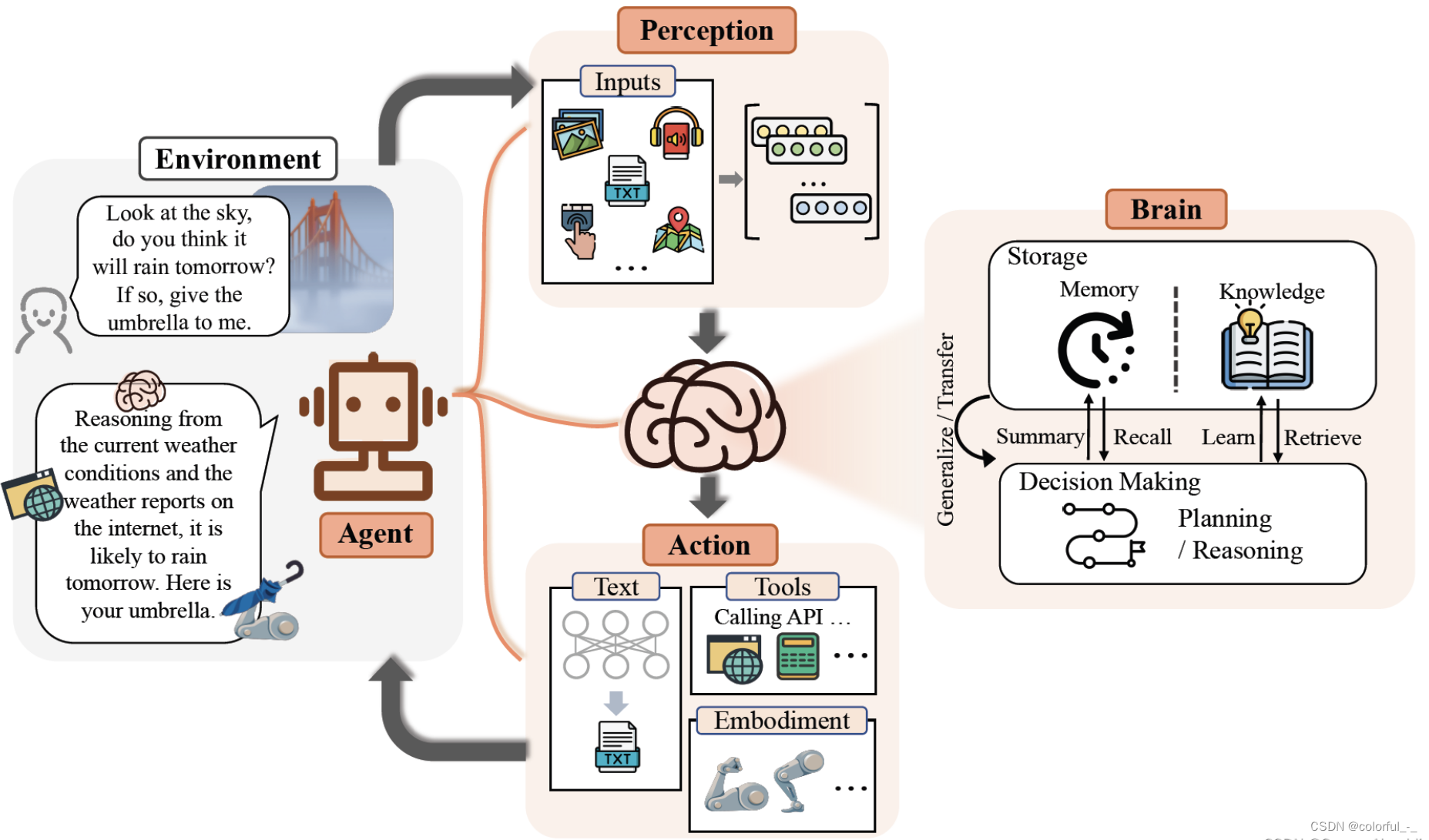
(此案例:当一个人问是否会下雨时,感知模块将指令转换为LLM可以理解的表示。然后,大脑模块开始根据当前天气和互联网上的天气预报进行推理。最后,动作模块做出响应,将伞交给人类。通过重复上述过程,智能体可以不断地获得反馈并与环境进行交互。)
- 大脑:主要由一个大型语言模型组成,该模型不仅存储知识和记忆,还承担信息处理和决策功能,能够呈现推理和规划过程,以很好地处理未知任务。
- 感知:感知模块的核心目的是将主体的感知空间从纯文本领域扩展到文本、听觉和视觉模式。
- 行动:在代理的构建中,行动模块接收大脑模块发送的动作序列,并执行与环境交互的动作。
在感知环境后,人类会对大脑中感知到的信息进行整合、分析和推理,并做出决策。随后,他们利用神经系统控制自己的身体,并进行适应性或创造性的行动,如交谈、躲避障碍或生火。当一个智能体拥有类似大脑的结构,以及知识、记忆、推理、规划、泛化能力和多模式感知能力时,它也有可能对周围环境做出各种类似人类的反应。在智能体的构建过程中,动作模块接收大脑模块发送的动作序列,并执行与环境交互的动作。
对细节感兴趣可进一步查阅原论文:https://arxiv.org/pdf/2309.07864.pdf
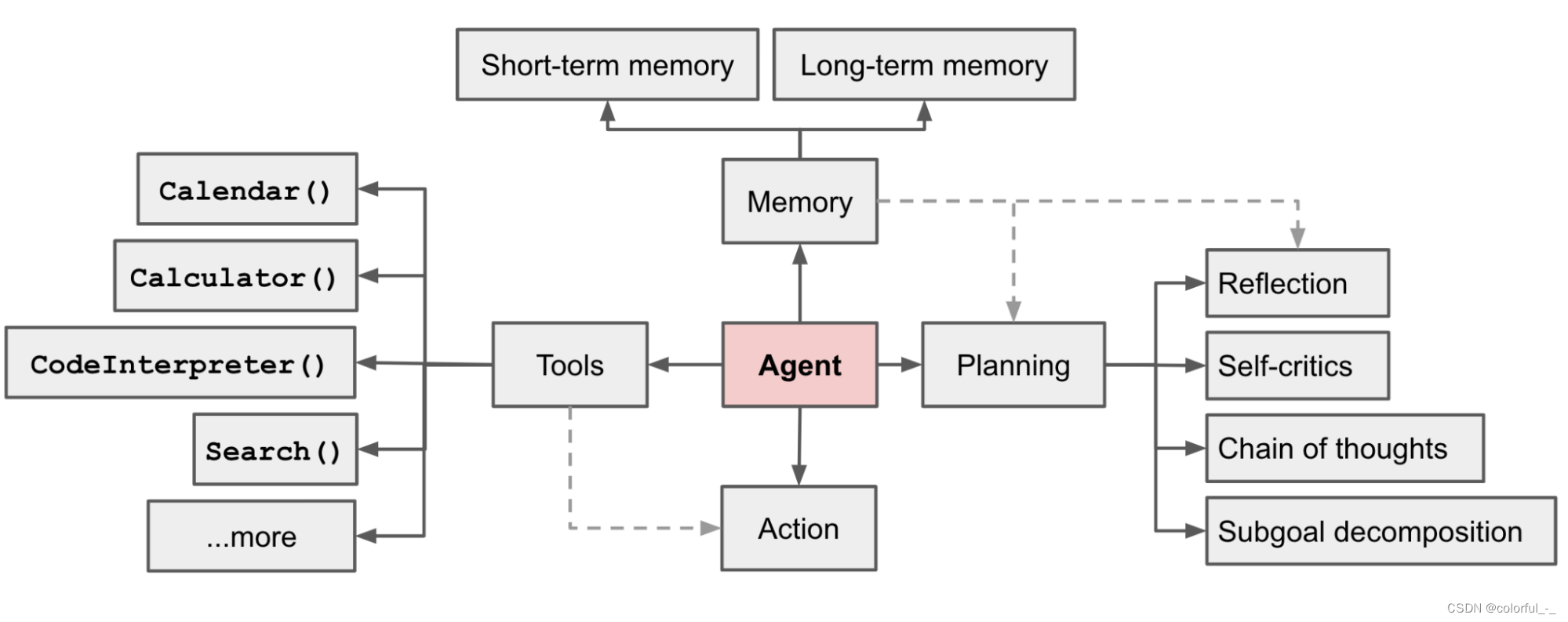
控制端(Brain)
作为控制中心的大脑(Brain)模块负责处理信息,以及记忆和知识的存储处理活动,如思考、决策和操作。
我们以以下五种能力来探讨大脑作为控制中心的基础:
自然语言交互:
-
多轮交互对话能力:基于LLM的AI Agent能够利用已有的信息不断提炼输出,进行多轮对话,有效地实现最终目标
