






目录
AUC-ROC(Area Under the Curve - Receiver Operating Characteristic)
介绍
分类模型评估指标及ROC曲线和PR曲线在机器学习和数据挖掘领域具有重要地位,它们有助于我们全面评估分类模型的性能。
分类模型评估指标主要包括错误率、准确率、查准率、查全率、混淆矩阵、F1值等。错误率是指分类错误的样本数占总样本数的比例,而准确率则是分类正确的样本数占样本总数的比例。查准率(Precision)又称精确率,是预测为正例的样本中真正为正例的比率;查全率(Recall)又称召回率,是预测为正例的真实正例占所有真实正例的比例。
除了上述基本指标外,ROC曲线和PR曲线也是评估分类模型性能的重要工具。ROC曲线(Receiver Operating Characteristic curve)又称受试者工作特征曲线,是通过改变二分类器的判定阈值,绘制出不同阈值下真正例率(TPR)与假正例率(FPR)的关系曲线。TPR就是召回率,FPR是将负例错误地预测为正例占所有预测为负例的占比。ROC曲线能够综合考虑分类器在不同阈值下的性能,具有不受具体类别分布影响的优点,因此在类别不平衡的情况下,ROC曲线仍然能够提供较为准确的评估。
PR曲线(Precision-Recall curve)则是指在广告投放过程中,随着广告投入的增加,转化数量随时间变化的曲线。它反映了广告投放的效果,有助于广告主了解广告投入与转化之间的关系,进而优化广告投放策略。PR曲线的两个指标都聚焦于正例,因此在主要关心正例的预测准确性的情况下,PR曲线可能更为适用。
总的来说,分类模型评估指标、ROC曲线和PR曲线各有其特点和适用场景,我们可以根据具体需求选择合适的评估方法。在实际应用中,通常需要综合考虑多个评估指标和曲线,以便更全面地了解分类模型的性能。
一些常见的分类模型评估指标
-
准确率(Accuracy)
- 定义:分类正确的样本数占总样本数的比例。
- 公式:
- 适用范围:当各类别样本数量相对平衡时较为有效。
-
精确率(Precision)
- 定义:预测为正例的样本中真正为正例的比例。
- 公式:
- 适用范围:当关注预测为正例的样本中有多少是真正正例时,例如在垃圾邮件检测中。
-
召回率(Recall)或真正例率(TPR)
- 定义:预测为正例的真实正例占所有真实正例的比例。
- 公式:
- 适用范围:当关注找到所有真正正例的能力时,例如在疾病检测中。
-
F1值(F1 Score)
- 定义:精确率和召回率的调和平均值。
- 公式:
- 适用范围:当需要综合考虑精确率和召回率时。
-
AUC-ROC(Area Under the Curve - Receiver Operating Characteristic)
- 定义:ROC曲线下的面积,ROC曲线是真正例率与假正例率的关系曲线。
- 适用范围:当关注模型在不同分类阈值下的性能时,尤其适用于类别不平衡的情况。
-
混淆矩阵(Confusion Matrix)
- 定义:通过统计分类模型预测类别与实际类别之间的各类情况,展示在矩阵中。
- 内容:包括真正例(TP)、假正例(FP)、真反例(TN)和假反例(FN)。
- 适用范围:提供分类模型性能的详细分析。
真实正例 真实负例 预测正例 TP FP 预测负例 FN TN
ROC和PR曲线分析
ROC曲线分析
-
曲线形状:理想的ROC曲线会尽可能接近左上角,这意味着分类器在不同阈值下都能保持较高的真正例率(TPR)和较低的假正例率(FPR)。如果曲线接近对角线,说明分类器的性能接近随机猜测。
-
AUC值:AUC值(Area Under the Curve)表示ROC曲线下的面积,其值范围在0到1之间。AUC值越接近1,说明分类器的性能越好。一个完美的分类器会有AUC值等于1,而随机分类器的AUC值约为0.5。
