






 本文介绍了一种新颖的深度补全方法,通过编码器-解码器和RGB-深度融合GAN结合W-AdaIN自适应融合模块,针对室内传感器深度图缺失问题进行有效处理。实验结果在NYU-DepthV2和SUNRGB-D数据集上显示出显著性能提升,特别是在复杂室内环境中。
本文介绍了一种新颖的深度补全方法,通过编码器-解码器和RGB-深度融合GAN结合W-AdaIN自适应融合模块,针对室内传感器深度图缺失问题进行有效处理。实验结果在NYU-DepthV2和SUNRGB-D数据集上显示出显著性能提升,特别是在复杂室内环境中。
摘要
室内传感器由于无法感知透明物体和搜寻距离范围有限等一些固有的限制,通常会出现深度图有缺失的现象,如下图的大面积黑色部分即为深度缺失部分。
不完整的深度图给许多下游视觉任务带来了负担,为了缓解这一问题,人们提出了越来越多的深度补全方法。不完整的深度图给许多下游视觉任务带来了负担,为了缓解这一问题,人们提出了越来越多的深度补全方法。**本文设计了一种新型的两分支端到端融合网络,以一对RGB 和不完整深度图像作为输入,预测出密集的完整深度图。***第一个分支采用编码器-解码器结构,借助从RGB 图像中提取的局部制导信息,从原始深度图中回归局部密集深度值。*在另一个分支中,*我们提出了一种RGB-深度融合GAN,将RGB图像转换为细粒度纹理深度图。***我们采用名为W-AdaIN的自适应融合模块跨两个分支传播特征,并附加置信度融合头来融合分支的两个输出以获得最终的深度图。**在NYU-Depth V2 和SUN RGB-D 上的大量实验表明,我们提出的方法明显提高了深度完井性能,特别是在更真实的室内环境设置中,借助伪深度图。
学习:
(1)常用的深度补全方法
常用的深度补全方法有以下几种:
-
基于图像的深度补全方法:这种方法通过分析图像中的纹理、边缘等信息,来推测缺失区域的深度值。常见的算法包括基于纹理合成的方法、基于边缘传播的方法等。
-
基于传感器的深度补全方法:这种方法利用多个传感器(如RGB相机、深度相机等)的数据进行融合,从而得到更准确的深度信息。常见的算法包括基于双目视觉的方法、基于结构光的方法等。
-
基于学习的深度补全方法:这种方法利用机器学习算法,通过训练模型来学习深度补全的规律和特征。常见的算法包括基于卷积神经网络(CNN)的方法、基于生成对抗网络(GAN)的方法等。
-
基于几何约束的深度补全方法:这种方法利用场景中物体之间的几何关系,通过几何约束来推测缺失区域的深度值。常见的算法包括基于三角剖分的方法、基于平面拟合的方法等。
(2)端到端的解释
端到端指的是输入是原始数据,输出是最后的结果,原来输入端不是直接的原始数据,而是在原始数据中提取的特征。
第一个分支采用编码器-解码器结构,借助从RGB 图像中提取的局部制导信息,从原始深度图中回归局部密集深度值。
第一个分支:端(原始深度图)到端(局部密集深度值)
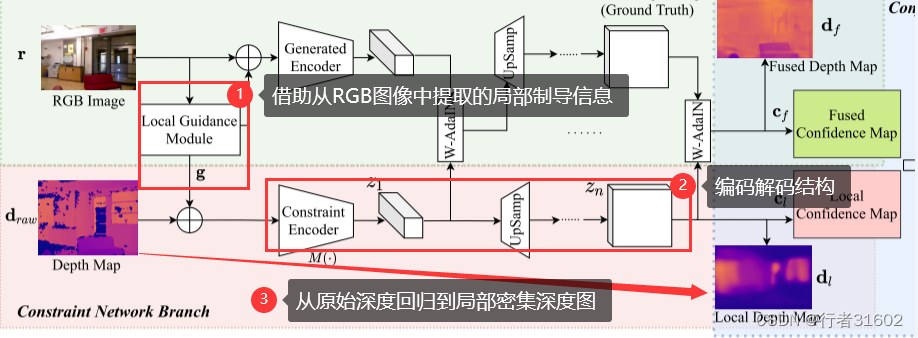
第二个分支,我们提出了一种RGB-深度融合GAN,将RGB图像转换为细粒度纹理深度图。
第二个分支:端(RGB图像)到端(细粒度纹理深度图)
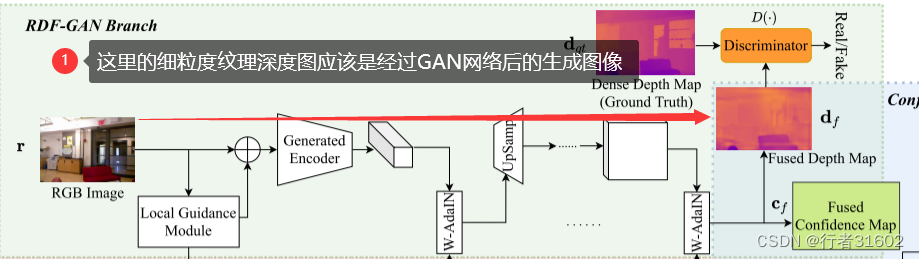
这里生成器是Generated Encoder(生成的编码器)和解码器
(3)我们采用名为W-AdaIN的自适应融合模块跨两个分支传播特征,并附加置信度融合头来融合分支的两个输出以获得最终的深度图。W-AdaIN的自适应融合模块和置信度融合头有什么作用?是什么?
