







EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction
贡献:
1、我们提出了一种新的多尺度线性注意模块,用于高效的高分辨率密集预测。在保持良好的硬件性能的同时,实现了全局接受域和多尺度的学习。据我们所知,我们的工作是首次证明线性注意对于高分辨率密集预测的有效性
2、基于所提出的多尺度线性注意力模块,我们设计了一种名为EfficientViT的高分辨率视觉模型。
3、与之前的SOTA模型相比,我们的模型在不同硬件平台(移动CPU、边缘GPU和云GPU)上的语义分割、超分辨率、分割任何东西以及ImageNet分类上都有显著的加速效果。
1、介绍
具体而言:
具体来说,我们建议用轻量级 ReLU 线性注意力 [12] 代替低效的 softmax 注意力,以获得全局感受野。通过利用矩阵乘法的关联属性,ReLU 线性注意力可以将计算复杂度从二次降低到线性,同时保留功能。此外,它避免了像softmax这样的硬件效率低下的操作,使其更适合硬件部署。
然而,由于缺乏局部信息提取和多尺度学习能力,单独的ReLU线性注意力能力有限。因此,我们提出通过卷积增强ReLU线性注意力,并引入多尺度线性注意力模块来解决ReLU线性注意力的容量限制。
具体来说,我们使用小内核卷积聚合附近的令牌以生成多尺度令牌。我们对多尺度 token 进行 ReLU 线性注意力(图 2),将全局感受野与多尺度学习结合起来。我们还将深度卷积插入到 FFN 层中,以进一步提高局部特征提取能力。
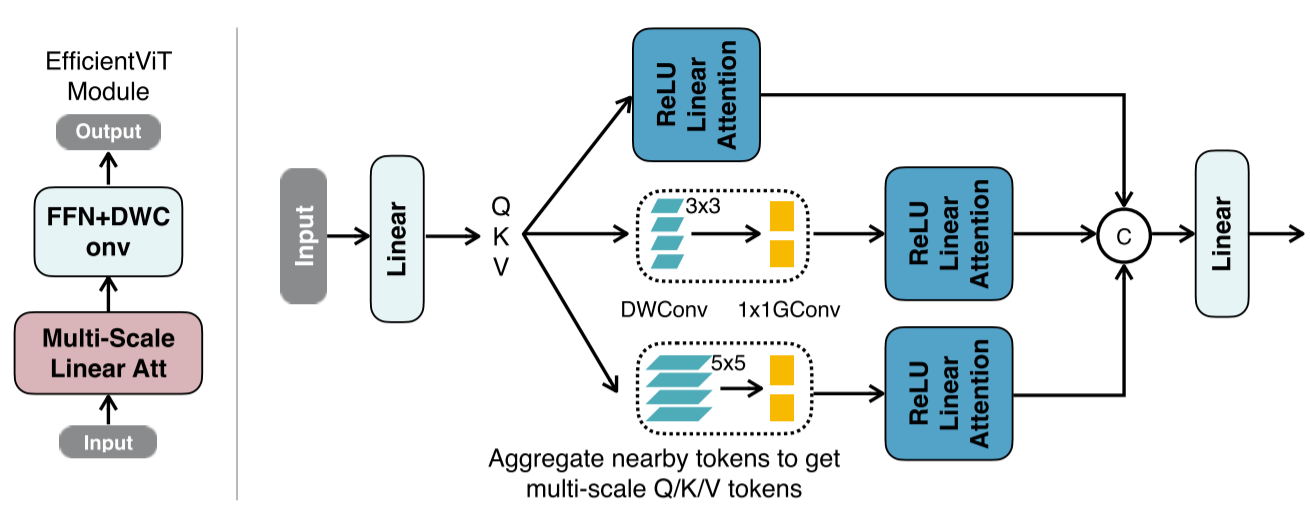
图2:EfficientViT的构建块(左)和多尺度线性注意(右)。左:EfficientViT的构建模块包括一个多尺度线性注意模块和一个深度卷积的FFN (FFN+DWConv)。多尺度线性注意捕获上下文信息,而FFN+DWConv捕获局部信息。右:在通过线性投影层获得Q/K/V tokens之后,我们通过轻量级的小内核卷积聚合附近的tokens,从而生成多尺度的tokens。将ReLU线性注意应用于多尺度tokens,将输出串接并反馈到最终的线性投影层进行特征融合。
2、方法