-
高质量的文本生成:作为控制端核心的LLM能够生成流畅、多样、新颖、可控的文本,且可进行语法错误检测
-
潜在意图理解:除了直观表现出的内容,语言背后可能还传递了说话者的意图、偏好等信息。言外之意有助于代理更高效地沟通与合作,作为控制端核心的LLM凸显了基础模型理解人类意图的潜力,但当涉及到模糊的指令等其他方面,仍然是个挑战
知识:
-
Scale Law:当LLM有更多的参数、更多的训练语料时,可以学习到更多的知识
-
知识类别:这些知识包括语言知识、常识知识、专业领域知识
-
潜在问题:LLM其本身存在过时、错误和幻觉等问题,现有的一些研究通过知识编辑或调用外部知识库等方法,可以在一定程度上得到缓解。
记忆
-
储存长短期记忆:储存了代理过往的观察、思考和行动序列。通过特定的记忆机制,代理可以确保它们熟练地处理一系列连续的任务,同时有效地反思并应用先前的策略,使其借鉴过去的经验来适应陌生的环境
-
长短期记忆:
- 短期记忆:可以输入LLM上下文长度以内的记忆
- 长期记忆:这为代理提供了长时间保留和回忆(无限)信息的能力,通常是通过利用外部向量存储和快速检索、以及设定系统角色来实现的
-
两个困难点:历史上下文长度的限制 & 如何提取更相关的记忆
-
用于提升记忆能力的方法:
- 扩展基于Transformer架构的长度限制:针对 Transformers 固有的序列长度限制问题进行改进。现有手段包括文本截断、分割输入、强调文本的关键部分、修改注意力机制以降低复杂性
- 记忆总结:对记忆进行摘要总结,增强代理从记忆中提取关键细节的能力。现有手段包括使用提示、反思过程、分层过程
- 记忆压缩:通过采用合适的数据结来压缩记忆,可以提高智能代理的记忆检索效率
