







机器学习入门2——端到端的机器学习
1.数据查找
学习机器学习时,最好使用真实数据,而不是人工数据集。幸运的是,有上千个开源数据集可以进行选择,涵盖多个领域。以下是一些可以查找的数据的地方:
流行的开源数据仓库:
UC Irvine Machine Learning Repository
Kaggle datasets
Amazon’s AWS datasets
准入口(提供开源数据列表)
http://dataportals.org/
http://opendatamonitor.eu/
http://quandl.com/
其它列出流行开源数据仓库的网页:
Wikipedia’s list of Machine Learning datasets
Quora.com question
Datasets subreddit
本章,我们选择的是 StatLib 的加州房产价格数据集。
2.划定问题
问老板的第一个问题应该是商业目标是什么?建立模型可能不是最终目标。公司要如何使用、并从模型受益?这非常重要,因为它决定了如何划定问题,要选择什么算法,评估模型性能的指标是什么,要花多少精力进行微调。
老板告诉你你的模型的输出(一个区的房价中位数)会传给另一个机器学习系统,也有其它信号会传入后面的系统。这一整套系统可以确定某个区进行投资值不值。确定值不值得投资非常重要,它直接影响利润。

这是一个典型的监督学习任务,因为你要使用的是有标签的训练样本(每个实例都有预定的产出,即街区的房价中位数)。并且,这是一个典型的回归任务,因为你要预测一个值。讲的更细些,这是一个多变量回归问题,因为系统要使用多个变量进行预测(要使用街区的人口,收入中位数等等)。
3.选择性能指标
回归问题的典型指标是均方根误差(RMSE)。均方根误差测量的是系统预测误差的标准差。例如,RMSE 等于 50000,意味着,68% 的系统预测值位于实际值的 50000 美元以内,95% 的预测值位于实际值的 100000 美元以内(一个特征通常都符合高斯分布,即满足 “68-95-99.7”规则:大约 68% 的值落在1σ内,95% 的值落在2σ内,99.7% 的值落在3σ内,这里的σ等于 50000)。
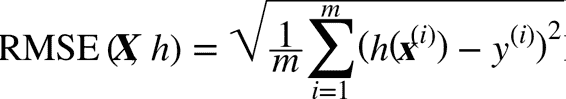
虽然大多数时候 RMSE 是回归任务可靠的性能指标,在有些情况下,你可能需要另外的函数。例如,假设存在许多异常的街区。此时,你可能需要使用平均绝对误差(Mean Absolute Error,也称作平均绝对偏差)。
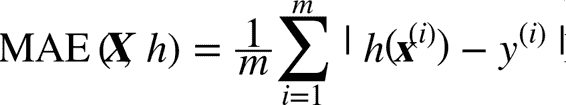
RMSE 和 MAE 都是测量预测值和目标值两个向量距离的方法。有多种测量距离的方法,或范数:
1.计算对应欧几里得范数的平方和的根(RMSE):这个距离介绍过。它也称作ℓ2范数,标记为||·||₂(或只是||·||)。
2.计算对应于ℓ1(标记为||·||₁)范数的绝对值和(MAE)。有时,也称其为曼哈顿范数,因为它测量了城市中的两点,沿着矩形的边行走的距离。
3.更一般的,包含n个元素的向量v的ℓk范数(K 阶闵氏范数),定义成
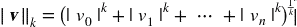
ℓ0(汉明范数)只显示了这个向量的基数(即,非零元素的个数),ℓ∞(切比雪夫范数)是向量中最大的绝对值。
4.范数的指数越高,就越关注大的值而忽略小的值。这就是为什么 RMSE 比 MAE 对异常值更敏感。但是当异常值是指数分布的(类似正态曲线),RMSE 就会表现很好。
四、完整代码链接
https://github.com/ageron/handson-ml















 9379
9379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









