






爬取某视频网站评论并进行情感分析
一、参考代码
https://github.com/sachin-bisht/YouTube-Sentiment-Analysis
二、修改后的代码(本文讲述的代码,是根据视频的地址来爬取的)
https://github.com/zf617707527/-youtube-
三、再次升级后代码(可以根据关键字来爬取,只需要将key改为自己的google API即可)
https://github.com/zf617707527/youtube2.0.git
四、申请google api
https://blog.csdn.net/qq_27378621/article/details/80655208
五、爬取评论(可以选择爬取多少赞以上的评论,需要科学上网)
import lxml
import requests
import time
import sys
import progress_bar as PB
import json
YOUTUBE_IN_LINK = 'https://www.googleapis.com/youtube/v3/commentThreads?part=snippet&maxResults=100&order=relevance&pageToken={pageToken}&videoId={videoId}&key={key}'
YOUTUBE_LINK = 'https://www.googleapis.com/youtube/v3/commentThreads?part=snippet&maxResults=100&order=relevance&videoId={videoId}&key={key}'
key = 'key' #改为自己申请的google api
def commentExtract(videoId, count = -1):
print ("\nComments downloading")
#关闭http连接,增加重连次数
page_info = requests.get(YOUTUBE_LINK.format(videoId = videoId, key = key))
while page_info.status_code != 200:
if page_info.status_code != 429:
print ("Comments disabled")
sys.exit()
time.sleep(20)
page_info = requests.get(YOUTUBE_LINK.format(videoId = videoId, key = key))
page_info = page_info.json()
#test
# print(page_info)
comments = []
co = 0;
for i in range(len(page_info['items'])):
#对3000赞以上的评论进行保留,可以根据需求更改
if page_info['items'][i]['snippet']['topLevelComment']['snippet']['likeCount']>=3000:
comments.append(page_info['items'][i]['snippet']['topLevelComment']['snippet']['textOriginal'])
co += 1
if co == count:
PB.progress(co, count, cond = True)
return comments
PB.progress(co, count)
# INFINTE SCROLLING
while 'nextPageToken' in page_info:
temp = page_info
page_info = requests.get(YOUTUBE_IN_LINK.format(videoId = videoId, key = key, pageToken = page_info['nextPageToken']))
while page_info.status_code != 200:
time.sleep(20)
page_info = requests.get(YOUTUBE_IN_LINK.format(videoId = videoId, key = key, pageToken = temp['nextPageToken']))
page_info = page_info.json()
for i in range(len(page_info['items'])):
comments.append(page_info['items'][i]['snippet']['topLevelComment']['snippet']['textOriginal'])
co += 1
if co == count:
PB.progress(co, count, cond = True)
return comments
PB.progress(co, count)
PB.progress(count, count, cond = True)