W-AdaIN的自适应融合模块:
W-AdaIN(Weighted Adaptive Instance Normalization)是一种自适应融合模块,用于图像风格迁移任务中。它是在AdaIN(Adaptive Instance Normalization)的基础上进行改进的。
**AdaIN是一种将内容图像的特征统计信息与风格图像的特征统计信息进行匹配的方法,从而实现图像风格的转换。**然而,AdaIN没有考虑到不同风格之间的权重差异,导致在多个风格图像融合时可能会出现某些风格过于突出或者被忽略的问题。
W-AdaIN通过引入权重参数来解决这个问题。具体来说,W-AdaIN首先计算每个风格图像与内容图像之间的相似度权重,然后根据这些权重对不同风格的特征进行加权融合。这样可以更好地平衡不同风格之间的影响,使得融合后的图像更加自然和平衡。
总结一下,W-AdaIN是一种自适应融合模块,通过引入权重参数来平衡不同风格之间的影响,从而实现更好的图像风格迁移效果。
置信度融合头:
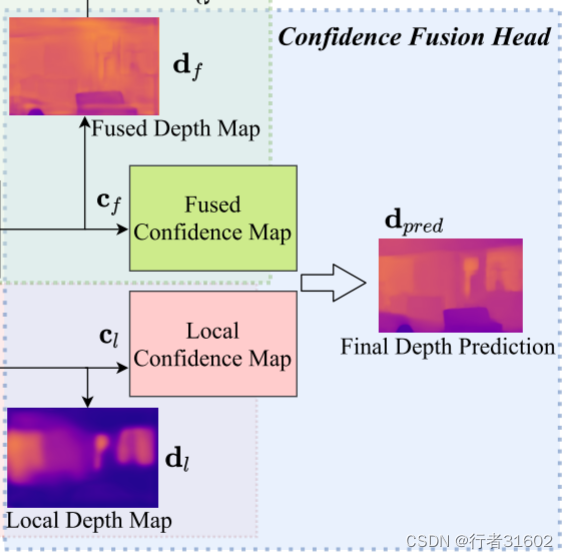
**解释一:**置信度融合头是一种用于目标检测任务的神经网络模块,**它主要用于将不同尺度的特征图融合起来,以提高目标检测的准确性和鲁棒性。**置信度融合头通常由两个主要组件组成:特征金字塔和置信度融合模块。
特征金字塔是一种多尺度特征提取方法,它通过在不同层级的特征图上进行卷积操作,得到具有不同感受野的特征图。这样可以捕捉到不同尺度的目标信息,从而提高目标检测的能力。
置信度融合模块用于将来自不同尺度的特征图进行融合,以生成最终的目标检测结果。常见的融合方式包括特征图级别的加权融合、特征通道级别的加权融合等。通过融合不同尺度的特征信息,可以提高目标检测算法对于不同尺度目标的检测能力,并且减少误检率。
总结来说,置信度融合头是一种用于目标检测任务的神经网络模块,通过特征金字塔和置信度融合模块的组合,可以提高目标检测算法的准确性和鲁棒性。
**解释二:**Confidence Fusion Head是一种用于多模态任务的神经网络模型结构。它主要用于将来自不同模态(例如图像、文本、语音等)的信息进行融合,并生成一个综合的置信度评估。
**Confidence Fusion Head的目标是将不同模态的信息融合在一起,以提高多模态任务的性能。**它通常作为一个额外的组件添加到现有的多模态模型中。
具体来说,Confidence Fusion Head通过学习每个模态的权重和置信度来实现信息融合。它可以根据每个模态的贡献程度自适应地调整权重,从而更好地利用每个模态的信息。同时,它还可以生成一个综合的置信度评估,用于指导后续任务的决策。
通过使用Confidence Fusion Head,多模态任务可以更好地利用不同模态之间的互补性,从而提高任务的准确性和鲁棒性。
(4)NYU-Depth V2 和SUN RGB-D
NYU-Depth V2是一个广泛使用的RGB-D数据集,用于室内场景的深度估计和语义分割任务。该数据集包含464个室内场景的视频序列,涵盖了多种不同的场景和物体类别。每个视频序列都包含RGB图像、深度图像和语义标签。NYU-Depth V2数据集的目标是提供一个用于深度估计和语义分割算法评估的标准基准。
SUN RGB-D是另一个常用的RGB-D数据集,用于室内场景的理解和分析任务。该数据集包含10,335个室内场景的RGB图像、深度图像和语义标签。每个场景都包含多个房间和各种不同的物体类别。SUN RGB-D数据集的目标是提供一个用于室内场景理解算法评估的资源,帮助研究人员开发更好的室内场景分析方法。

















 131
131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









