







Logistic回归模型
假定线下回归模型为:
z
=
β
0
+
β
1
x
1
+
β
2
x
2
+
.
.
.
+
β
p
x
p
z=\beta_0+\beta_1x_1+\beta_2x_2+...+\beta_px_p
z=β0+β1x1+β2x2+...+βpxp
则Logit变换为:
g
(
z
)
=
1
1
+
e
−
(
β
0
+
β
1
x
1
+
β
2
x
2
+
.
.
.
+
β
p
x
p
)
=
h
β
(
X
)
g(z) =\frac{1}{1+e^{-(\beta_0+\beta_1x_1+\beta_2x_2+...+\beta_px_p)}} =h_\beta(X)
g(z)=1+e−(β0+β1x1+β2x2+...+βpxp)1=hβ(X)
上式中的 h β ( X ) h_\beta(X) hβ(X)也被称为Logistic回归模型,它是将线性回归模型的预测值经过非线性的Logit函数转换为[0,1]之间的概率值。
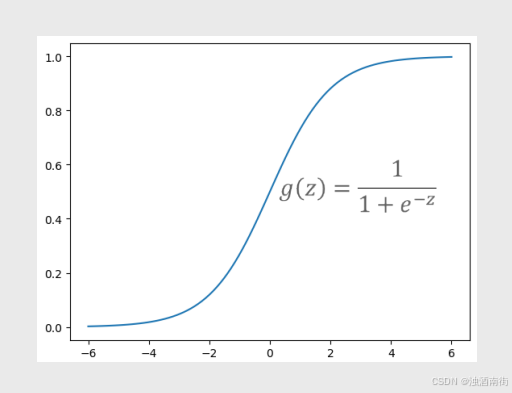
其中,
z
∈
(
−
∞
,
+
∞
)
z\in(-\infty,+\infty)
z∈(−∞,+∞)。当z趋于正无穷大时,
e
−
z
e^{-z}
e−z将趋于0,进而导致g(z)逼近于1;
相反,当z趋于负无穷大时,
e
−
z
e^{-z}
e−z将趋于正无穷大,最终导致g(z)逼近于0;
当z=0时,
e
−
z
e^{-z}
e−z =1,所以得到g(z)=0.5;
模型变换:
条件概率,y取值为1时的概率:
P
(
y
=
1
∣
X
;
β
)
=
h
β
(
X
)
=
p
P(y=1|X;\beta)=h_\beta(X) =p
P(y=1∣X;β)=hβ(X)=p
条件概率,y取值为0时的概率:
P
(
y
=
0
∣
X
;
β
)
=
1
−
h
β
(
X
)
=
1
−
p
P(y=0|X;\beta)=1-h_\beta(X)=1-p
P(y=0∣X;β)=1−hβ(X)=1−p
则两个概率的商为:
p
1
−
p
=
h
β
(
X
)
1
−
h
β
(
X
)
=
e
β
0
+
β
1
x
1
+
β
2
x
2
+
β
3
x
3
+
.
.
.
+
β
p
x
p
\frac{p}{1-p}=\frac{h_\beta(X)}{1-h_\beta(X)}=e^{\beta_0+\beta_1x_1+\beta_2x_2+\beta_3x_3+...+\beta_px_p}
1−pp=1−hβ(X)hβ(X)=eβ0+β1x1+β2x2+β3x3+...+βpxp
参数求解过程:

