







Infrared and visible image fusion via detail preserving adversarial learning
(通过细节保留对抗学习进行红外和可见光图像融合,本质上是对FusionGAN进行的一个延伸)
介绍
红外热辐射信息以像素强度为特征,而可见图像中的纹理细节信息通常以边缘和梯度为特征。
之前FusionGAN提出的端到端虽然可以保留V-I的图像信息,但是,首先FusionGAN仅依靠对抗性训练来增加额外的详细信息,这种信息是不确定的和不稳定的,从而导致丢失大量的详细信息。其次,FusionGAN中的内容丢失仅重视可见图像中的边缘信息,而忽略了红外图像中的边缘信息,因此融合结果中的目标边缘趋于模糊。
为了克服这两个挑战,本文设计了两个损失函数,即细节损失和目标边缘增强损失,以提高细节信息的质量并锐化红外目标的边缘。
贡献
1)FusionGAN的融合结果趋于平滑和模糊,这是通过优化 𝓁 2范数来解决的常见问题。针对这一问题,我们提出了细节丢失来约束融合结果和可见图像在语义层面上更加相似,这不仅可以使融合结果更加清晰,而且可以保留更多有用的细节信息。
2)FusionGAN旨在保留红外图像的辐射信息,而忽略了红外图像中纹理 (例如显着物体的边缘) 可以反射的细节信息。为了解决这个问题,我们**设计了目标边缘增强损耗,以进一步优化目标的纹理,**从而在融合结果中使目标的表达更加清晰。与FusionGAN相比,细节损失和目标边缘增强损失在很大程度上保留了源图像中的有用信息。
3)我们深化了GAN框架中的生成器和鉴别器。更深的网络具有更强大的特征表示能力,具有更强的能力来优化我们的损失函数并提高融合结果的性能。
4)我们在两个公开可用的数据集上提供了我们的方法与九种最新方法之间的定性和定量比较。与竞争对手不同,我们的方法可以生成具有清晰突出显示和边缘锐化目标以及更多纹理的融合图像
相关工作
可见图像中的详细信息包括梯度,对比度和饱和度等。因此,梯度变化不能有效地保留可见图像中包含的有用细节信息
Generative adversarial network
GAN的主要思想是在生成器和判别器的学习之间建立minmax两人游戏。生成器将噪声作为输入,并尝试将该输入噪声转换为更真实的图像样本。同时,鉴别器将生成的样本或现实样本作为输入,其目的是确定输入样本是从生成的样本还是现实样本得出的。生成器和鉴别器之间的对抗特性一直持续到鉴别器无法区分生成的样本为止。随后,生成器可以产生相对更真实的图像样本。尽管原始GAN可以用于生成数字图像,例如从MNIST获得的图像,但是噪声和不可理解的信息仍然存在于生成的结果中。 