






目录
介绍
在机器学习领域,逻辑回归是一种简单而强大的分类算法。尽管其名字带有“回归”,但逻辑回归常用于解决二分类问题。
逻辑回归
逻辑回归是一种广泛应用于统计学和机器学习领域的模型,用于解决分类问题。其基本思想是通过线性函数和一个逻辑函数(也称为sigmoid函数)的组合,来对数据进行分类。
原理
逻辑回归的数学原理非常简单直观。假设我们有一个二分类问题,目标是预测某个样本属于哪一类。我们首先使用线性函数 来表示输入特征 x对应的线性组合,其中 w是权重向量,b是偏置。然后,我们使用Sigmoid函数将线性函数的输出转换为0到1之间的概率值,表示样本属于正类的概率。
Sigmoid函数:
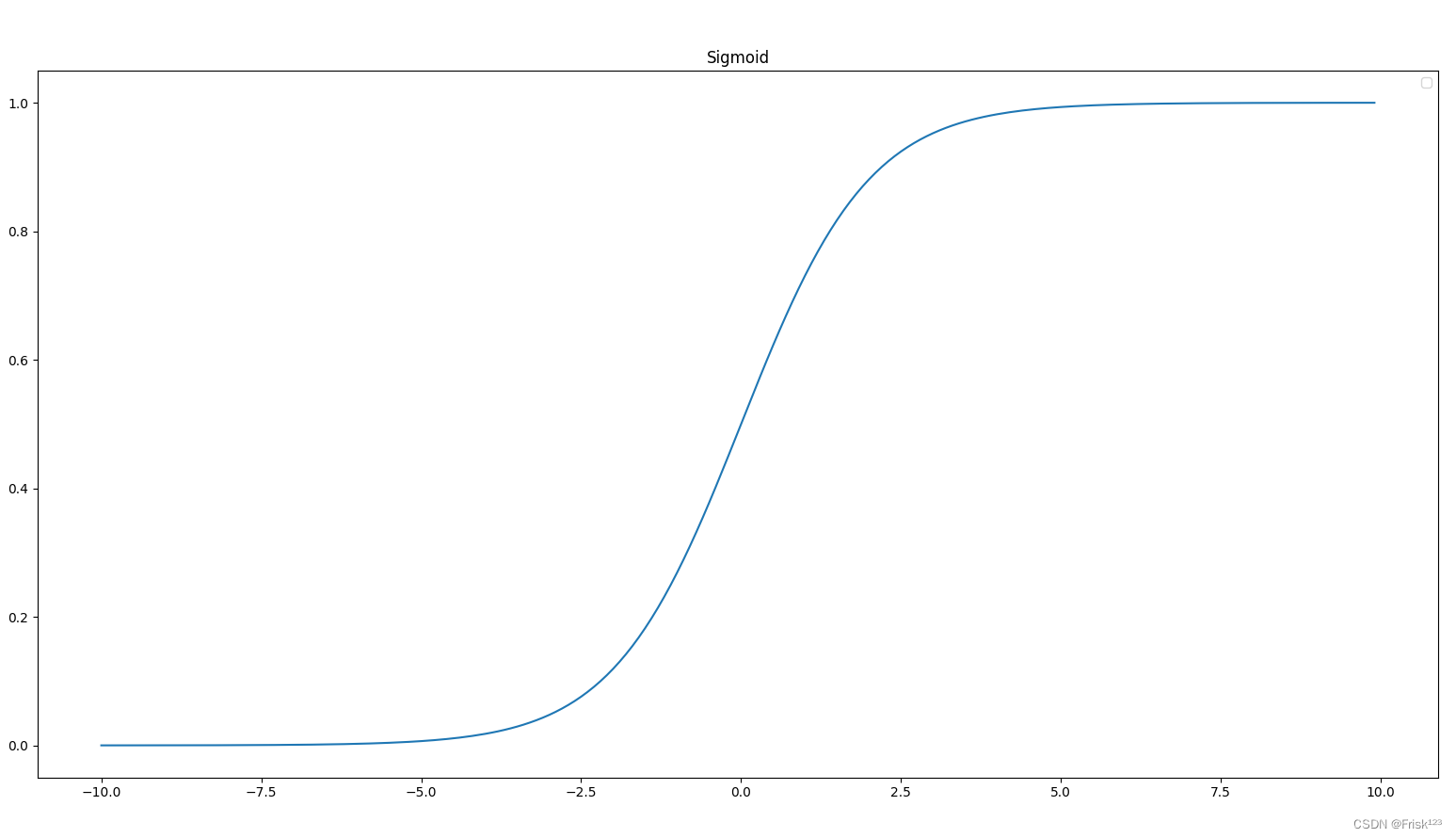
很明显,我们只需要符合要求的w和b,就能得到满足要求的逻辑回归分类器了。那么我们接下的问题就是如何求解w和b了。
为了解决这个问题,我们可以引入一个函数来衡量模型预测值与真实标签之间的差距,评估模型的效果好不好。这个函数称之为目标函数(损失函数),作用是评估模型的好坏同时也能引导模型往正确的方向学习。要训练出一个好的模型,一个优秀的目标函数是必备的。
损失函数定义为:
L即为平方损失函数,L越大说明模型预测的结果与真实标签差距越大,所以问题就转化为最小化L的值。对于这个问题,我们可以使用梯度下降的办法来最小化损失。
我们先初始化我们的w和b,w全部设置为1,b设置为0。之后我们对目标函数求导,用目标函数求导得到的梯度去更新我们的w和b。
对w求导:
对b求导:
求导得到梯度后,我们可以用梯度更新我们的w和b,从而使L最小化。
这里的lr为学习率。在梯度下降等优化算法中,模型的参数通过沿着梯度的反方向进行更新,以最小化损失函数。学习率控制着每次参数更新的步长,即控制了参数沿着梯度方向移动的幅度。
经过几轮的梯度更新操作后,模型输出的结果会越来越符合我们的预期。当模型几乎满足我的需求时,我们就可以停止梯度更新操作了,得到我们最终的模型。
优缺点