推理和规划
-
推理能力:对于解决复杂任务至关重要;包括演绎、归纳和溯因,以证据和逻辑为基础,是解决问题、决策和批判性分析的基石
-
LLM-based Agent的推理能力:包括思维链(CoT)、self-consistency、self-polish、self-refine以及selection-inference
-
规划能力:通过推理,Agent将复杂的任务分解为更易于管理的子任务,并为每个子任务设计合适的计划。此外,随着任务的进行,Agent可以使用自省来修改任务执行计划,确保其更好地与现实世界的情况保持一致。
-
规划的两个步骤:
-
计划制定(Plan Formulation):代理将复杂任务分解为更易于管理的子任务。例如:一次性分解再按顺序执行、逐步规划并执行、多路规划并选取最优路径等。在一些需要专业知识的场景中,代理可与特定领域的 Planner 模块集成,提升能力
-
计划反思(Plan Reflection):在制定计划后,可以进行反思并评估其优劣。这种反思一般来自三个方面:借助内部反馈机制;与人类互动获得反馈;从环境中获得反馈。
-
迁移和泛化能力
-
动态学习能力:在大量语料库上进行预训练的LLMs 具备强大的在知识、应用上的迁移与泛化能力。一个好的Agent不仅仅是静态的知识库,还应具备动态的学习能力
-
对未知任务的泛化(Unseen Task Generalization):随着模型规模与训练数据的增大,LLMs 在解决未知任务上涌现出了惊人的能力,从而提高了Agent对于未知任务的泛化迁移能力;值得注意的是prompt的选择是至关重要的,并且直接在prompt上进行训练可以提高模型在推广到未知任务时的鲁棒性
