







文章目录
总结(Practical Federated Gradient Boosting Decision Trees):
1. 每文三问
-
文章在解决什么问题?
现有的在 联邦学习环境中训练 GBDT 的研究存在的不足:
- 由于使用昂贵的数据转换(如安全共享和同态加密)而效率低下
- 由于不同的隐私设计导致模型精度低
-
用了什么方法?
研究了一个具有宽松隐私约束的实用联邦环境。在该环境中,不诚实的一方可能会获得对方 数据的一些信息,但不诚实一方不可能获得对方的原始数据。 具体的说,每一方都通过利用基于位置敏感哈希的相似信息来增加树的数量。 \color{RED}{具体的说,每一方都通过利用基于位置敏感哈希的相似信息来增加树的数量。} 具体的说,每一方都通过利用基于位置敏感哈希的相似信息来增加树的数量。
-
效果如何?
与使用各方本地数据的正常训练相比,该方法可以显著提高预测精度,并且达到与使用原始的 GBDT (没有 Federate GBDT)相当的精度。
2. Introduction
2.1 解决问题 ( 联邦学习环境中训练 GBDT ) 的具体思想
在保护原始数据的同时,利用训练中各方数据之间的相似性,而不是对特征值进行加密。
步骤:
- 首先,在联邦学习上下文中使用 位置敏感散列(LSH)。目的:在不暴露原始数据的情况下收集相似度信息。
- 其次,设计了新的 加权梯度增强(Weighted Gradient Boosting,WGD) 方法,利用带有有界误差的相似度信息来构建决策树。
3. Preliminaries 预备
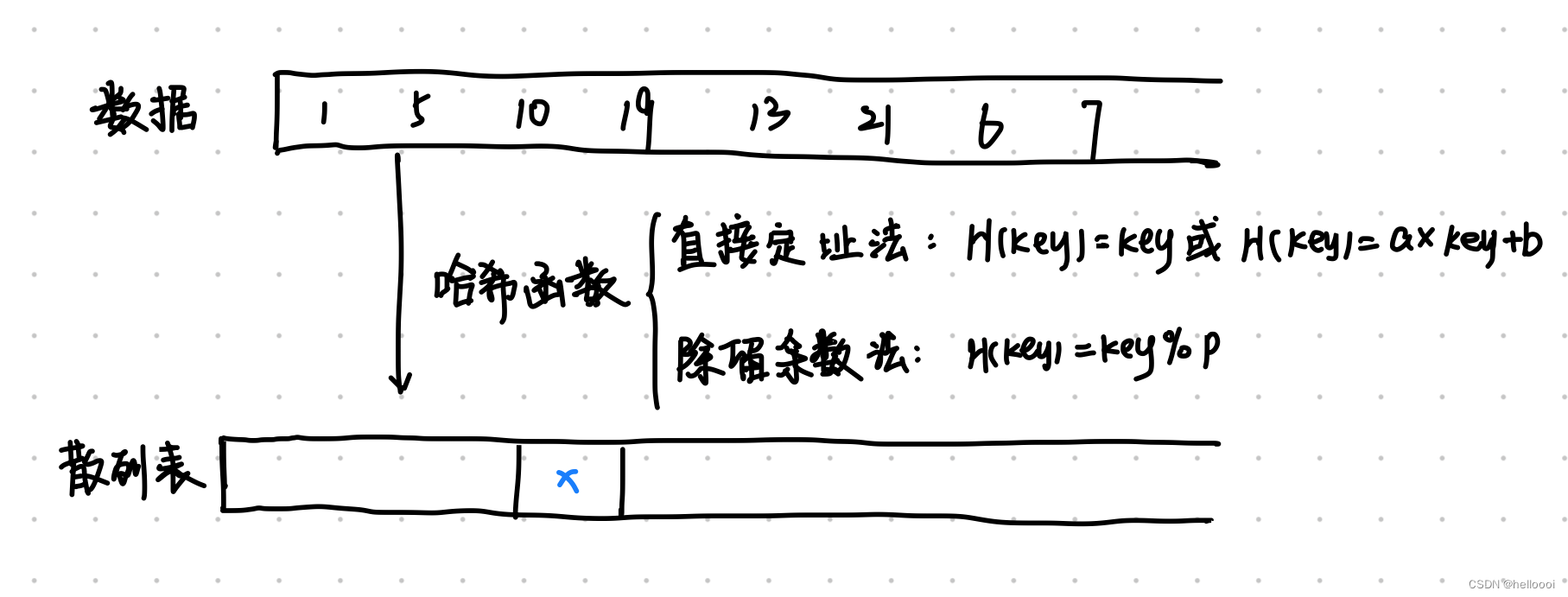
3.1 局部敏感哈希(LSH) :是在海量数据中进行 相似性搜索 的算法。