构造似然函数
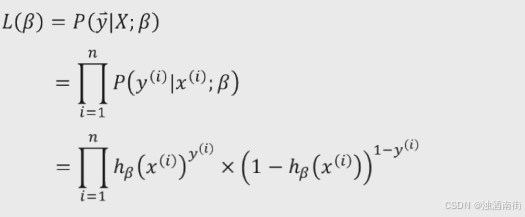
似然函数对数化
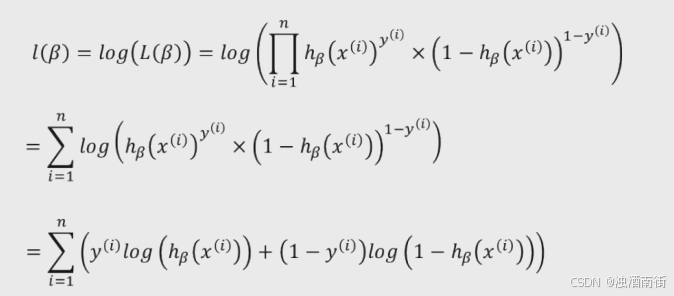
梯度下降:
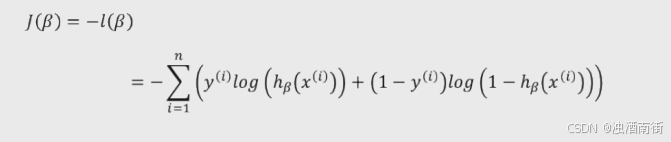
对每一个未知参数
β
j
\beta_j
βj做梯度下降:
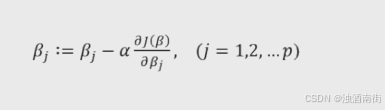
其中,
α
\alpha
α为学习率,也称为参数
β
j
\beta_j
βj变化的步长,通常步长可以取0.1,0.05,0.0,1等。如果设置的
α
\alpha
α过小,会导致
β
j
\beta_j
βj变化微小,需要经过多次迭代,收敛速度过慢;但如果设置的
α
\alpha
α过大,就很难得到理想的
β
j
\beta_j
βj值,进而导致目标函数可能是局部最小;
参数含义的解释:
假设影响是否患癌的因素有性别和肿瘤两个变量,通过建模可以得到对应的系数
β
1
\beta_1
β1和
β
2
\beta_2
β2,则Logistic回归模型可以按照事件发生比的形式改写为:
o
d
d
s
=
p
1
−
p
=
e
β
0
+
β
1
G
e
n
d
e
r
+
β
2
V
o
l
u
m
=
e
β
0
∗
e
β
1
G
e
n
d
e
r
∗
e
β
2
V
o
l
u
m
odds=\frac{p}{1-p} =e^{\beta_0+\beta_1Gender+\beta_2Volum} =e^{\beta_0}*e^{\beta_1Gender}*e^{\beta_2Volum}
odds=1−pp=eβ0+β1Gender+β2Volum=eβ0∗eβ1Gender∗eβ2Volum
分别以性别变量和肿瘤体积变量为例,解释系数
β
1
\beta_1
β1和
β
2
\beta_2
β2的含义。假设性别中男用1表示,女用0表示,则:
o
d
d
s
1
o
d
d
s
0
=
e
β
0
∗
e
β
1
∗
1
∗
e
β
2
V
o
l
u
m
e
β
0
∗
e
β
1
∗
0
∗
e
β
2
V
o
l
u
m
=
e
β
1
\frac{odds_1}{odds_0} =\frac{e^{\beta_0}*e^{\beta_1*1}*e^{\beta_2Volum}}{e^{\beta_0}*e^{\beta_1*0}*e^{\beta_2Volum}} =e^{\beta_1}
odds0odds1=eβ0∗eβ1∗0∗eβ2Volumeβ0∗eβ1∗1∗eβ2Volum=eβ1
所以,性别变量的发生比率为 e β 1 e^{\beta_1} eβ1,表示男性患癌的发生约为女性患癌发生的 e β 1 e^{\beta_1} eβ1倍。
对于连续的自变量而言,参数解释类似,假设肿瘤体积为 V o l u m 0 Volum_0 Volum0,当肿瘤体积增加1个单位时,体积为 V o l u m 0 + 1 Volum_0+1 Volum0+1,则:
o d d s v o l u m 0 + 1 o d d s v o l u m 0 = e β 0 ∗ e β 1 G e n d e r ∗ e β 2 ( v o l u m 0 + 1 ) e β 0 ∗ e β 1 G e n d e r ∗ e β 2 ( v o l u m 0 ) = e β 2 \frac{odds_{volum_0+1}}{odds_{volum_0}}=\frac{e^{\beta_0}*e^{\beta_1Gender}*e^{\beta_2(volum_0+1)}}{e^{\beta_0}*e^{\beta_1Gender}*e^{\beta_2(volum_0)}} =e^{\beta_2} oddsvolum0oddsvolum0+1=eβ0∗eβ1Gender∗eβ2(volum0)eβ0∗eβ1Gender∗eβ2(volum0+1)=eβ2
所以,在其他变量不变的情况下,肿瘤体积每增加一个单位,将会使患癌发生比变化 e β 2 e^{\beta_2} eβ2倍。
模型评估
混淆矩阵
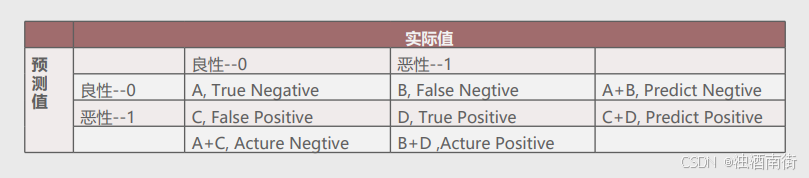
A:表示正确预测负例的样本个数,用TN表示。
B:表示预测为负例但实际为正例的个数,用FN表示。
C:表示预测为正例但实际为负例的个数,用FP表示。
D:表示正确预测正例的样本个数,用TP表示。
准确率:表示正确预测的正负例样本数与所有样本数量的比值,即(A+D)/(A+B+C+D)。
正例覆盖率:表示正确预测的正例数在实际正例数中的比例,即D/(B+D)。
负例覆盖率:表示正确预测的负例数在实际负例数中的比例,即A/(A+C)。
正例命中率:表示正确预测的正例数在预测正例数中的比例,即D/(C+D)。
ROC曲线

图中的红色线为参考线,即在不使用模型的情况下,Sensitivity 和 1-Specificity 之比恒等于 1。通常绘制ROC曲线,不仅仅是得到左侧的图形,更重要的是计算折线下的面积,即图中的阴影部分,这个面积称为AUC。在做模型评估时,希望AUC的值越大越好,通常情况下,
当AUC在0.8以上时,模型就基本可以接受了。
KS曲线
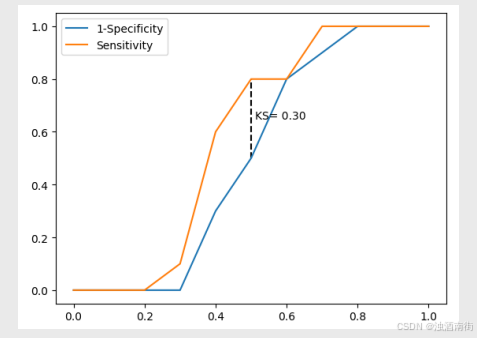
图中的两条折线分别代表各分位点下的正例覆盖率和1-负例覆盖率,通过两条曲线很难对模型的好坏做评估,一
般会选用最大的KS值作为衡量指标。KS的计算公式为:KS= Sensitivity-(1- Specificity)= Sensitivity+ Specificity-1。对于KS值而言,也是希望越大越好,通常情况下,当KS值大于0.4时,模型基本可以接受。

















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