本节首先介绍多尺度线性注意模块。不同于以往的工作,我们的多尺度线性注意同时实现全局接受域和多尺度的学习,只有硬件有效的操作。然后,基于多尺度线性注意,我们提出了一种新的视觉变压器模型,名为EfficientViT,用于高分辨率密集预测。
2.1 多尺度线性注意模块
我们的多尺度线性注意平衡了高效高分辨率密集预测的两个关键方面,即性能和效率。具体来说,从性能的角度来看,全局接受域和多尺度的学习是必不可少的。以往的SOTA高分辨率密集预测模型通过启用这些特征提供了较强的性能,但未能提供良好的效率。我们的模块解决了这个问题,用轻微的容量损失换取显著的效率改进。
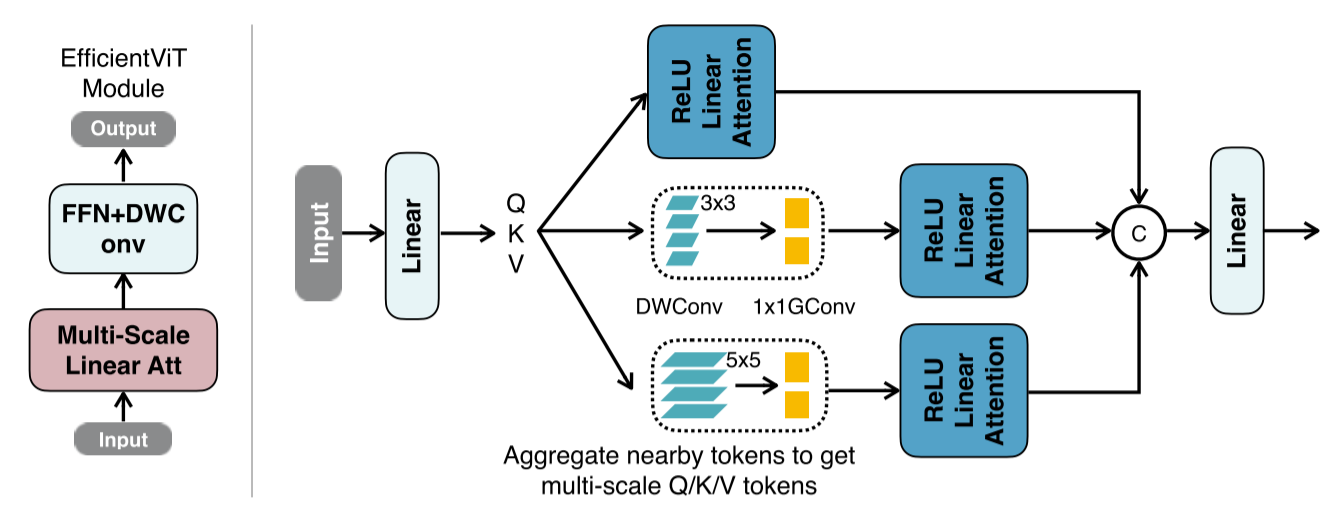
图2(右)展示了所提出的多尺度线性注意模块。特别地,我们建议使用ReLU线性注意力[12]来代替沉重的softmax注意力[8],使全局接受域成为可能。虽然ReLU线性注意[12]等线性注意模块[14,15,16,17]已经在其他领域进行了探索,但尚未成功应用于高分辨率密集预测。据我们所知,ImageNet Top1 Acc cityapes mIoU ADE20K mIoU ImageNet Top1 Acc EfficientViT是第一个证明ReLU线性注意在高分辨率密集预测中的有效性的工作。此外,我们的工作引入了新颖的设计,以解决其容量限制。
2.1.1 启用全局接收域与ReLU线性注意
给定输入x∈RN×f, softmax注意的广义形式可以写成:
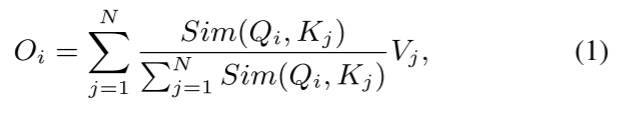
其中Q = xWQ, K = xWK, V = xWV, WQ/WK/WV∈Rf×d是可学习的线性投影矩阵。Oi表示矩阵o的第i行。Sim(·,·)为相似函数。当使用相似函数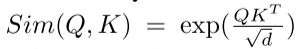 时,Eq.(1)成为原来的softmax注意[8]。
时,Eq.(1)成为原来的softmax注意[8]。
除了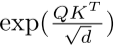 外,我们还可以使用其他相似函数。在这项工作中,我们使用ReLU线性注意[12]来实现全局接受域和线性计算复杂度。在ReLU线性注意中,相似函数定义为:
