









一:特色浅析
和v6一样,对网络结构进行了大量改变,YOLO_v7有许多前人的影子,比如将YOLO_v6的RepConv故技重施,损失函数也和YOLOv5完全一样,都是上、下 、左、右的cell中增量选择targets。当然,其中还是有许多不一样的细节点,如下:
- ELAN模块
- MPConv混合卷积
- SPPCSPC
- ImpConv隐性知识学习
- Fine-to-Coarse Auxility Loss
下面我主要介绍上面几个细节,以此贯穿整个网络,我先贴上大牛画的结构图,出自该篇博文,特此鸣谢:
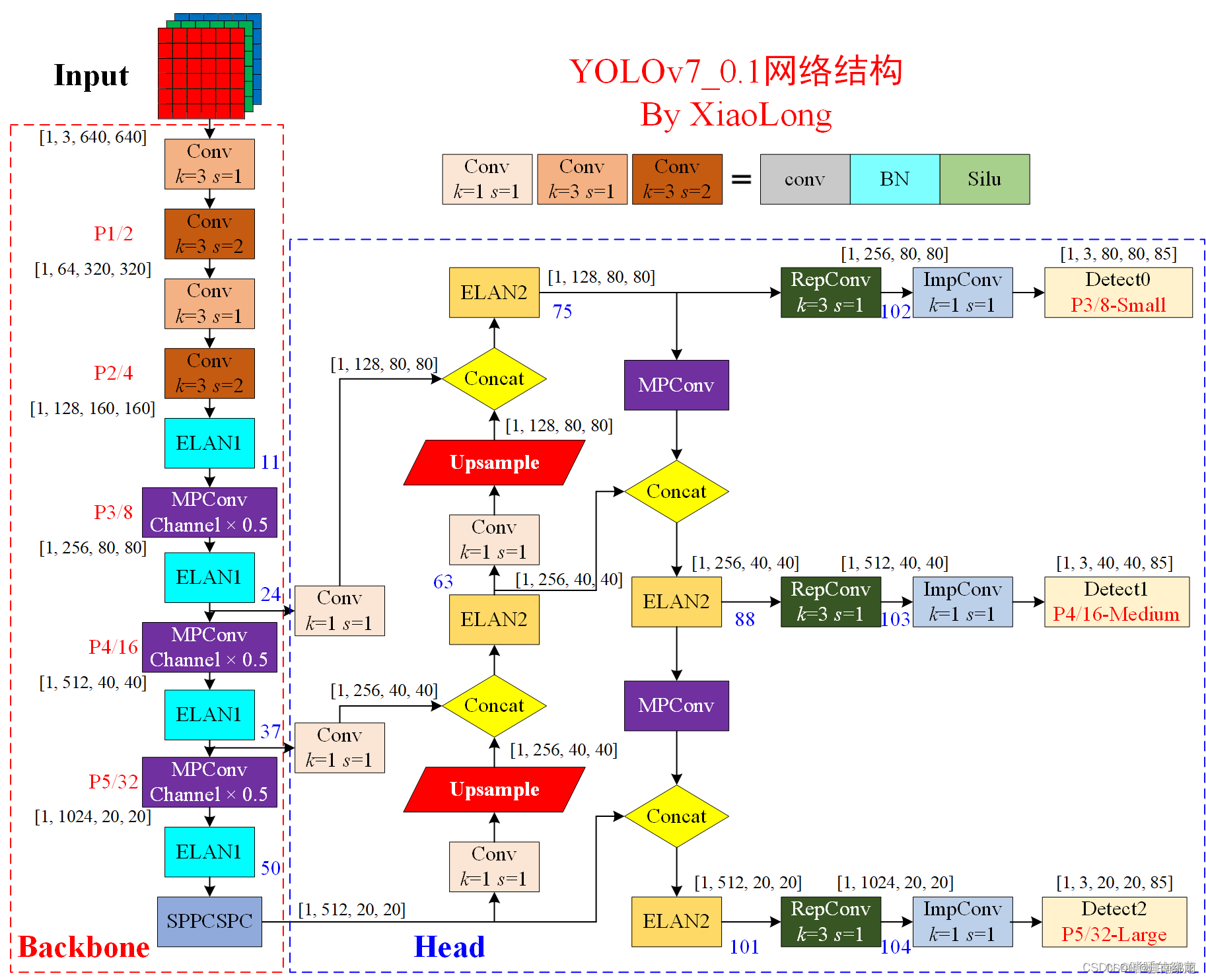
二:ELAN模块