逻辑回归具有许多优点,包括模型简单、计算效率高、易于解释等。但是,它也有一些缺点,例如对于非线性关系的建模能力较弱。
实现
代码
逻辑回归部分
class LogisticRegression:
def __init__(self, lr=0.05, num_step=1000):
'''
逻辑回归分类器
:param learning_rate: 学习率
:param num_step: 训练步数
'''
self.lr = lr
self.num_step = num_step
self.weights = None
self.bias = None
def sigmoid(self, z):
return 1 / (1 + np.exp(-z))
def fit(self, X, y):
num_samples, num_features = X.shape
# 初始化权重和偏置 w全部置为1 b置为0
self.weights = np.ones(num_features)
self.bias = 0
# 梯度下降优化
for _ in range(self.num_step):
#得到线性模型预测值,结果用sigmod函数映射到(0, 1)上作为预测的概率
linear_model = np.dot(X, self.weights) + self.bias
y_predicted = self.sigmoid(linear_model)
# 计算梯度
dw = (1 / num_samples) * np.dot(X.T, (y_predicted - y))
db = (1 / num_samples) * np.sum(y_predicted - y)
# 更新权重和偏置
self.weights -= self.lr * dw
self.bias -= self.lr * db
def predict(self, X):
linear_model = np.dot(X, self.weights) + self.bias
