







UNFusion: A unified multi-scale densely connected network for infrared and visible image fusion
(UNFusion: 用于红外和可见光图像融合的统一多尺度密集连接网络)
大多数基于深度学习的方法主要侧重于卷积操作来提取局部特征,但没有充分考虑其多尺度特征和全局依赖性,这可能会导致融合图像中目标区域和纹理细节的丢失。为此,我们在本文中提出了一个统一的多尺度密集连接的融合网络,称为UNFusion。我们精心设计了一种多尺度编码器-解码器体系结构,可以有效地提取和重建多尺度深度特征。在编码器和解码器子网络中都采用了密集的跳过连接,以重用不同层和尺度的所有中间特征来执行融合任务。在融合层中,提出了包括三种不同范数的Lp归一化注意力模型,从空间维度和通道维度去突出和组合这些深层特征,并使用组合的空间和通道注意力图来重建最终的融合图像。
介绍
传统的变换,例如金字塔 (pyramid),小波(wavelets ),曲线(curvelets)和非子采样轮廓变换(nonsubsampled contour transform) 是用于图像融合的常用工具。基于稀疏表示的方法采用字典学习来建立稀疏模型,并采用稀疏系数来重建融合图像。从训练数据中学到的字典可能会提高图像特征表示能力。混合方法通常结合不同方法的优点,通过克服单一方法的局限性来获得更好的结果。例如,多尺度嵌入式变换方法 ,多尺度变换与稀疏表示方法的结合。基于显著性的方法采用显著性区域提取来增强图像特征或权重计算来指导特征组合。基于子空间的方法 通常将高维图像投影到低维子空间中,以提取固有结构特征。但是,这些方法通常忽略了源图像的差异,并且在没有区别的情况下提取了相似的显着特征,这对融合图像产生了负面影响。此外,手工变换参数和高计算强度始终是限制其应用的难点。
基于卷积神经网络或生成对抗网络的方法获得了显著的性能。即便如此,它们中的大多数仍然有一些缺点。首先,这些方法取决于最后一层的特征,而中间层的特征相关性却被忽略了,固有的困境是图像融合任务的表示能力受到阻碍。其次,这些方法不能有效地提取多尺度深度特征,而精细和粗糙尺度特征对于表示不同对象的空间信息很重要,这可能会导致融合图像中的细节缺失和光晕伪影。最后,这些方法专注于局部特征的提取,而不考虑其全局依赖性,局部深度特征没有细化和增强,这可能会导致目标区域的亮度降低和融合图像中纹理细节的模糊。