PR曲线分析
-
曲线形状:理想的PR曲线会在高召回率下保持较高的精确率。如果曲线在召回率增加时迅速下降,说明分类器在识别更多真正例的同时也引入了大量的假正例。
-
平均精确率:平均精确率(Average Precision)是对PR曲线的一个量化评估,它考虑了不同召回率水平下的精确率。平均精确率越高,说明分类器在不同召回率下的性能越好。
结合分析
-
数据集特性:不同的数据集和分类任务可能对ROC曲线和PR曲线的形状有不同的影响。例如,在类别不平衡的情况下,PR曲线可能更能反映分类器的性能,因为它更关注正例的预测情况。
-
模型比较:如果你有多个分类器的结果,可以通过比较它们的ROC曲线、AUC值和PR曲线、平均精确率来评估哪个模型性能更好。通常,这些指标越高,模型性能越好。
-
阈值选择:ROC曲线和PR曲线还可以帮助你选择合适的分类阈值。根据具体需求(例如,更看重精确率还是召回率),你可以选择曲线上的一个点作为操作点,并确定相应的分类阈值。
实现部分
ROC曲线分析使用逻辑回归的分类器
代码实现
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import roc_curve, auc
from itertools import cycle
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 加载数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
y = (y == 2).astype(int) # 将问题转化为二分类问题,这里我们选择类别2作为正例
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1000)
# 设置k值列表
k_values = [1, 3, 5, 7, 9]
colors = cycle(['aqua', 'darkorange', 'cornflowerblue', 'gold', 'red'])
# 绘制不同k值的ROC曲线
plt.figure(figsize=(10, 8))
for k, col in zip(k_values, colors):
# 初始化k-NN分类器
knn = KNeighborsClassifier(n_neighbors=k)
# 训练模型
knn.fit(X_train, y_train)
# 预测概率
y_score = knn.predict_proba(X_test)[:, 1]
# 计算ROC曲线的数据点
fpr, tpr, thresholds = roc_curve(y_test, y_score)
# 计算AUC值
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.plot(fpr, tpr, color=col, lw=2, alpha=0.5, label='k=%d (AUC = %0.2f)' % (k, roc_auc))
# 绘制对角线
plt.plot([0, 1], [0, 1], linestyle='--', lw=2, color='r', alpha=.8)
# 设置图例和坐标轴标签
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('假正例率')
plt.ylabel('真正例率e')
plt.title('不同K值下的ROC曲线')
plt.legend(loc="lower right")
# 显示图形
plt.show()运行结果