-
情景学习(In-context Learning):LLMs可以通过上下文学习来执行各种复杂的任务(例如,few-shot learning);这种能力还可以扩展到文本以外的多模态场景,为Agent在现实世界中的应用提供了更多可能性
持续学习(Continual Learning):LLMs在促进Agent持续学习方面的能咯,包括持续获取和更新技能;持续学习的主要挑战是灾难性遗忘,即当模型学习新任务时容易丢失过往任务中的知识。专有领域的Agent应当尽量避免丢失通用领域的知识。
感知端(Perception)
人类和动物都依靠眼睛和耳朵等感觉器官从周围环境中收集信息,这些感知输入被转换成神经信号并发送到大脑进行处理,使我们能够感知世界并与之互动。
同样,对于LLM-based Agent来说,接收多模态的感知、信息也是至关重要的。这种扩展的感知空间有助于智能体更好地理解其环境,提升通用性、信息利用度。
目前,多模态的信息输入主要包括:
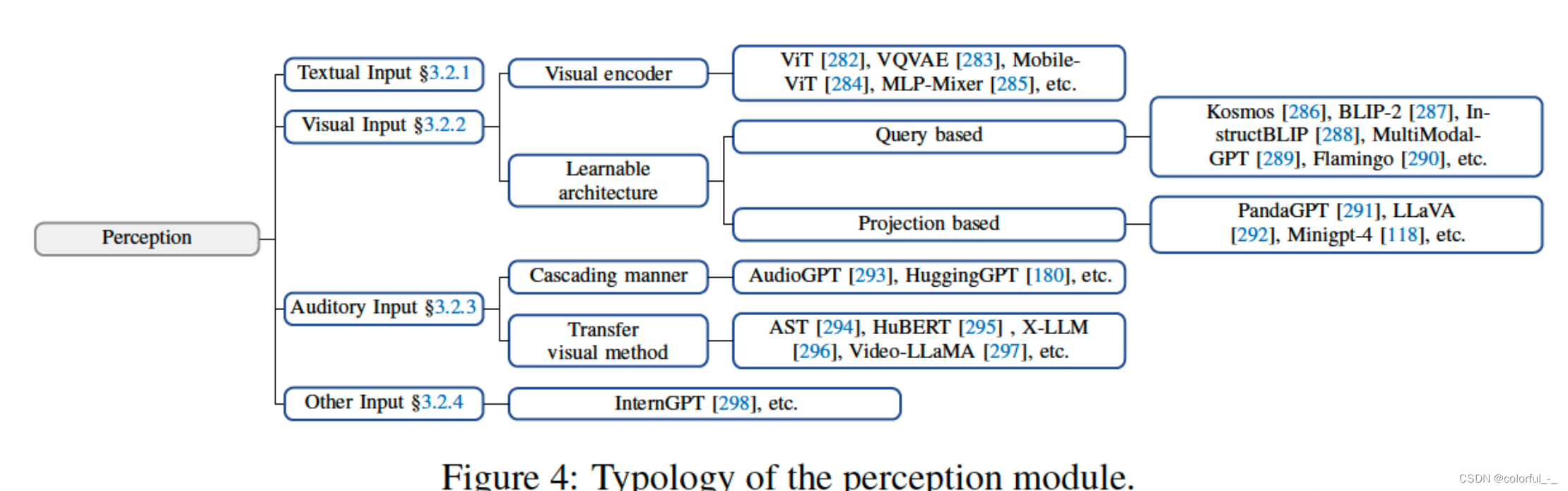
文本输入:LLM强大的文字处理、语言理解能力
视觉输入:LLMs 本身并不具备视觉的感知能力,只能理解离散的文本内容;而视觉输入通常包含有关世界的大量信息,包括对象的属性,空间关系,场景布局等等。
- 针对LLMs无法理解图像的问题,常见的解决方法有:
-
Image Captioning:根据视觉输入生成对应的文字描述,从而可以被 LLMs 直接理解,且 计算成本低;但是低带宽,且会忽略很多的信息
-
视觉基础模型 + LLMs:用transformer对视觉信息进行编码表示,通过对齐操作来让模型 理解不同模态的内容,可以端到端的方式进行训练;但是计算成本非常高