为了解决上述问题,本文提出了一个统一的多尺度密集连接的网络,称为UNFusion。
第一个问题,忽略了中间层的特征相关性,是通过密集连通性解决的。密集的跳过连接被设计到我们的编码器和解码器子网络中。通过连接中间层,可以很好地支配所有特征,以提高特征表示和重建能力。
通过设计多尺度网络结构来解决第二个问题,即缺乏精细和粗略的尺度特征。我们的编码器和解码器子网可以在水平和垂直方向上逐渐聚合多尺度深度特征。从水平角度可以以相同的分辨率组合多尺度深度特征,从垂直角度可以跨不同分辨率集成。
在不考虑全局依赖性的情况下,第三个问题是通过基于关注的融合策略解决的。Lp归一化注意力模型用于从空间和通道维度建立局部特征的全局依赖性。获得的注意力图可以突出重要的特征,而忽略源图像中的不相关特征。
贡献
(1) 在编码器和解码器子网中都引入了密集的跳过连接。通过使用密集连接,可以很好地重用所有不同层和尺度的中间特征图,以提高特征表示和重建能力。
(2) 提出了一种统一的多尺度密集连接网络,用于红外和可见光图像融合。我们的网络可以在整个网络中逐步聚合多尺度特征,这对于提高融合性能非常重要。
(3) 采用Lp归一化注意力模型作为融合策略,突出多尺度深度特征,并从空间维度和通道维度生成加权注意力图。我们的结果可以同时保留典型的目标区域和丰富的纹理细节,更适合人眼观察和其他视觉任务。
(4) 在不同天气条件下,对具有各种场景的公共TNO和Roadscene数据集进行了广泛的消融和比较实验。我们的方法取得了非凡的结果,并且在定性和定量比较方面超越了其他最先进的融合方法。
相关工作
Dense skip connections
最近,跳过连接已成功解决了网络训练中梯度爆炸和梯度消失的问题。高Highway Networks提出了与门控单元的跳过连接,以毫无困难地训练具有100多个层的网络。ResNets的特征映射可以视为跳过连接,并取得了令人满意的结果。Stochastic depth通过随机删除图层来优化训练速度和网络性能。此外,跳过连接用于增加网络宽度。