提出的LAPGAN 方法是与Laplacian金字塔一起使用,以生成由低分辨率图像监督的高分辨率图像; 但是,这种方法不适用于包含摇摆物体的图像。为了解决在训练过程中GAN稳定性弱的问题,修改了GANs的目标函数,提出了WGAN 来放松GAN训练要求,但是与常规GAN相比,该模型收敛速度较慢,通过使用最小二乘损失函数作为判别器解决了该问题。GAN最广泛使用的变体是condition GAN ,它在条件设置中应用GAN,并强制将输出以输入为条件,本论文也是基于condition GAN。
Perceptual(感知) loss for optimization
使用感知损失来解决与图像样式转移和图像超分辨率有关的问题,感知损失通常用于比较从卷积网络中提取的高级特征,而不是通过检查像素本身。受使用感知损失的优势的启发,我们在损失函数中引入了一个细节项目,以促进融合性能。但是,与通过预先训练的VGG网络计算的通常的感知损失不同,我们在研究中使用鉴别器作为特征提取器来计算细节损失。
方法
Motivation
使用CNN生成融合图像可以克服手工设计活动水平测量和融合规则的困难,但有以下两个问题:
1)在深度学习领域,培养一个优秀的网络需要大量有标签的数据。换句话说,在CNN培训程序中,地面真相对于监督至关重要。但是,在图像融合问题中不存在真正融合的图像。为了解决这个问题,我们将融合问题转化为回归问题,其中需要一个损失函数来指导回归过程。鉴于我们的融合目的,GTF *(Gradient Transfer Fusion(梯度转移融合))*的目标函数旨在保留热辐射信息和可见的纹理细节,是一个不错的选择。
2)GTF中的细节信息仅表示为梯度变化,这表明放弃了其他重要的细节信息,例如对比度和饱和度。然而,这种详细信息通常不能被描述为数学模型。
所以提出了利用GAN网络架构,我们通过使用生成器求解GTF中的目标函数来生成看起来像GTF结果的融合图像。然后将带有可见图像的结果发送到鉴别器,以判断图像是否来自源数据。通过在生成器和鉴别器之间建立对抗性,当鉴别器无法将融合图像与可见图像区分时,我们假设我们的融合图像包含有足够的详细信息。通过使用此方法,详细信息由神经网络而不是手动设计的规则自动表示和选择。此外,除了对抗性损失之外,我们的损失函数还包含额外的细节损失和目标边缘增强损失。这些项目使我们的模型在对抗过程中保持稳定,并具有非常有希望的融合性能。
整体框架
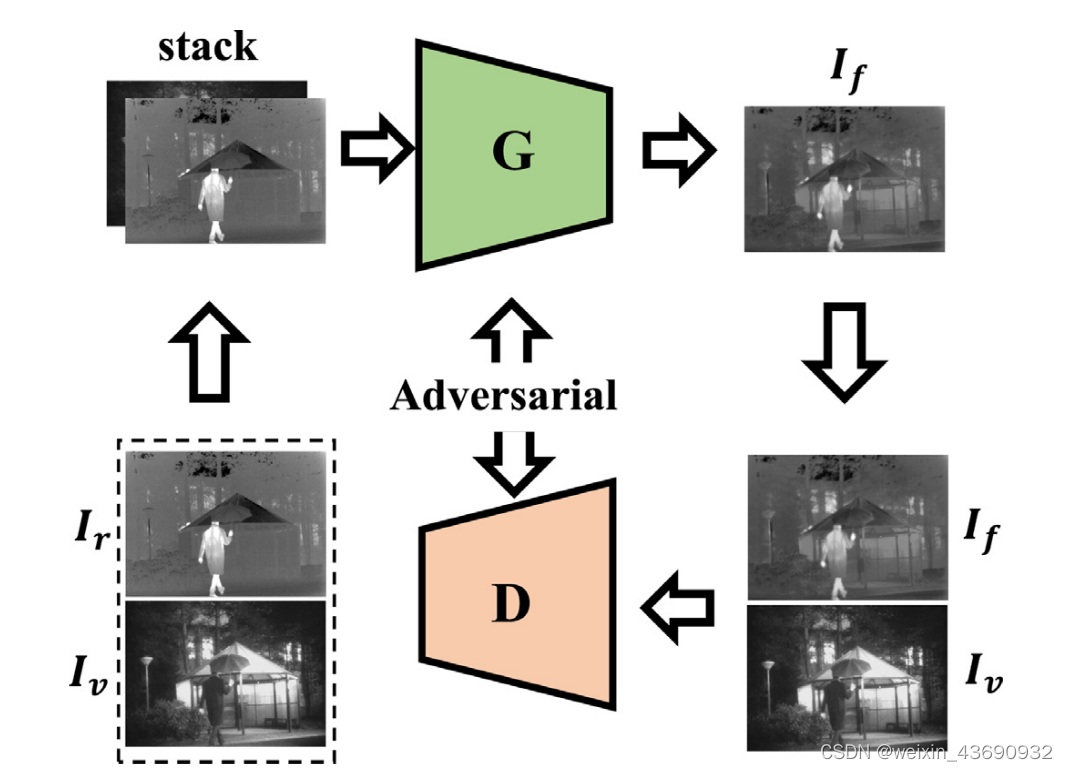