yolov7.yaml中的初始化设置 :
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
三:MPConv混合卷积
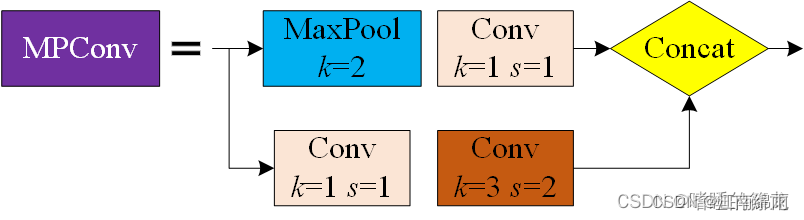
yolov7.yaml中的初始化设置 :
[-1, 1, Conv, [256, 1, 1]], # 11
# MPConv
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
四:SPPCSPC
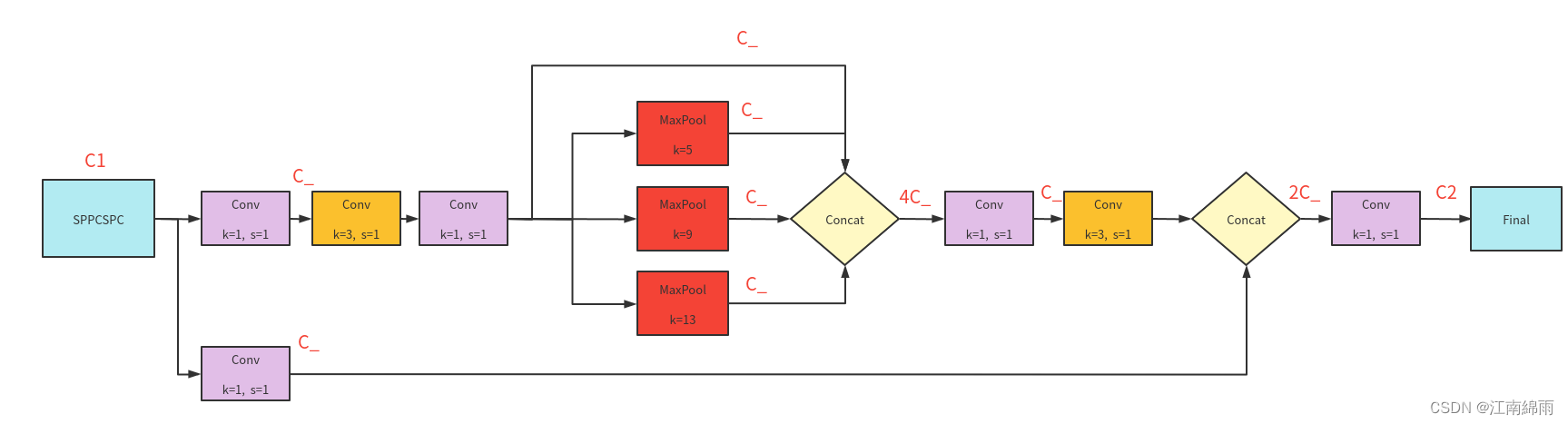
common.py中的对应代码部分:
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))
五:ImpConv隐性知识学习
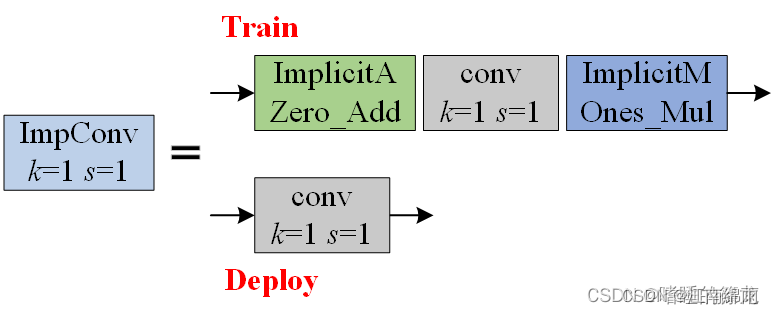 这一部分直接继承自YOLOR中的显隐性知识学习。一般情况下,将神经网络的浅层特征称为显性知识,深层特征称为隐性知识。而YOLOR的作者(同时也是YOLOv7的作者)则直接把神经网络最终观察到的知识称为显性知识,那些观察不到、与观察无关的知识称为隐性知识。也就是无法学习到的东西,先初始化再更新学习。
这一部分直接继承自YOLOR中的显隐性知识学习。一般情况下,将神经网络的浅层特征称为显性知识,深层特征称为隐性知识。而YOLOR的作者(同时也是YOLOv7的作者)则直接把神经网络最终观察到的知识称为显性知识,那些观察不到、与观察无关的知识称为隐性知识。也就是无法学习到的东西,先初始化再更新学习。
在model/common.py文件中,定义了两类隐性知识:ImplicitA和ImplicitM,分别和输入相加、相乘:
- IDetect
def forward(self, x):
x = self.conv_1✖1(implicitA(x))
x = implicitM(x)
- ImplicitA
class ImplicitA(nn.Module):
def __init__(self, channel, mean=0., std=.02):
super(ImplicitA, self).__init__()
self.channel = channel
self.mean = mean
self.std = std
self.implicit = nn.Parameter(torch.zeros(1, channel, 1, 1))
nn.init.normal_(self.implicit, mean=self.mean, std=self.std)
def forward(self, x):
return self.implicit + x
- ImplicitM
class ImplicitM(nn.Module):
def __init__(self, channel, mean=0., std=.02):
super(ImplicitM, self).__init__()
self.channel = channel
self.mean = mean
self.std = std
self.implicit = nn.Parameter(torch.ones(1, channel, 1, 1))
nn.init.normal_(self.implicit, mean=self.mean, std=self.std)
def forward(self, x):
return self.implicit * x
六:Fine-to-Coarse Auxility Loss
 YOLO_v7-W6中才有辅助损失模块。由上图源码可见,采样了P3~P6和C3~C6,并且分别分配targets。值得注意的是,对于辅助特征层上的targets设定是上、下、左、右四个cell都算正样本,同时计算损失时给0.25的权重。
YOLO_v7-W6中才有辅助损失模块。由上图源码可见,采样了P3~P6和C3~C6,并且分别分配targets。值得注意的是,对于辅助特征层上的targets设定是上、下、左、右四个cell都算正样本,同时计算损失时给0.25的权重。
笔者也是刚才读了第二遍源码才发现,每一层的损失都加了不同的权重,对于大分辨率的特征层权重最大4,而分辨率最小的只有权重0.02,我猜测是想让检测网络更关注小物体。
至此我对YOLO_v7中重点流程与细节进行了深度讲解,希望对大家有所帮助,有不懂的地方或者建议,欢迎大家在下方留言评论。
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!
















 722
722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