y_predicted = self.sigmoid(linear_model)
#预测概率大于0.5,则预测结果为1
pred = [1 if i > 0.5 else 0 for i in y_predicted]
return pred数据集生成部分代码
数据集是样本特征数量为2,随机均匀分布,将分类设为1。
def generate_data(num_samples=100):
# 生成随机特征
X = np.random.rand(num_samples, 2) * 10
# 根据特定规则生成标签,x1*10+x2*5>100为类别1
y = np.zeros(num_samples)
x1, x2 = 0, 0
for i in range(num_samples):
x1 += X[i, 0]
x2 += X[i, 1]
x1 /= num_samples
x2 /= num_samples
for i in range(num_samples):
if X[i, 0] * 10 + X[i, 1] * 5 > 100:
y[i]=1
return X, y
def split_data(X, y, rate):
data_len = y.size
y.resize((data_len, 1))
data = numpy.concatenate((X, y), axis=1)
numpy.random.shuffle(data)
test_len = data_len - int(rate*data_len)
return data[:test_len, :2], data[:test_len, 2], data[test_len:, :2], data[test_len:, 2]生成的数据分布如图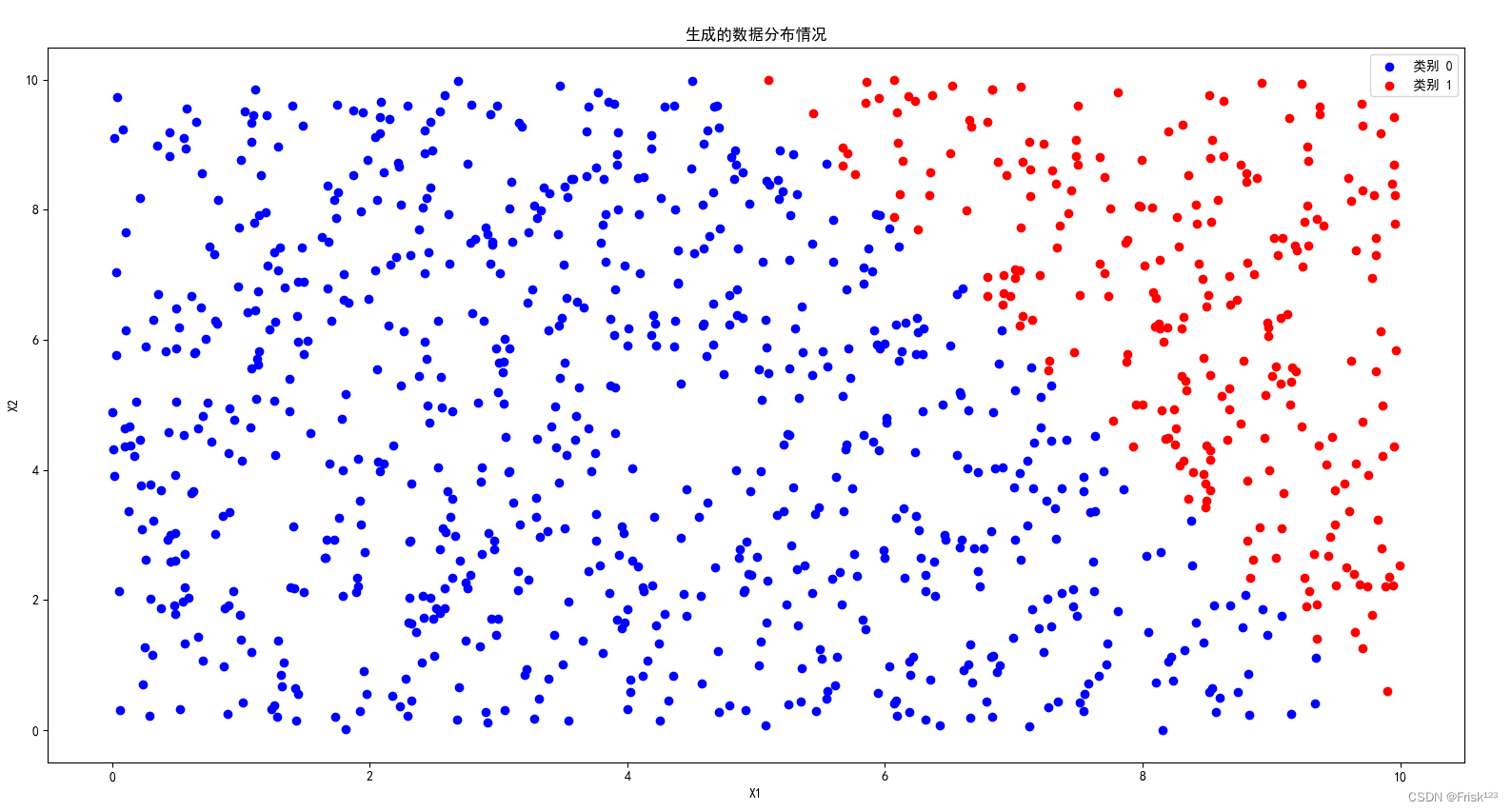
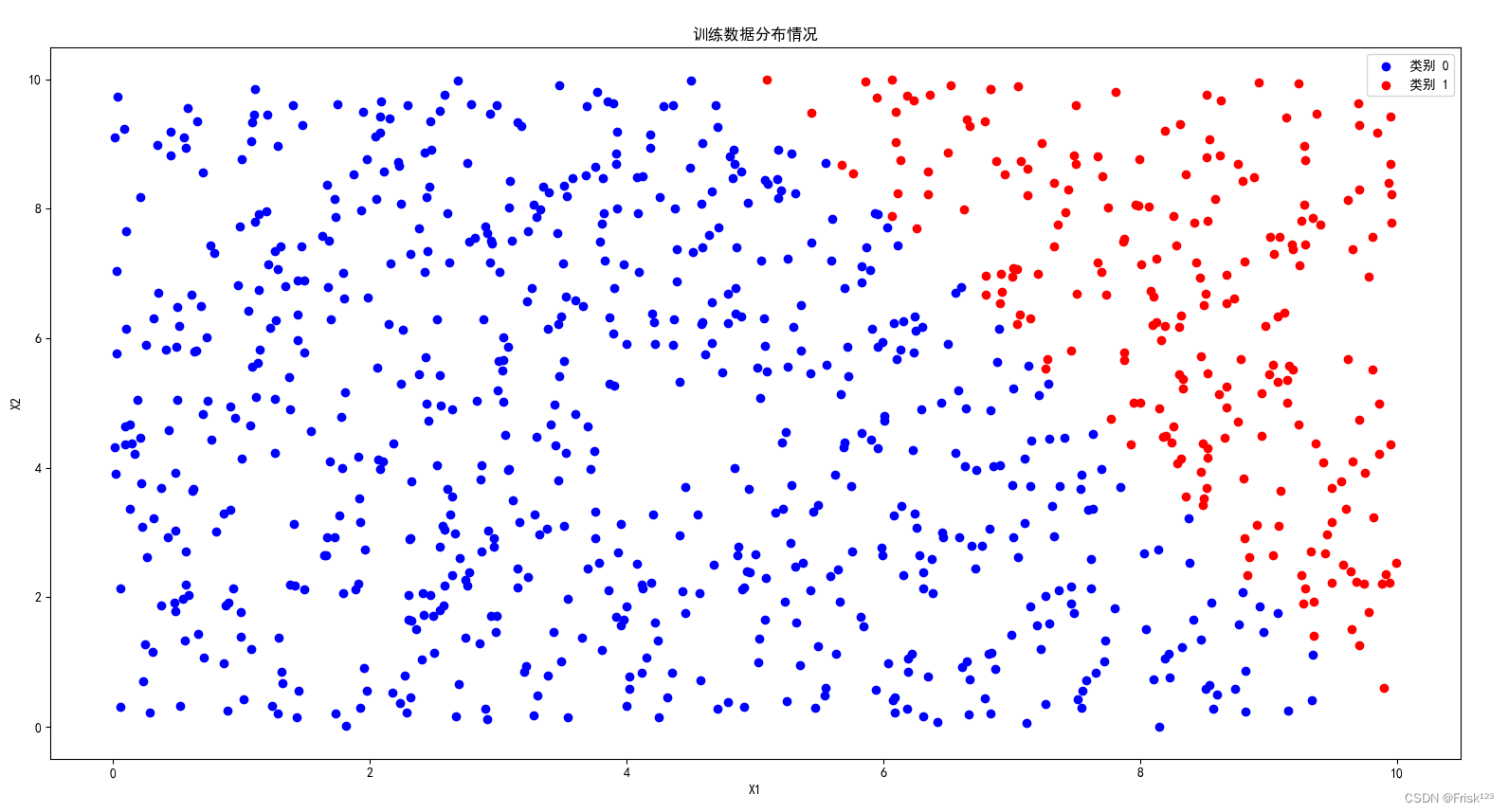