-
视频输入:对于视频输入,其是由一系列连续的图像帧组成。因此,智能体用于感知图像的方法可能适用于视频领域,只是增加了一个时间维度,agent还需要对不同帧之间的时间关系进行理解。
听觉输入:
- 一个非常直观的处理方法是,Agent可以使用LLMs作为控制中心,以级联方式调用现有的工具集或模型库来感知音频信息。例如,AudioGPT充分调用了FastSpeech(文本到语音)、GenerSpeech(风格转换)、Whisper(语音识别)等模型的功能。
- 另一种方法将感知方法从视觉领域迁移到音频领域,AST(音频频谱图转换器)采用类似于ViT的Transformer架构来处理音频频谱图图像。通过将音频频谱图分割成小块,实现对音频信息的有效编码
其他输入:引入现实世界的更多的输入,配备更丰富的感知模块。例如:触觉和嗅觉;感知周围环境的温度、湿度和亮度;眼球追踪、身体动作捕捉,甚至是脑机交互中的脑波信号
此外,还可以为代理引入对更广阔的整体环境的感知:采用激光雷达、GPS、惯性测量单元等成熟的感知模块。
行动端(Action)
在Agent的构建中,行动端接收大脑端发送的动作序列,并执行动作与环境进行交互。当一个Agent拥有类似大脑的结构,具有知识、记忆、推理、计划和泛化能力,以及多模态感知能力时,它也有望拥有多样化的行动范围。
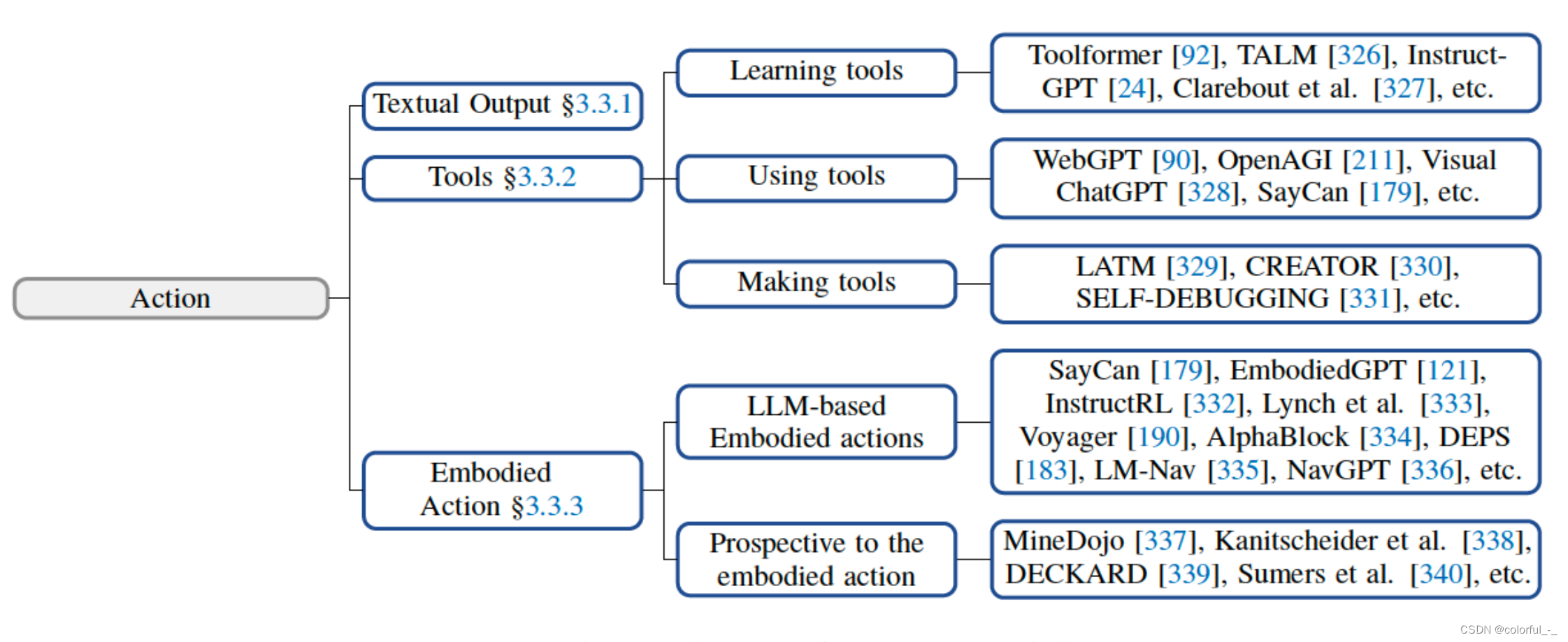
文本输出:LLM-based Agent的固有能力