作用:计算各个参与方之间的 相似样本 。
主要思想:选择一个 哈希函数,使之满足两个相邻点的哈希值大概率相等,两个非相邻点的哈希值大概率不相等。
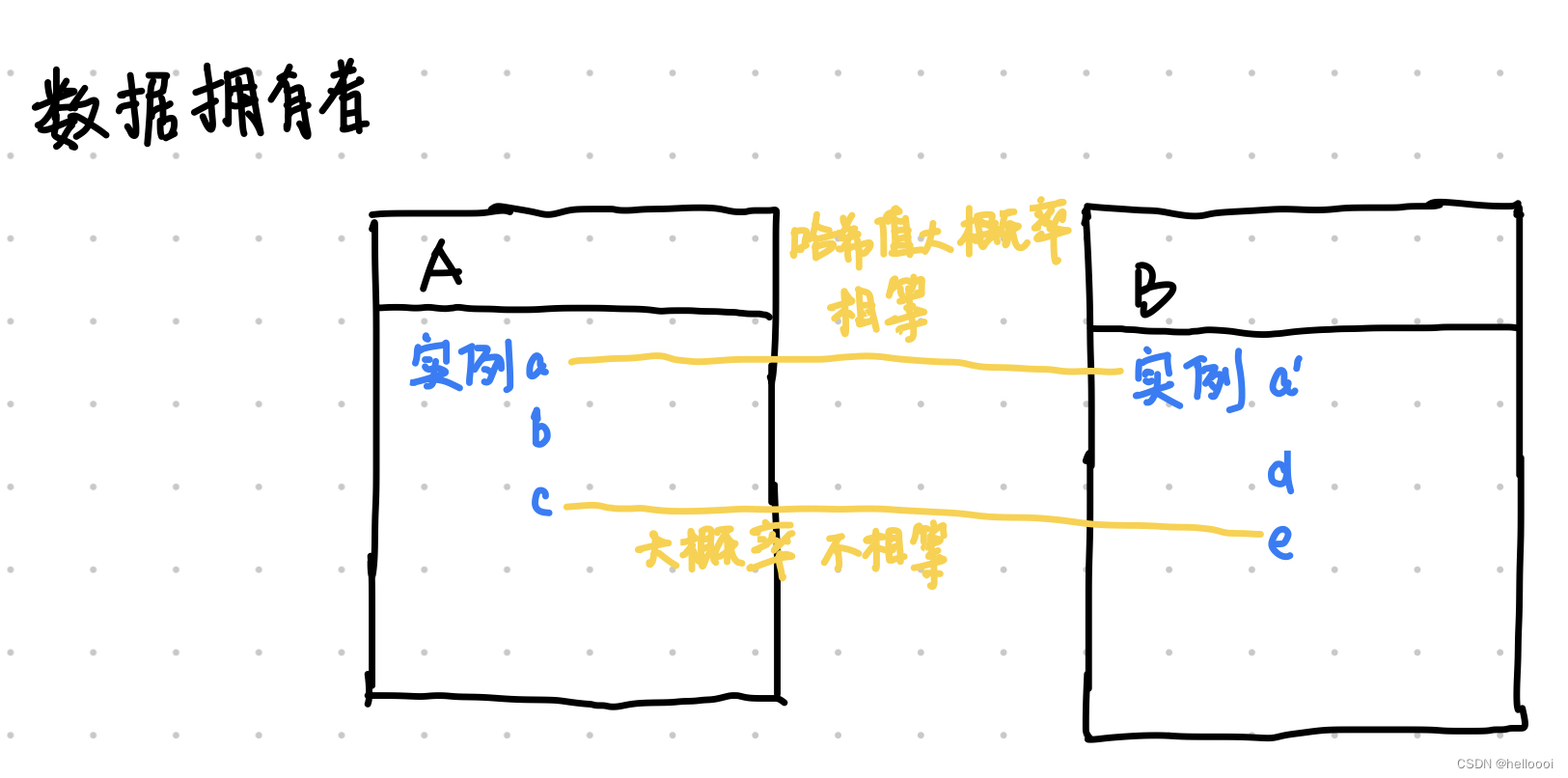
特性:对于相同的散列值,有无穷个输入数据。所以当广播散列值后,并不能推测出输入数据。从而达到保护数据的效果。
2.2 梯度提升决策树 ( GBDT )
定义1:是一种 改进决策树 的机器学习算法,由多个弱学习者通过本地数据集训练回归树,然后按照特定的顺序聚合成 一组树 ,最终形成强学习者。
弱学习者、强学习者:
一个“弱”的学习者(分类器,预测器等)只是表现相对较差的一个学习器,它的准确性高于偶然性,但几乎没有。通常但并非总是如此,这意味着计算简单。弱学习者还建议将算法的许多实例(通过增强,装袋等)合并在一起,以创建“强”集成分类器。
定义2:GBDT 是一个集合模型,用于训练一系列决策树。
缺点:不能充分地利用弱学习者的本地硬件资源,也会对弱学习者的数据安全带来挑战。
现有解决办法:将 GBDT 与联邦学习相结合。
4. Problem Statement
待看
5. The SimFL Framework - 基于相似性的联邦学习 (在横向联邦中训练 GBDT)
5.1 An Overview of SimFL
SimFL有两个阶段:预处理、训练
预处理阶段:
-
在实践中,预处理可以完成一次,并在多次训练中重用。只有当训练数据有更新时,才需要再次进行预处理
-
预处理步骤,
-
参与方首先使用随机生成的LSH函数计算哈希值
-
收集各方的LSH哈希值,构建多个全局哈希表并广播给所有参与方。which can be modelled as an AllReduce communication operation.