外,我们还可以使用其他相似函数。在这项工作中,我们使用ReLU线性注意[12]来实现全局接受域和线性计算复杂度。在ReLU线性注意中,相似函数定义为:
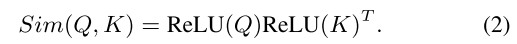
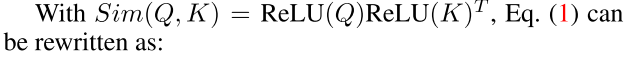
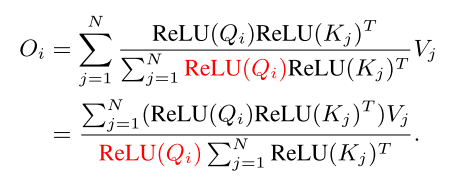
然后,我们可以利用矩阵乘法的结合性,在不改变其功能的情况下,将计算复杂度和内存占用从二次型降低到线性型:

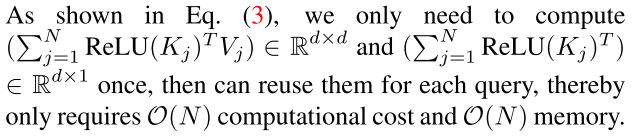
2.1.2 解决ReLU线性注意力的局限性。
虽然ReLU线性注意在计算复杂度和硬件延迟方面优于softmax注意,但ReLU线性注意存在局限性。图3显示了softmax注意和ReLU线性注意的注意特征图。由于缺乏非线性相似函数,ReLU线性注意力不能生成集中注意力特征图,使得其对局部信息的捕捉能力较弱。

图3:Softmax注意力vs. ReLU线性注意力与softmax注意不同,ReLU线性注意由于缺乏非线性相似函数而不能产生显著的注意分布。因此,它的局部信息提取能力弱于softmax的注意力。
为了缓解其局限性,我们提出用卷积来增强ReLU的线性注意力。具体来说,我们在每个FFN层中插入一个深度卷积。图2(左)展示了最终构建块的概述,其中ReLU线性注意力捕获上下文信息,而FFN+DWConv捕获本地信息。
此外,我们还提出将附近的Q/K/V tokens信息进行聚合,得到多尺度的tokens,以增强ReLU线性注意的多尺度学习能力。这个信息聚合过程是独立于每个头部的Q、K和V的。我们只使用小核深度可分卷积[18]进行信息聚合,避免了影响硬件效率。在实际实现中,独立执行这些聚合操作在GPU上的效率是非常低的。因此,我们利用群卷积来减少总操作的次数。其中,将所有DWConvs融合为单个DWConv,将所有1x1卷积组合为单个1x1群卷积(右图2),其中分组数为3 × #头,每组信道数为d。获取多尺度tokens后,对其进行线性相关处理,提取多尺度全局特征。最后,我们沿着头部的尺寸将特征连接起来,并将它们馈送到最后的线性投影层以融合特征。
2.2 EfficientViT架构