GoogLeNet提出了一个inception模块,该模块将通过不同过滤器获得的特征图进行串联,以提高网络的深度和宽度。FractalNets通过使用不同的深度和许多跳过连接,采用了广泛的网络结构。DenseNets采用了包含密集跳过连接的压缩模型,以重用中间特征并提高效率。MSDNet 将密集跳过连接扩展到多尺度网络中,以进行资源高效的图像分类。
此外,通过链接特征提取和重建,还将跳过连接用于编码器-解码器网络中,以进行生物医学图像分割。例如,UNet提出跳过连接,分别从相应的编码器和解码器子网中结合低级细节和高级语义特征,可以提高特征提取能力并加速收敛。为了减少语义差距,UNet引入了嵌套和密集的跳过连接来聚合特征,并在特征重建方面取得了良好的性能。他们的成功在很大程度上归功于使用跳过连接,这可以保留更多信息并获得更好的结果。此外,跳过连接还用于其他计算机视觉任务,例如图像超分辨率,烟雾检测等。
在本文中,我们同时将密集跳过连接引入编码器和解码器子网,并重新设计了统一的多尺度密集连接网络,用于红外和可见光图像融合。在我们的融合框架中,可以重用不同层的所有中间特征,并且可以在水平和垂直方向上聚合所有不同比例的特征。这些密集的跳过连接用于增强特征表示和重建能力,并进一步提高融合性能。
Deep learning-based image fusion
对于基于深度学习的图像融合叙述(略)
我们的UNFusion与上述体系结构不同,所提出网络的主要修改在于三个方面。
首先,我们的编码器和解码器子网络可以以多尺度方式提取和重建特征。不同的尺度特征可以很好地表示不同对象的重要空间信息。
其次,在编码器和解码器子网络中采用密集的跳过连接,所有中间特征都被重用,以提高特征表示和重建能力。
最后,我们的编码器-解码器网络是一个统一的框架,可以从水平和垂直方向逐步汇总整个网络中的特征。
方法
Network architecture
我们提出的具有四个尺度的UNFusion的网络体系结构,如图2所示。我们的网络包括编码器子网,融合层和解码器子网三个部分。水平方向表示网络的深度,而垂直方向表示深层特征的比例。可以发现,我们的网络在不加深网络的情况下提取了多尺度的深度特征。此外,在编码和解码过程中,通过密集的跳过连接,将层和尺度的所有中间特征重新用于融合。
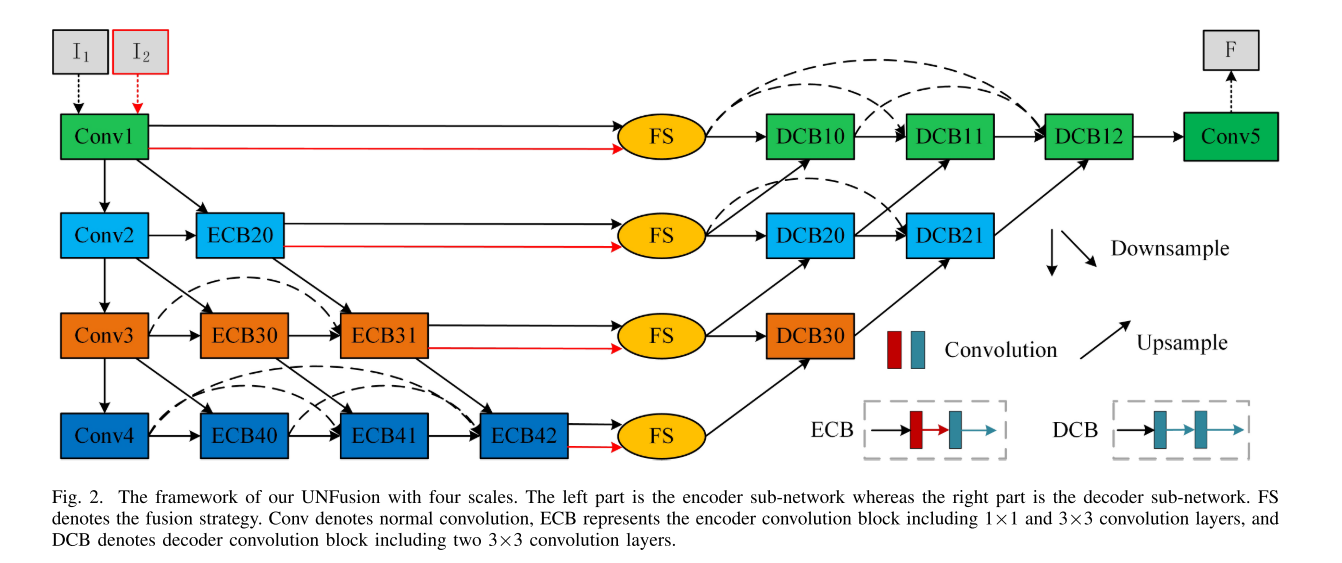