print ()
return comments
六、对评论进行情感分析
对积极和消极评论进行分类,使用的是朴素贝叶斯分类器,并计算积极评论和消极评论的占比
import training_classifier as tcl
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import os.path
import pickle
from statistics import mode
from nltk.classify import ClassifierI
from nltk.metrics import BigramAssocMeasures
from nltk.collocations import BigramCollocationFinder as BCF
import itertools
from nltk.classify import NaiveBayesClassifier
def features(words):
temp = word_tokenize(words)
words = [temp[0]]
for i in range(1, len(temp)):
if(temp[i] != temp[i-1]):
words.append(temp[i])
scoreF = BigramAssocMeasures.chi_sq
#bigram count
n = 150
bigrams = BCF.from_words(words).nbest(scoreF, n)
return dict([word,True] for word in itertools.chain(words, bigrams))
class VoteClassifier(ClassifierI):
def __init__(self, *classifiers):
self.__classifiers = classifiers
def classify(self, comments):
votes = []
for c in self.__classifiers:
v = c.classify(comments)
votes.append(v)
con = mode(votes)
choice_votes = votes.count(mode(votes))
conf = (1.0 * choice_votes) / len(votes)
return con, conf
def sentiment(comments):
if not os.path.isfile('classifier.pickle'):
tcl.training()
fl = open('classifier.pickle','rb')
classifier = pickle.load(fl)
fl.close()
pos = 0
neg = 0
for words in comments:
# print(words)
comment = features(words)
sentiment_value, confidence = VoteClassifier(classifier).classify(comment)
if sentiment_value == 'positive':# and confidence * 100 >= 60:
pos += 1
else:
neg += 1
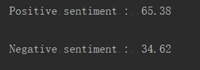
print ("\nPositive sentiment : ", (pos * 100.0 /len(comments)) )
print ("\nNegative sentiment : ", (neg * 100.0 /len(comments)) )
七、对评论进行分词,词频高的通过词云进行可视化
import string
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import nltk
# nltk.download('stopwords')
# nltk.download('punkt')
def fancySentiment(comments):
stopword = set(stopwords.words('english') + list(string.punctuation) + ['n\'t'])
filtered_comments = []
for i in comments:
words = word_tokenize(i)
temp_filter = ""
for w in words:
if w not in stopword:
temp_filter += str(w)
temp_filter += ' '
filtered_comments.append(temp_filter)
filtered_comments_str = ' '.join(filtered_comments)
sentiment = WordCloud(background_color = 'orange', max_words=100)