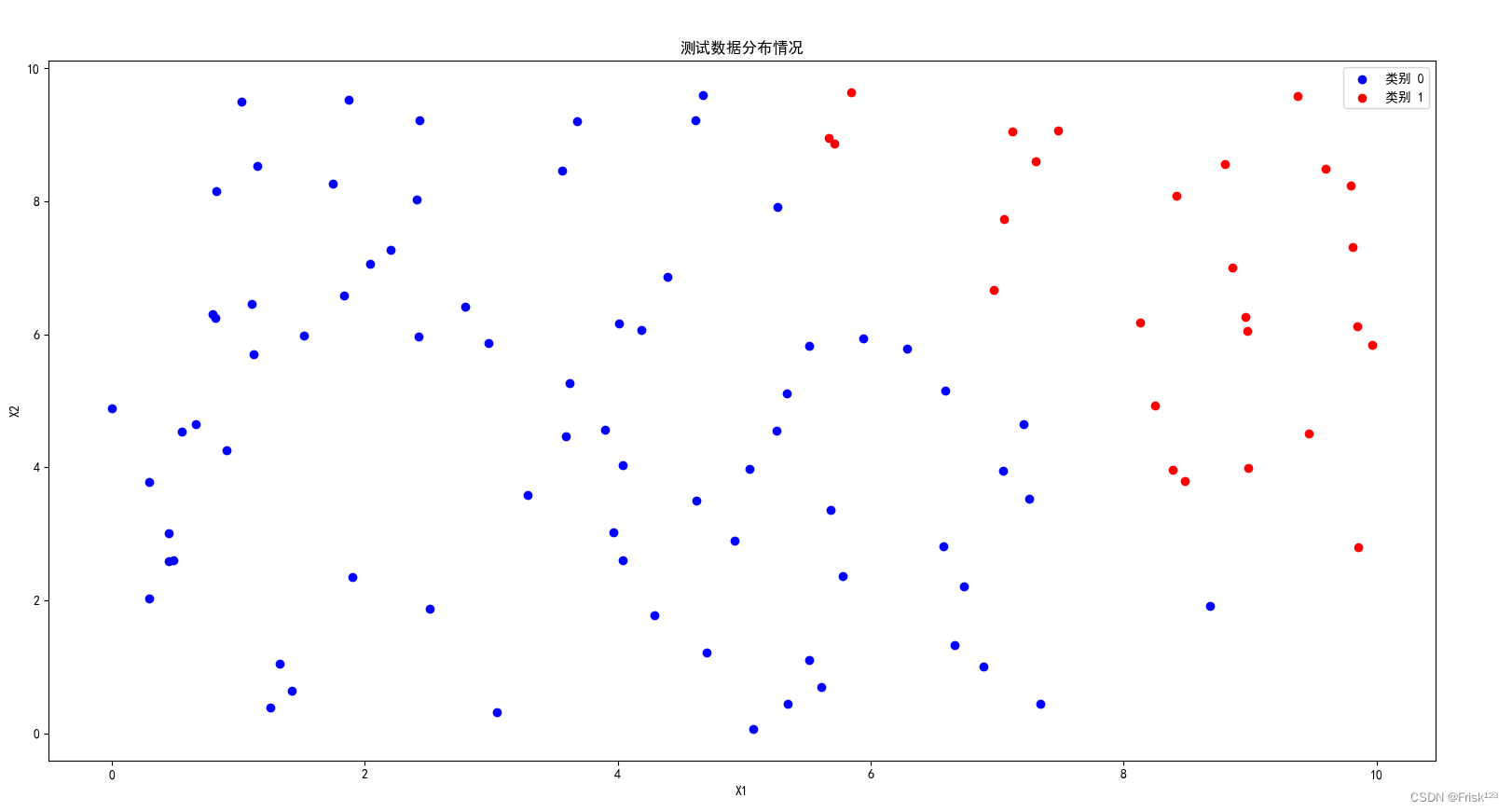
完整代码
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
class LogisticRegression:
def __init__(self, lr=0.05, num_step=1000):
'''
逻辑回归分类器
:param learning_rate: 学习率
:param num_step: 训练步数
'''
self.lr = lr
self.num_step = num_step
self.weights = None
self.bias = None
def sigmoid(self, z):
return 1 / (1 + np.exp(-z))
def fit(self, X, y):
num_samples, num_features = X.shape
# 初始化权重和偏置 w全部置为1 b置为0
self.weights = np.ones(num_features)
self.bias = 0
# 梯度下降优化
for _ in range(self.num_step):
#得到线性模型预测值,结果用sigmod函数映射到(0, 1)上作为预测的概率
linear_model = np.dot(X, self.weights) + self.bias
y_predicted = self.sigmoid(linear_model)
# 计算梯度
dw = (1 / num_samples) * np.dot(X.T, (y_predicted - y))
db = (1 / num_samples) * np.sum(y_predicted - y)
# 更新权重和偏置
self.weights -= self.lr * dw
self.bias -= self.lr * db
def predict(self, X):
linear_model = np.dot(X, self.weights) + self.bias