基于所提出的多尺度线性注意模块,我们构建了一组新的视觉变压器模型。核心构建块(标记为“EfficientViT模块”)如图2(左)所示。图5演示了EfficientViT的宏架构。我们采用标准的骨干-头/编码器-解码器架构设计。
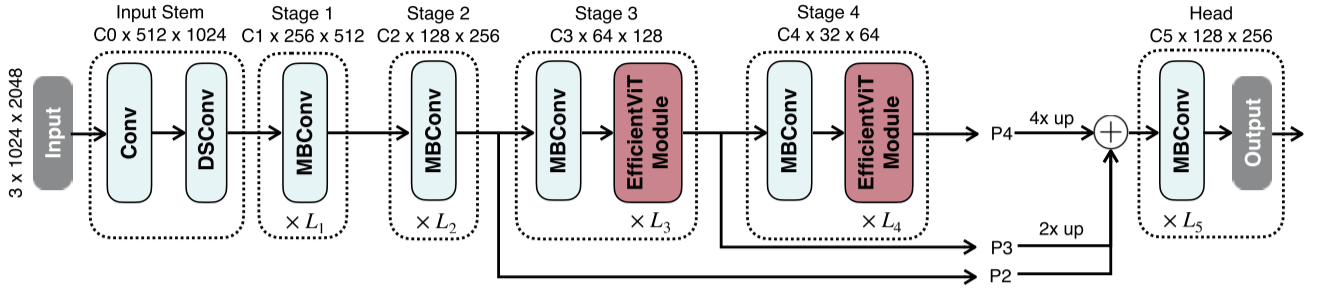
图5:efficient entvit的宏观架构。我们采用标准的主干头/编码器-解码器设计。我们在主干网的阶段3和4中插入了EfficientViT模块。按照通常的做法,我们将最后三个阶段(P2、P3和P4)的特性添加到头部。为了简单和高效,我们使用加法来融合这些功能。我们采用了一个简单的磁头设计,由几个MBConv块和输出层组成。
2.2.1 骨干
EfficientViT的主干也遵循标准设计,由输入干和四个阶段组成,feature map大小逐渐减小,通道数逐渐增加。我们在阶段3和4中插入Effi cientViT模块。对于下采样,我们使用步幅为2的MBConv。
2.2.2 头部
P2、P3和P4表示阶段2、3和4的输出,形成了一个特征特征图金字塔。为了简单和高效,我们使用1x1卷积和标准上采样操作(如双线性/双三次上采样)来匹配它们的空间和通道大小,并通过加法融合它们。由于我们的主干已经具有很强的上下文信息提取能力,我们采用了一个简单的头设计,包括几个MBConv块和输出层(即预测层和上样本层)。在实验中,我们经验地发现这种简单的头设计足以实现SOTA的性能。
在相同的宏观体系结构下,我们设计了一系列不同尺寸的模型,以满足各种效率约束。我们将这些模型分别命名为EfficientViTB0、efficientvitb - b1、efficientvitb - b2和efficientvitb - b3。此外,我们为云平台设计了efficientvt - l系列。这些模型的详细配置在我们的GitHub官方仓库1中提供。
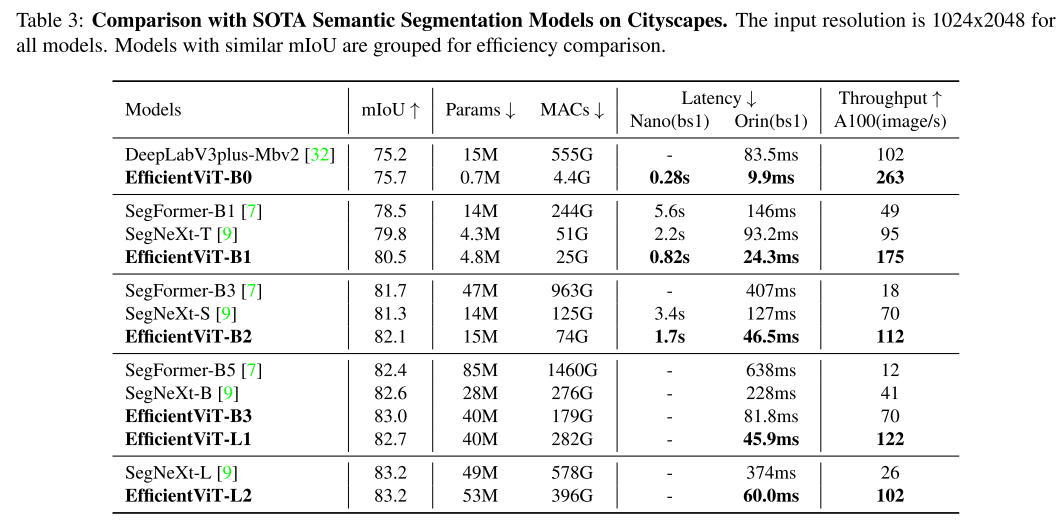
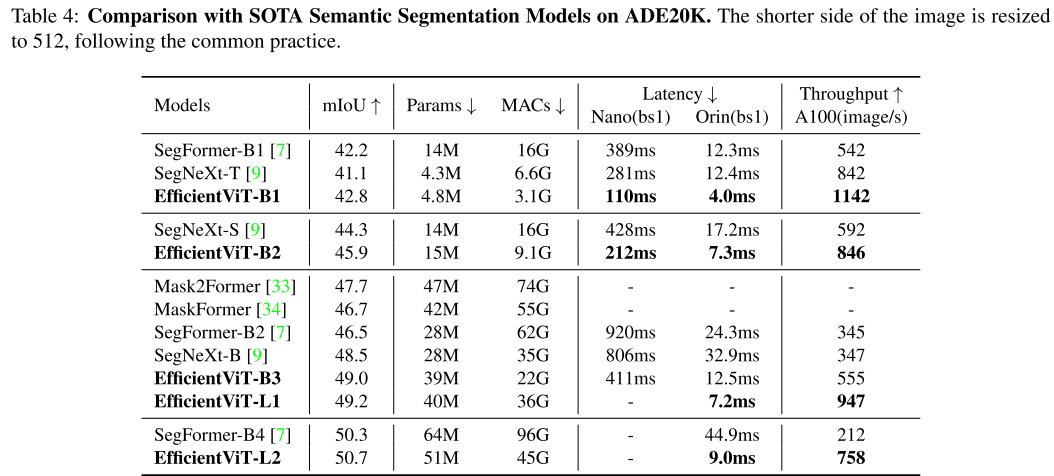
3、实验
















 3059
3059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