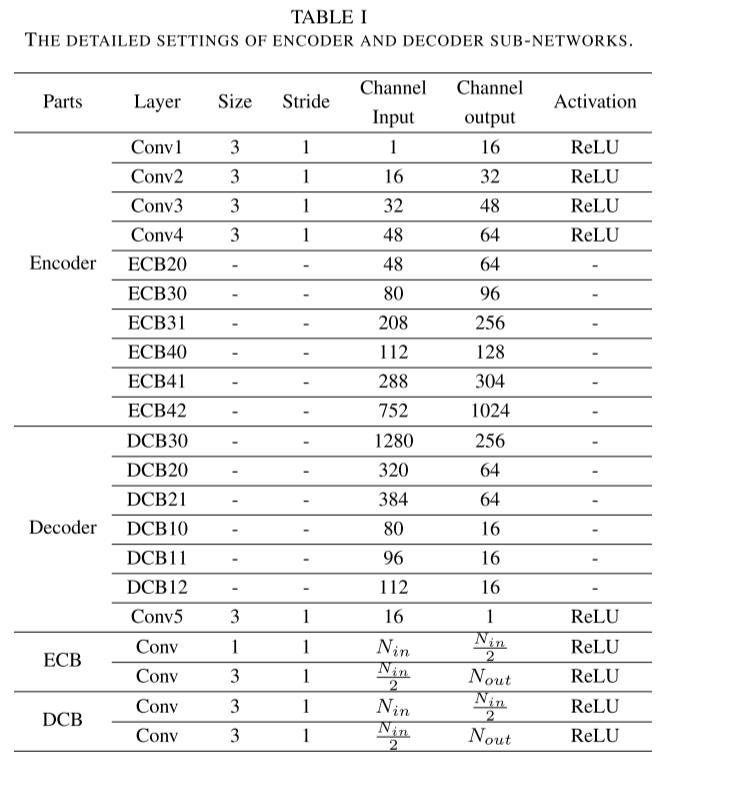
shown in Table I.编码器子网络包含四个正常卷积层和六个编码器卷积块 (ECB)。正常卷积层为3 × 3内核大小。ECB包括1 × 1和3 × 3卷积层。向下箭头表示下采样操作。在我们的网络中,提出了三种下采样操作,例如平均池,最大池和步幅卷积。但是,解码器子网络包括一个正常的卷积层和六个解码器卷积块 (DCB)。DCB由两个3 × 3卷积层组成。向上箭头表示上采样操作,例如最近和双线性插值。所有的卷积层都与 ReLU激活函数一起。拟议网络的详细设置如表1所示。
特别是测试阶段,红外和可见光图像分别送入训练好的编码器子网络模型,可以获得一系列多尺度深度特征。随后,使用基于归一化注意力模型的融合策略来突出显示和组合这些特征图,然后获取空间和渠道注意力图。最后,通过解码器子网络重建组合的多尺度注意图融合图像。融合策略的设计将在下一节中介绍。
fusion strategy
由于注意机制可以增强重要信息和抑制无关信息,因此它在机器视觉中扮演着重要的角色,例如图像字幕,视觉问答等。在这项工作中,我们基于Lp归一化注意力模型开发了一种新颖的融合策略,该模型包含三种归一化方式,以突出并结合空间和通道维度的深层特征。基于归一化注意机制的融合程序如图3所示。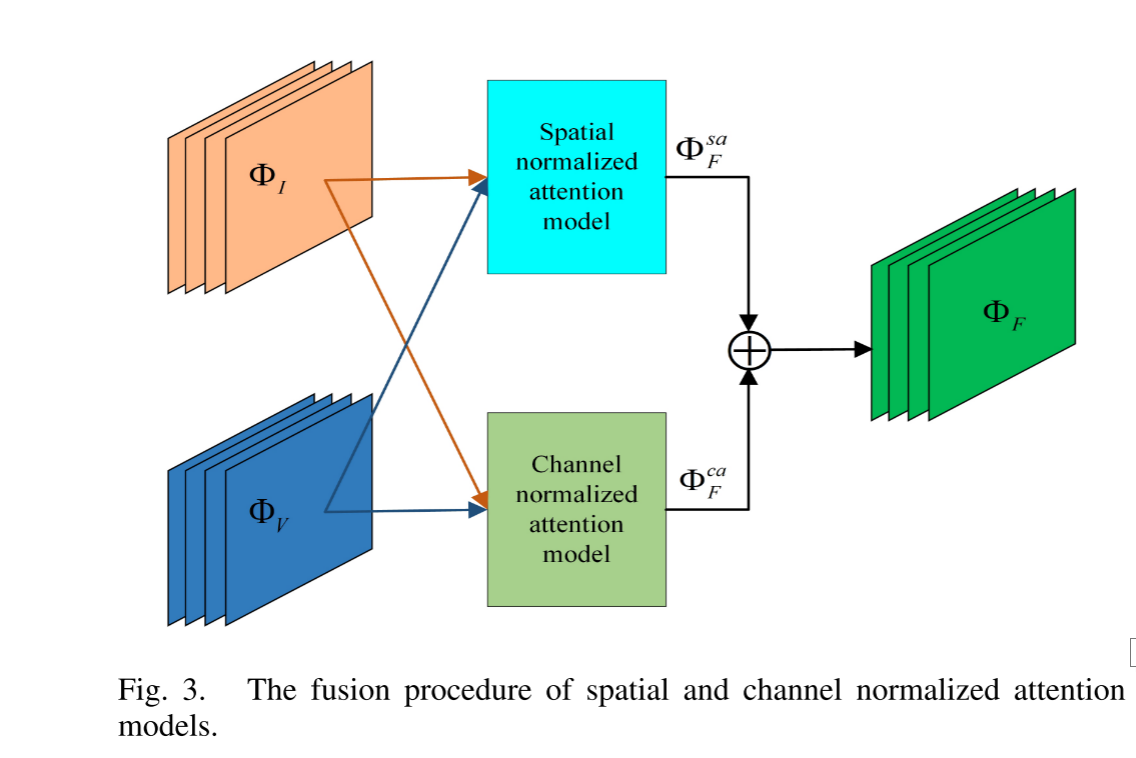
对于红外和可见光图像的多尺度深度特征 (称为 Φ i和 Φ v),空间和通道归一化注意模型来生成其相应的注意图,称为 Φ sa F和 Φ ca F,然后采用加权平均融合规则来获得最终的融合注意图,可以计算为eq.1。


维度通道。||·|| 表示Lp范数。
然后,可以通过Eq.4和5来制定红外和可见光图像的加权图,这些图像由softmax函数在其初始空间注意力图的基础上进行操作。

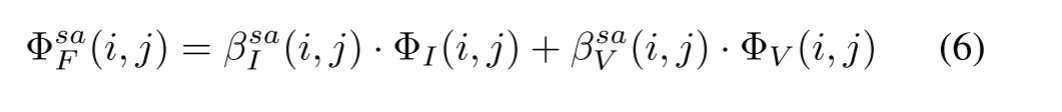
2)Channel normalized attention model:


















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