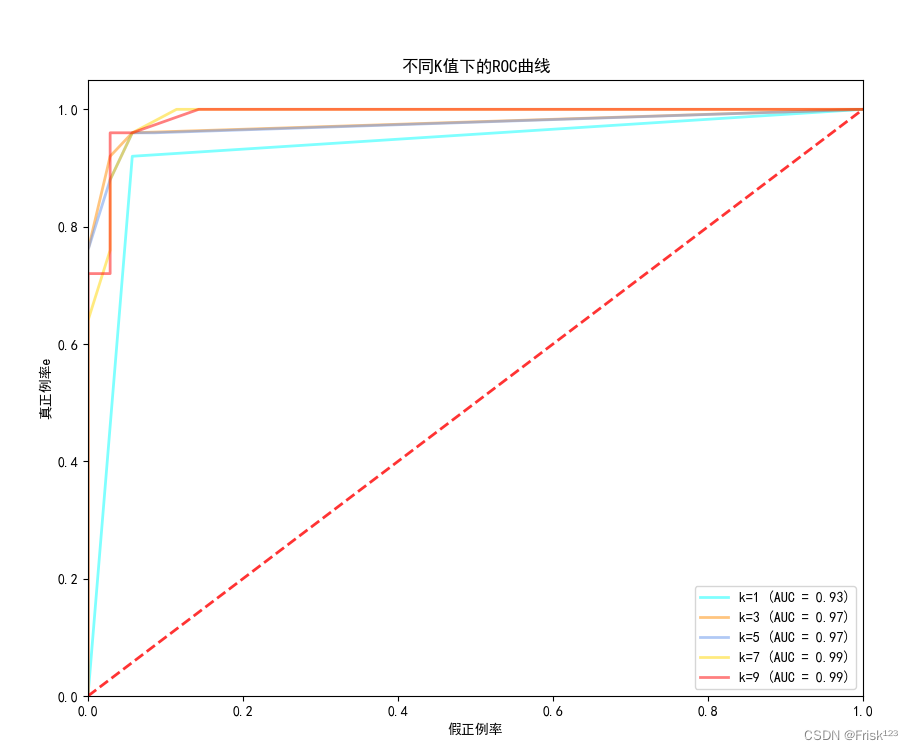
分析
从ROC曲线结果图来看,K值在取1到9时,AUC值呈现上升趋势,且更靠近左上角的理想情况。
可能的原因:
较小的K值使得分类器对训练数据的局部特征非常敏感,容易受到噪声和异常值的影响。
K在7和9时,够平衡分类器的敏感性和稳定性。在这种情况下,ROC曲线可能表现出相对平滑的形状,并且更接近左上角的理想情况。
PR曲线分析使用逻辑回归的分类器
代码实现
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import precision_recall_curve, auc
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 加载数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
y = (y == 2).astype(int) # 将问题转化为二分类问题,这里我们选择类别2作为正例
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1000)
# 设置k值列表
k_values = [1, 3, 5, 7, 9]
colors = ['aqua', 'darkorange', 'cornflowerblue', 'gold', 'red']
# 绘制不同k值的PR曲线
plt.figure(figsize=(10, 8))
for k, col in zip(k_values, colors):
# 初始化k-NN分类器
knn = KNeighborsClassifier(n_neighbors=k)
# 训练模型
knn.fit(X_train, y_train)
# 预测概率
y_score = knn.predict_proba(X_test)[:, 1]
# 计算PR曲线的数据点
precision, recall, _ = precision_recall_curve(y_test, y_score)
# 计算PR曲线的AUC值
pr_auc = auc(recall, precision)
# 绘制PR曲线
plt.plot(recall, precision, color=col, lw=2, alpha=0.5,
label=f'k={k}' + '(AUC = {:.2f})'.format(pr_auc))
# 绘制对角线
plt.plot([0, 1], [0, 1], linestyle='--', lw=2, color='gray', alpha=.8)
# 设置图例和坐标轴标签
plt.xlim([0.0, 1.05])
plt.ylim([0.0, 1.05])
plt.xlabel('召回率')
plt.ylabel('精度')
plt.title('不同K值下的PR曲线')
plt.legend(loc="lower left")
# 显示图形
plt.show()运行结果
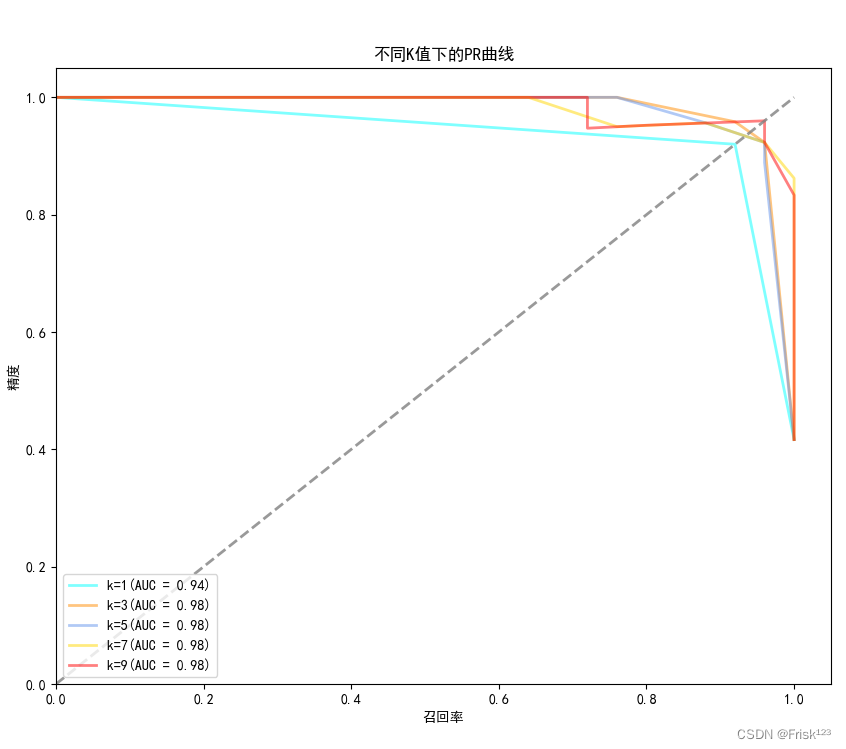
分析
从ROC曲线结果图来看,K值在取1到9时,AUC值呈现上升趋势,且更靠近右上角的理想情况。
可能的原因:
较小的K值使得分类器对训练数据的局部特征非常敏感,容易受到噪声和异常值的影响。
K在7和9时,够平衡分类器的敏感性和稳定性。在这种情况下,PR曲线可能表现出相对平滑的形状,并且更接近右上角的理想情况。这意味着模型在保持高召回率的同时,也能维持高精度















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