y_predicted = self.sigmoid(linear_model)
#预测概率大于0.5,则预测结果为1
pred = [1 if i > 0.5 else 0 for i in y_predicted]
return np.array(pred)
def generate_data(num_samples=100):
# 生成随机特征
X = np.random.rand(num_samples, 2) * 10
# 根据特定规则生成标签,在中心点的右上角全部为1
y = np.zeros(num_samples)
x1, x2 = 0, 0
for i in range(num_samples):
x1 += X[i, 0]
x2 += X[i, 1]
x1 /= num_samples
x2 /= num_samples
for i in range(num_samples):
if X[i, 0] * 10 + X[i, 1] * 5 > 100:
y[i]=1
return X, y
def split_data(X, y, rate):
data_len = y.size
y.resize((data_len, 1))
data = np.concatenate((X, y), axis=1)
np.random.shuffle(data)
test_len = data_len - int(rate*data_len)
return data[:test_len, :2], data[:test_len, 2], data[test_len:, :2], data[test_len:, 2]
def plot_data(X, y, title='data'):
plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='blue', label='类别 0')
plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='red', label='类别 1')
# x1, x2 = 0, 0
# for i in range(y.size):
# x1 += X[i, 0]
# x2 += X[i, 1]
# x1 /= y.size
# x2 /= y.size
# plt.scatter([x1], [x2], color='yellow', label='Center')
plt.xlabel('X1')
plt.ylabel('X2')
plt.title(title)
plt.legend()
plt.show()
def plot_data_test(X, y, pred, title='data'):
right_X, right_y = X[y==pred], pred[y==pred]
wrong_X, wrong_y = X[y!=pred], pred[y!=pred]
plt.scatter(right_X[right_y == 0][:, 0], right_X[right_y == 0][:, 1], color='blue', label='类别 0')
plt.scatter(right_X[right_y == 1][:, 0], right_X[right_y == 1][:, 1], color='red', label='类别 1')
plt.scatter(wrong_X[wrong_y == 0][:, 0], wrong_X[wrong_y == 0][:, 1], color='blue', marker='x', label='类别 0(真实为类别 1)')
plt.scatter(wrong_X[wrong_y == 1][:, 0], wrong_X[wrong_y == 1][:, 1], color='red', marker='x', label='类别 1(真实为类别 0)')
plt.xlabel('X1')