sentiment.generate(filtered_comments_str)
# with open('cloud.txt','w',encoding='utf-8') as f:
# f.write(str(sentiment.generate(filtered_comments_str)))
plt.figure()
plt.imshow(sentiment)
plt.axis("off")
plt.subplots_adjust(top=1, bottom=0, right=1, left=0, hspace=0, wspace=0)
plt.margins(0, 0)
plt.savefig("final.png",dpi=300)
plt.show()
八、调用爬虫
运行driver.py
import comment_downloader as CD
import fancySentiment as FS
# import sys
# sys.path.append('E:/爬取utube评论/YouTube-Sentiment-Analysis/CommentSentiment/')
import sentimentYouTube as SYT
import requests
import json
def main():
# EXAMPLE videoID = 'tCXGJQYZ9JA'
# videoId = input("Enter the videoID : ")
videoId_all = ['FWMIPukvdsQ','QHTnuI9IKBA','LTejJnrzGPM','_jUJrIWp2I4','OrXiXDUQia8','wUJ-57SAE5A','Yx4JnDez1sk','fhkE3e7lT_g','K92fPB3lKCc','xYmyNCzoCFI']
#将你想要爬取视频评论的id放入其中
# Fetch the number of comments
# if count = -1, fetch all comments
# count = int(input("Enter the no. of comment to extract : "))
count = 2000
#count为每个地址想要爬取评论的数目
comments = []
with open('verified_proxies.json', encoding='utf-8') as f:
# for line in f:
a = json.load(f)
#我在里面放了代理ip,防止ip被封,每爬一个网址换一个代理ip,运行ip.py可以获得代理ip
# final[a['type']] = a['host']+':'+a['port']
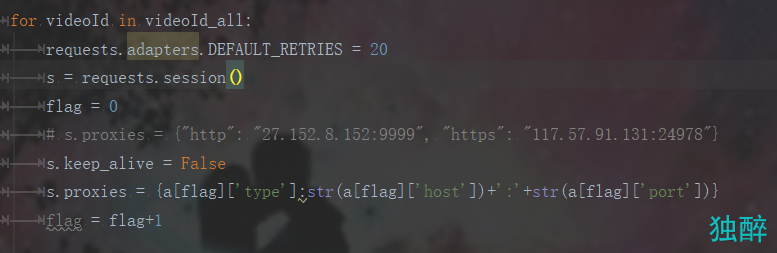
for videoId in videoId_all:
requests.adapters.DEFAULT_RETRIES = 20
s = requests.session()
flag = 0
# s.proxies = {"http": "27.152.8.152:9999", "https": "117.57.91.131:24978"}
s.keep_alive = False
s.proxies = {a[flag]['type']:str(a[flag]['host'])+':'+str(a[flag]['port'])}
flag = flag+1
comments = comments + CD.commentExtract(videoId, count)
# print(comments)
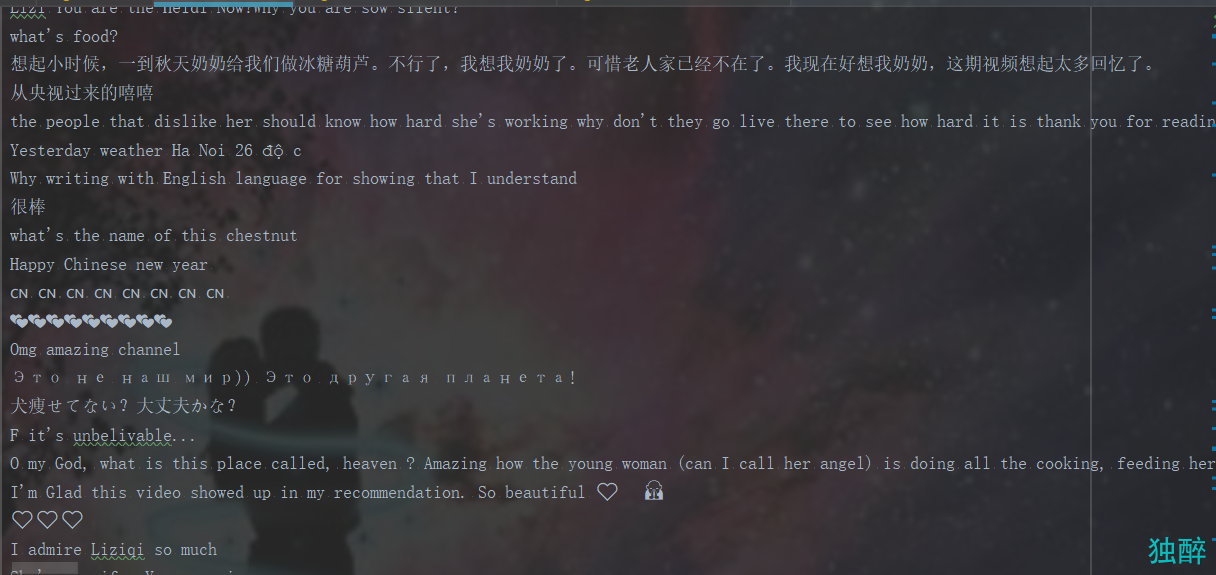
with open('data.txt','w',encoding='utf-8') as f:
for i in comments:
f.write(i+'\n')#将爬取的评论记录下来(这些评论是经过筛选的,是超过设置的赞的阈值的评论)
SYT.sentiment(comments)
FS.fancySentiment(comments)
if __name__ == '__main__':
main()
九、本项目的特点
1.可以爬取多个网址,并对爬取的所有评论进行整体分析,弥补了原程序只能一个网址一个网址爬的缺陷
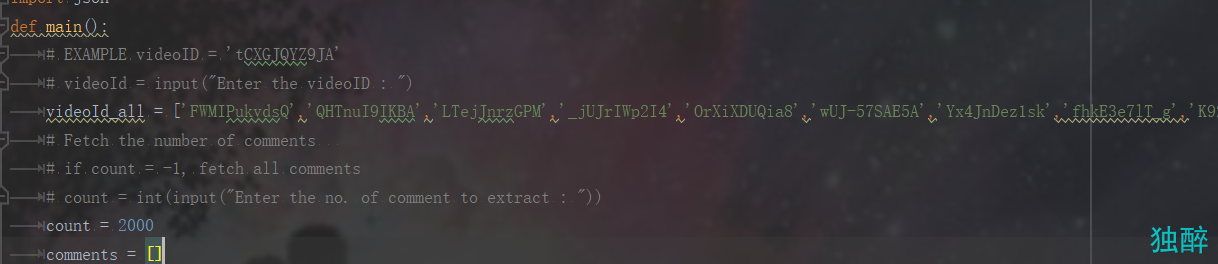
2.增加了对评论点赞数目的筛选功能,只需要设置阈值就可以对点赞数目进行筛选,选取更具有说服力的评论

3.增强了程序的鲁棒性,增设了ip代理池的功能,只需要运行ip.py文件就可以自动获取代理ip,在运行driver.py时每爬取一个网址就会更改一次代理ip,避免ip被封
4.增加了将评论保存的功能,结果保存在data.txt中,每个评论一行
5.对最终结果通过词云进行可视化

6.对评论的积极性和消极性进行评分

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









