






目录
朴素贝叶斯分类器是一种基于概率的分类方法,它利用贝叶斯定理来预测某个样本属于哪个类别。它的“朴素”之处在于假设特征之间相互独立,这意味着每个特征对于分类的贡献是相互独立的。
原理
介绍说明
朴素贝叶斯分类器基于以下的贝叶斯定理:
其中:
是给定特征
下类别 y 的概率。
是类别 y 的先验概率。
是在类别 y 下特征
由于对于所有的特征 𝑥,
在给定类别 y 的条件下是常数,因此朴素贝叶斯分类器可以简化为:
∝
⋅
⋅
⋅...⋅
例子
让我们通过一个简单的例子来说明贝叶斯分类的训练过程。假设我们有一个包含以下四个观察值的数据集:
| 观察值 | 特征1 | 特征2 | 类别 |
|---|---|---|---|
| 1 | 1 | 0 | 0 |
| 2 | 1 | 1 | 1 |
| 3 | 1 | 1 | 0 |
| 4 | 0 | 1 | 1 |
在这个例子中,我们有两个特征(特征1和特征2),每个观察值都有一个类别标签(0或1)。
步骤1:计算先验概率
首先,我们需要计算两个类别的先验概率。类别0和类别1的先验概率分别为:

步骤2:计算条件概率
接下来,我们需要计算每个特征在每个类别下的条件概率。
对于特征1,类别0和类别1下的条件概率分别为:

对于特征2,类别0和类别1下的条件概率分别为:
步骤3:计算每类预测概率
假设测试数据为(0,1)
则对于类别0:
对于类别1:
所以最终的预测结果为1
实现方法
在实现朴素贝叶斯分类器时,需要进行以下步骤:
- 数据预处理:包括数据清洗、特征提取等。
训练数据为:
其中特征1表示天气,用数字1、2、3表示晴天、阴天和下雨。特征2表示场地,用字母'S'、'M'、'L'表示小型、中型和大型场地。
标签为:
标签对应的天气和场地条件下进行的运动项目,用-1和1表示两种不同的运动项目。
- 计算类别的先验概率
。
def fit(self, X, y): self.classes = np.unique(y) self.class_prior = np.zeros(len(self.classes)) self.class_conditional_prob = [] # 计算类别先验概率 for i, c in enumerate(self.classes): self.class_prior[i] = np.sum(y == c) / len(y) # 计算每个特征在每个类别下的条件概率 class_data = X[y == c] class_conditional_prob = [] for col in range(X.shape[1]): feature_values = np.unique(X[:, col]) feature_prob = {} for v in feature_values: feature_prob[v] = np.sum(class_data[:, col] == v) / len(class_data) class_conditional_prob.append(feature_prob) self.class_conditional_prob.append(class_conditional_prob)运行结果:
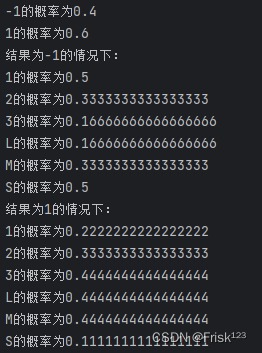
- 根据贝叶斯定理计算后验概率,并预测样本的类别。
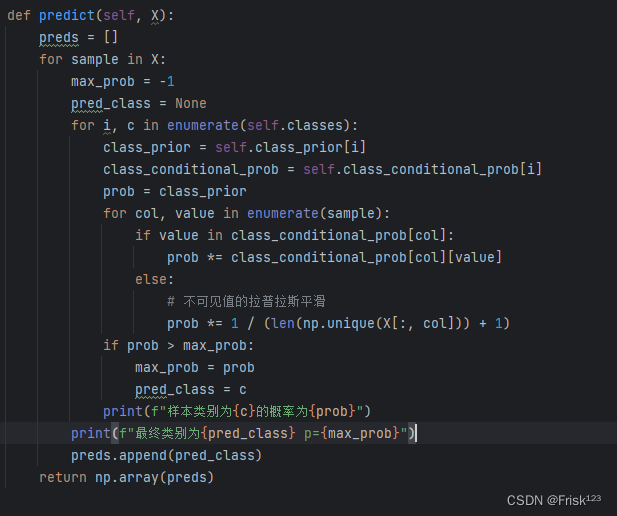
测试数据:
运行结果:
通过比较每类的概率,我们可以选取概率最大的类别作为最终的预测值。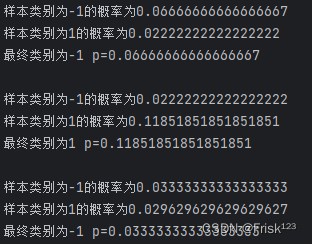
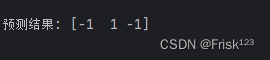
完整代码:
import numpy as np class NaiveBayesClassifier: def __init__(self): self.classes = None self.class_prior = None self.class_conditional_prob = None def fit(self, X, y): self.classes = np.unique(y) self.class_prior = np.zeros(len(self.classes)) self.class_conditional_prob = [] # 计算类别先验概率 for i, c in enumerate(self.classes): self.class_prior[i] = np.sum(y == c) / len(y) # 计算每个特征在每个类别下的条件概率 class_data = X[y == c] class_conditional_prob = [] for col in range(X.shape[1]): feature_values = np.unique(X[:, col]) feature_prob = {} for v in feature_values: feature_prob[v] = np.sum(class_data[:, col] == v) / len(class_data) class_conditional_prob.append(feature_prob) self.class_conditional_prob.append(class_conditional_prob) def predict(self, X): preds = [] for sample in X: max_prob = -1 pred_class = None for i, c in enumerate(self.classes): class_prior = self.class_prior[i] class_conditional_prob = self.class_conditional_prob[i] prob = class_prior for col, value in enumerate(sample): if value in class_conditional_prob[col]: prob *= class_conditional_prob[col][value] else: # 不可见值的拉普拉斯平滑 prob *= 1 / (len(np.unique(X[:, col])) + 1) if prob > max_prob: max_prob = prob pred_class = c print(f"样本类别为{c}的概率为{prob}") print(f"最终类别为{pred_class} p={max_prob}") print() preds.append(pred_class) return np.array(preds) # 示例用法 if __name__ == "__main__": # 创建一些示例数据 X_train = np.array( [[1, 'S'], [1, 'M'], [1, 'M'], [1, 'S'], [1, 'S'], [2, 'S'], [2, 'M'], [2, 'M'], [2, 'L'], [2, 'L'], [3, 'L'], [3, 'M'], [3, 'M'], [3, 'L'], [3, 'L']] ) y_train = np.array([-1, -1, 1, 1, -1, -1, -1, 1, 1, 1, 1, 1, 1, 1, -1]) X_test = np.array([[2, 'S'], [3, 'M'], [3, 'S']]) # 创建并训练分类器 classifier = NaiveBayesClassifier() classifier.fit(X_train, y_train) for idx, i in enumerate(classifier.class_prior): print(f"{classifier.classes[idx]}的概率为{i}") for idx, i in enumerate(classifier.class_conditional_prob): print(f"结果为{classifier.classes[idx]}的情况下:") for j in i: for k in j: print(f'{k}的概率为{j[k]}') # 进行预测 y_pred = classifier.predict(X_test) print("预测结果:", y_pred)















 2592
2592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