plt.ylabel('X2')
plt.title(title)
plt.legend()
plt.show()
def plot_decision_boundary(X, y, pred, model):
# 确定坐标轴范围
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
# 生成网格点坐标
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
# 使用模型进行预测
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界
plt.contourf(xx, yy, Z, alpha=0.4)
#plt.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolors='k')
right_X, right_y = X[y == pred], pred[y == pred]
wrong_X, wrong_y = X[y != pred], pred[y != pred]
plt.scatter(right_X[right_y == 0][:, 0], right_X[right_y == 0][:, 1], color='blue', label='类别 0')
plt.scatter(right_X[right_y == 1][:, 0], right_X[right_y == 1][:, 1], color='red', label='类别 1')
plt.scatter(wrong_X[wrong_y == 0][:, 0], wrong_X[wrong_y == 0][:, 1], color='blue', marker='x',
label='类别 0(真实为类别 1)')
plt.scatter(wrong_X[wrong_y == 1][:, 0], wrong_X[wrong_y == 1][:, 1], color='red', marker='x',
label='类别 1(真实为类别 0)')
plt.xlabel('X1')
plt.ylabel('X2')
plt.title('决策边界')
plt.show()
num_samples, rate = 1000, 0.1
#构造数据集
X, y = generate_data(num_samples)
train_X, train_y, test_X, test_y = split_data(X, y, rate)
y.resize(y.size)
plot_data(X, y, "生成的数据分布情况")
plot_data(train_X, train_y, "训练数据分布情况")
plot_data(test_X, test_y, "测试数据分布情况")
classifier = LogisticRegression()
classifier.fit(train_X, train_y)
pred = classifier.predict(test_X)
result = pred == test_y
plot_data_test(test_X, test_y, pred, f"精确率:{result.sum()*100/result.size}%")
plot_decision_boundary(test_X, test_y, pred, classifier)结果
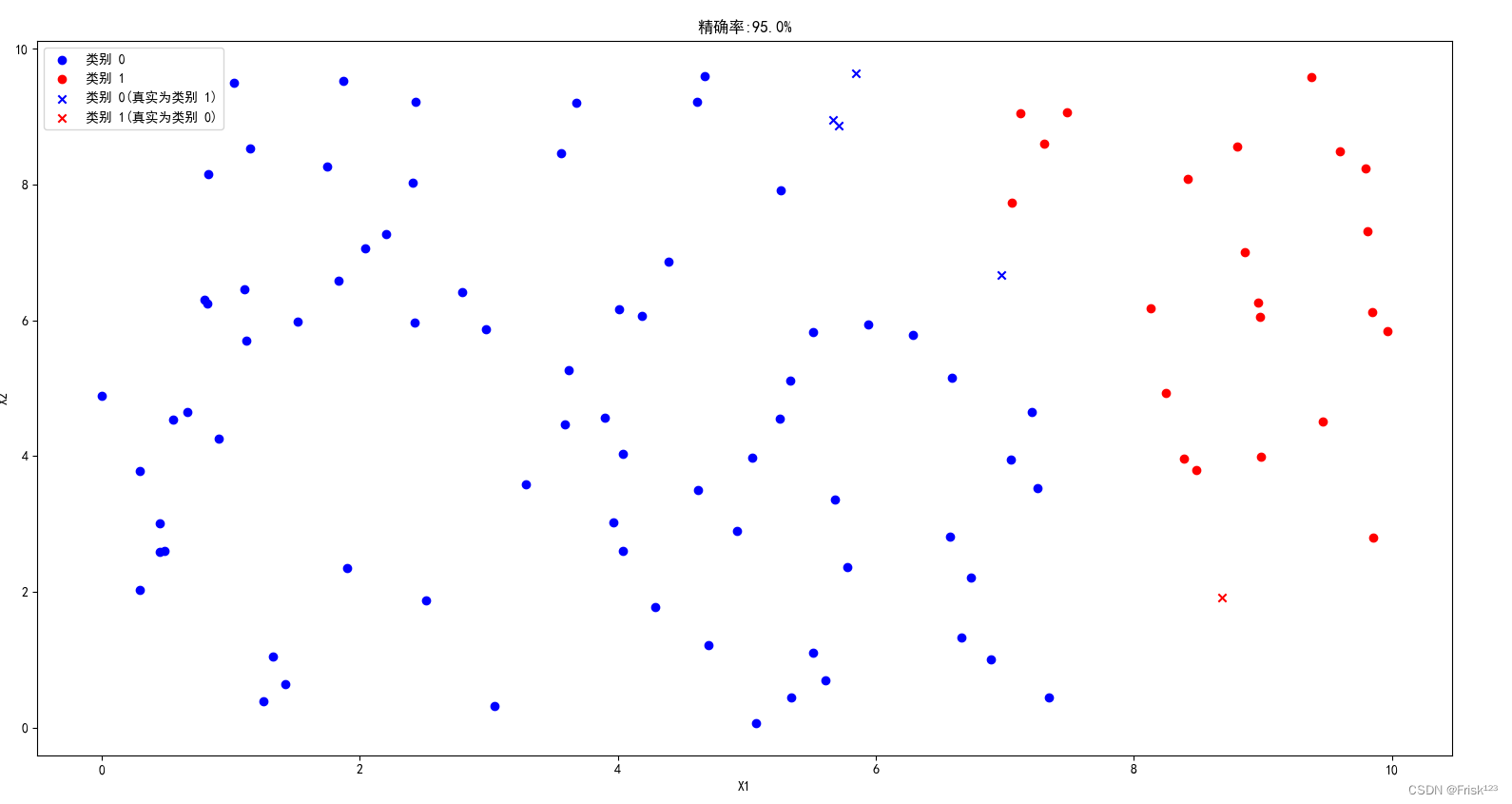
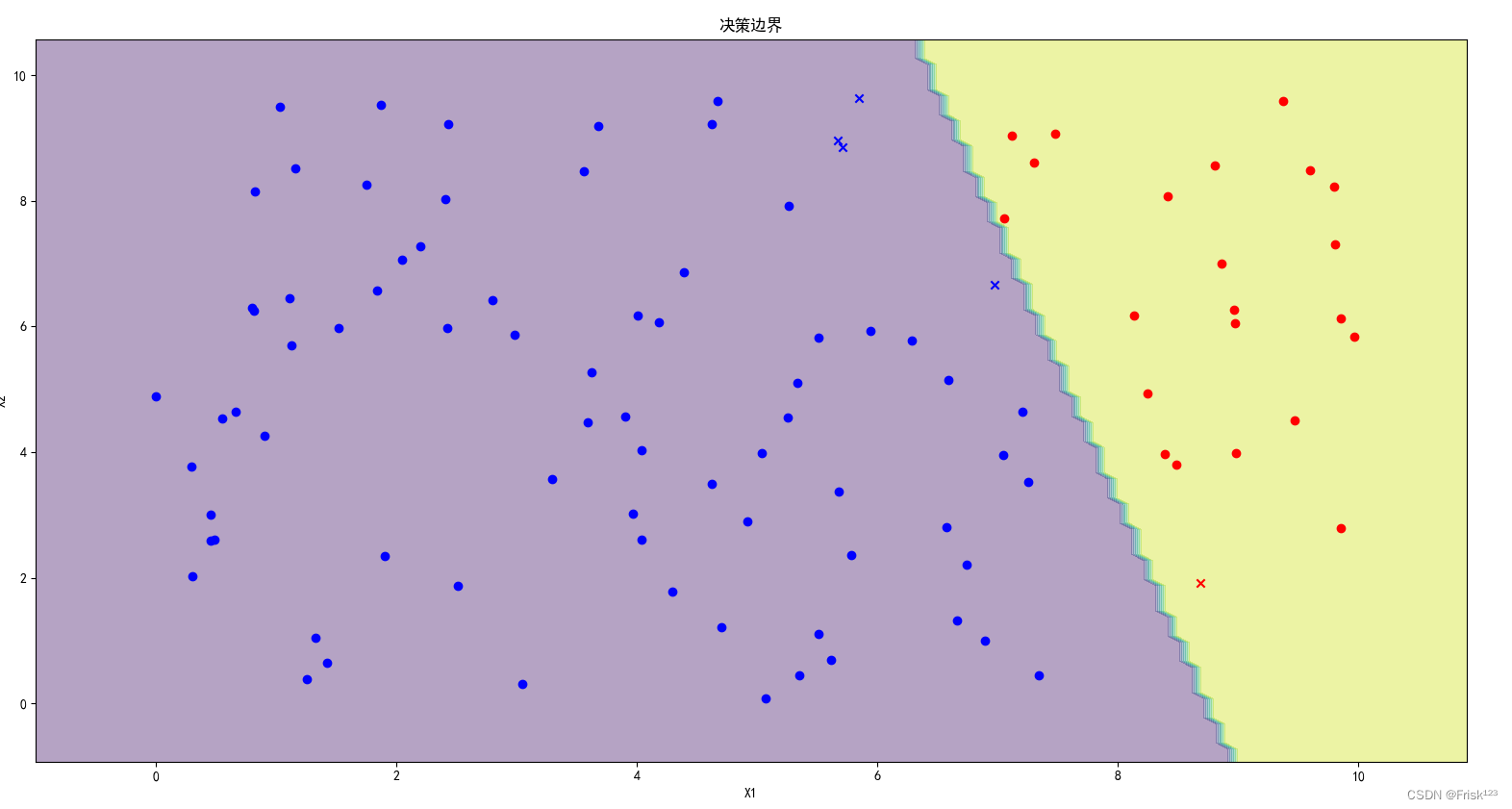
总结
逻辑回归作为一种简单而有效的分类算法,在机器学习领域有着广泛的应用。通过本文的介绍,相信你已经对逻辑回归有了更深入的理解。在实际应用中,逻辑回归可以作为一个强大的工具,帮助我们解决各种分类问题。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