在训练阶段,我们首先将红外图像I r和可见图像I v堆叠在通道尺寸中,然后将堆叠的图像放置到生成器G中,类似于ResNet。在损失函数的指导下,我们可以从G获得原始融合图像I f。随后,我们将I f和I v输入到鉴别器D中,鉴别器D的体系结构近似于vgg-net的体系结构,以判断哪个样本来自源数据。重复上述训练过程,直到D无法区分融合图像和可见图像。最后,我们获得了G,该G具有很强的生成融合图像的能力,并具有突出的锐化边缘目标和更丰富的纹理。
Network architecture
所提出的模型由基于不同网络体系结构的生成器和判别器组成,如下图所示:
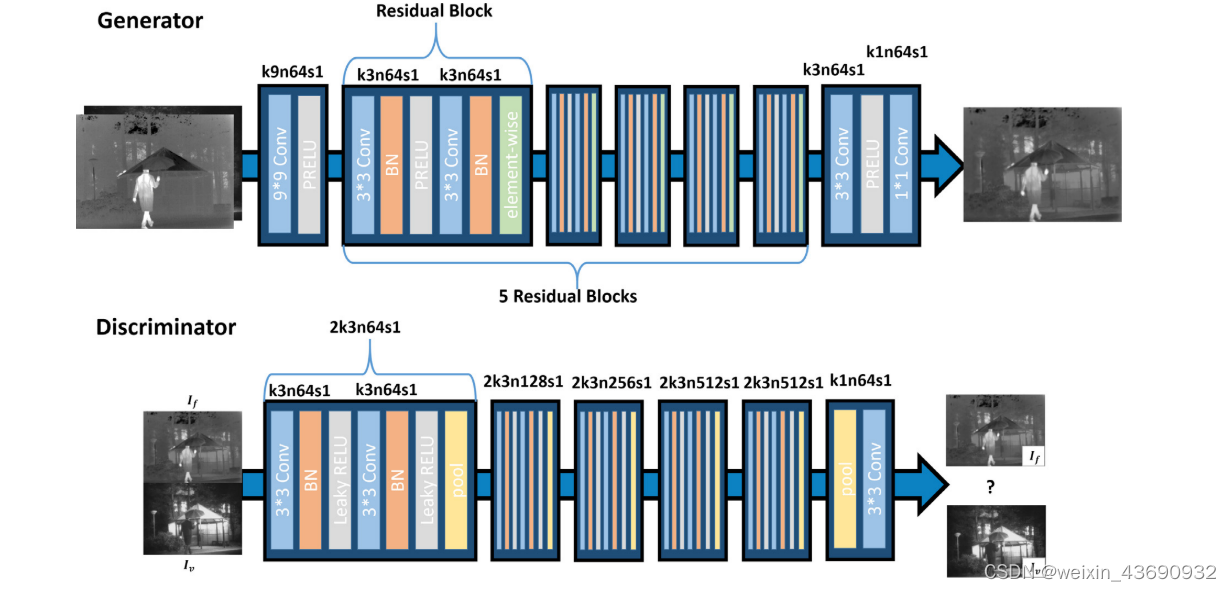
(生成器基本单元是ResNet中提出的残差块。鉴别器的网络架构类似于VGG11网络)
特别是,生成器是基于ResNet 设计的。在我们的生成器网络中,残差块的激活函数是parametric rectified linear unit(RELU),而不是 typical RELU。The parametric RELU is the same as leaky RELU, 不同之处在于rametric RELU的斜率是通过反向传播自适应学习的参数。此外,我们使用1 × 1卷积层代替完全连接的层并构建完全卷积的网络,该网络不受输入图像大小的限制。因此,这种方法不同于一般的GAN,因为我们的模型不包含反卷积或池化层。池化层会删除一些细节信息,而反卷积层会在输入中插入额外的信息,两种情况都表明对源图像真实信息的描述不准确。
鉴别器的设计基于VGG11网络 。Vgg11中使用了五个卷积层和五个maxpooling层。相比之下,我们网络中的每个卷积层之后都是批归一化层,这已被证明可以有效地加速网络训练。对于激活函数,我们将一般的remu替换为参数ReLU,以调整反向传播过程中的泄漏程度。然后,我们添加另一个卷积层 (1 × 1滤波器) 以减小尺寸,这意味着可以忽略VGG中的完全连接的层。判别器用于对图像是否是可见图像进行分类,因此,可以用简单的卷积层代替大规模的全连接网络。因此,生成器和鉴别器网络都可以被视为对不同大小的输入图像具有鲁棒性的全卷积网络。
Loss Function
生成器损失由内容损失、细节损失、目标边缘增强损失和对抗性损失组成,它们表示如下:
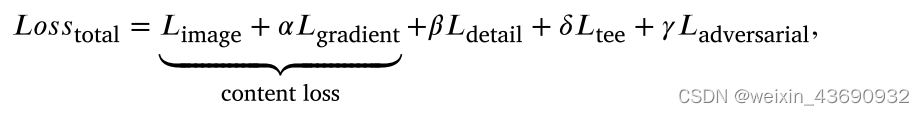
其中内容损失将融合图像限制为具有与红外图像相似的像素强度和与可见光图像相似的梯度变化的图像,这可以类似于GTF的目标函数;
The detail loss 𝐿detail and adversarial loss 𝐿adversarial aim at adding more abundant detail information to the fused image.