工具使用:LLM-based Agent在某些方面存在局限性,使用工具可以增强代理的能力。专门的工具使LLM能够增强其在某些特定领域的专业知识,并以可插拔的形式更适合特定于领域的需求(借助工具完成任务的Agent表现出更强的可解释性和鲁棒性,使用这些工具的代理可以更好地处理轻微的输入修改,并且对对抗性攻击更有弹性;可以分解任务,作为集成工具的核心)
具身行动:在追求通用人工智能(AGI)的过程中,具身智能体被认为是一个关键的范式,其将模型智能与物理世界相结合。
E.g. 做饭机器人Mobile ALOHA (mobile-aloha.github.io)
4.4 角色(Agent Profile/Persona)
Agent通常通过扮演特定角色来执行任务,例如编码人员、教师或者是领域专家。角色模块旨在指示Agent角色的概要,这些概要通常作为系统性信息以影响LLM行为。
目前主要使用以下策略来生成Agent的角色信息:
人工定义:人工指定代理配置文件;例如,如果想设计具有不同性格的代理,可以用“你是一个外向的人”或“你是一个内向的人”来描述Agent。
E.g., MetaGPT、ChatDev和Self-collaboration预先定义了软件开发中的各种角色及其相应的职责,手动为每个代理分配不同的配置文件以促进协作。
LLM生成:代理配置文件基于LLM自动生成。通常,它首先指示概要文件生成规则,阐明目标人群中代理概要文件的组成和属性。然后,可以选择指定几个种子代理配置文件作为少量示例。最后,利用llm生成所有代理配置文件
数据集对齐:代理概要文件是从真实世界的数据集获得的。通常,可以首先将数据集中关于真人的信息组织成自然语言提示,然后利用它来分析代理。

















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