-
最后,**每一方 ** 都可以使用全局哈希表通过计算相似度信息来构建树,而不需要访问其他方的原始数据
-
训练阶段:
- 各方一起利用相似度信息,逐个训练若干棵树。一旦一棵树在某一方中被建成,他将被发送给其他参与方以用于更新梯度。
我们获得所有的决策树作为最终学习模型。
5.2 The Preprocessing Stage
目的:获取其他方相似实例的ID。
5.2.1 前置思考问题
- 为什么需要 计算各个参与方的相似样本?
结论:1. 如果一个实例与许多其他实例相似,那么它就是重要并且具有代表性的;
2. 梯度可以代表一个实例的重要性。(相似样本越多代表其梯度对于更新树模型越重要)
收集相似实例 ==> 收集重要实例 ==> 直接影响到梯度信息 ==> 影响树模型
- 怎么确保可以更好的找到相似样本?(多次 LSH)
根据LSH,如果两个实例相似,那么他们被哈希到相同值的概率就更高。
我们可以通过应用多个 LSH函数,两个实例的相同哈希值的数量越多,它们就越有可能相似。
AllReduce communication operation:
- 输入:各方的实例id 及其哈希值
- 操作:将具有相同哈希值的实例id合并构建全局哈希表
5.3 The Training Stage
为了充分利用各方实例之间的相似性信息,提出 加权梯度增强 算法( Weighted Gradient Boosting,WGD )。
创新点:
WGB 每个参与者 B m {B^m} Bm 本地在第 t 次迭代时最小化的目标函数
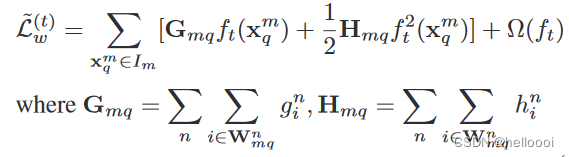
不仅仅使用 X q m {X^m_q} Xqm 的梯度。而是 G m q G_ {mq} Gmq、 H m q H_ {mq} Hmq ,二者是与 X q m {X^m_q} Xqm 相似的实例的梯度之和(包括 X q m {X^m_q} Xqm 本身)。
5.4 预处理、构建树阶段伪代码


6. 师姐的文献与该文献的异同
不同点:
-
加了中心服务器端 ( 聚集器 )
-
根据相似实例数的多少来选择第一个构建者
共同点:
- 均使用的 G m q G_ {mq} Gmq、 H m q H_ {mq} Hmq [ 最大的创新点 ]
7. 不明白的地方
- 构建树中 H m q H_ {mq} Hmq <— G m q G_ {mq} Gmq + h q i {h^i_q} hqi ,为什么是 G m q G_ {mq} Gmq ?
8. 文献之间
-
与
eFL-Boost_Efficient_Federated_Learning_for_Gradient_Boosting_Decision_Trees的不同1:SimFL中每个数据拥有者均会各自构建一棵树eFL-Boost中会从数据拥有者中选出一个 B {B} B 来构建树( B {B} B 是按照预定的顺序选择的 )
-
与
eFL-Boost_Efficient_Federated_Learning_for_Gradient_Boosting_Decision_Trees的不同2:SimFL中建树使用 instances I m {I_m} Im 和 加权梯度 G m ∗ 、 H m ∗ {G_{m*}、H_{m*}} Gm∗、Hm∗eFL-Boost中建树使用 树结构(only the tree structure) 和 w i {w_i} wi
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