The target edge-enhancement loss 𝐿tee is for sharpening the edges of highlighted targets in the fused image.
We formulate the content loss as the sum of image loss 𝐿image and gradient loss 𝐿gradient .
然后,我们使用 𝛼,𝛽,𝛿 的权重参数来控制生成器损耗中不同项目之间的权衡。
Content Loss
The pixel-wise image loss 𝐿image is defined based on MSE as follows: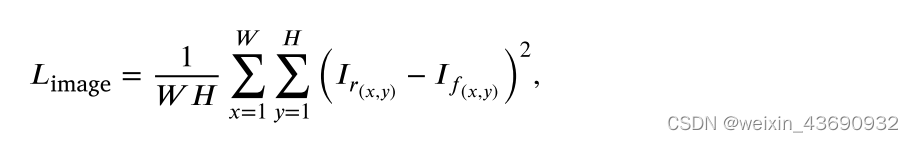
其中I r是原始红外图像,I f是发生器的最终输出,W和H表示图像的宽度和高度。图像损失使融合图像在像素强度分布方面与红外图像一致。请注意,我们选择 𝓁 2范数是因为它是二次的。与 𝓁 1范数相比,𝓁 2范数具有可导性,易于优化。
To fuse rich textural information, we design the gradient loss inspired by GTF as follows:
Detail loss
我们将融合图像和可见图像之间的鉴别器特征图的差异定义为细节损失,如下所示:
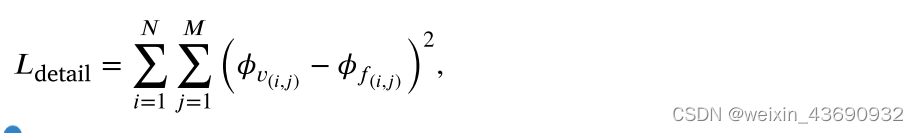
其中,𝜙 描绘了鉴别器内卷积得到的特征图,𝜙 v和 𝜙 f表示可见图像和融合图像的特征表示,N和M表示结果的宽度和高度,这是常规特征图计算的输入图像。
我们不用VGG-net 提取高级特征,因为它从融合图像 (热辐射信息和可见纹理信息) 中提取高级特征是不确定的
Target edge-enhancement loss
We formulate target edge-enhancement loss 𝐿tee as follows:
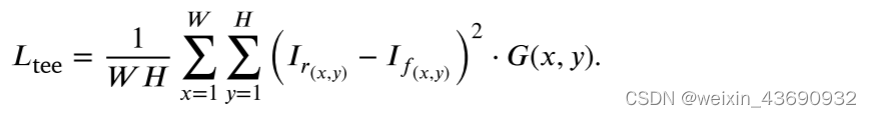
其实这个和 𝐿image差不多。为了使目标边界更加锐化,设计了一个权重图G,以更加关注目标边界区域并乘以 𝐿 图像,其中G定义如下:
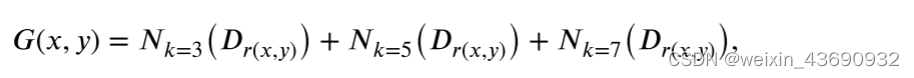
其中N表示Gaussian kernel,k对应于核半径,Dr (x,y) 表示红外图像的梯度。在这里,我们根据经验使用组合 𝑘 = 3,5,7作为我们的默认配置。显然,我们的G map有三个特征。首先,大多数区域的权重为0,因为可以通过 𝐿 image很好地优化这些区域,并且它不需要在 𝐿tee中再次优化它们。其次,红外目标边界区域中的权重较大,这使我们的模型能够专注于训练过程中可见图像中可能忽略的红外目标边界。第三,靠近边缘区域的零件可以获得较小的重量,这将在边缘区域的两侧实现平滑过渡。
Adversarial loss
我们的生成器网络采用了对抗性损失,并带有鉴别器,以生成更好的融合图像。基于所有训练样本的鉴别器日志 𝐷 𝜃𝐷 ( 𝐺 mix) 的概率定义了对抗性损失,如下所示:

PS:对文章内容的批注
1)1*1卷积核的优势
2)反卷积层也叫转置卷积















 4291
4291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









