







机器学习基本概念:
基础知识:
- 输入空间(Input Space):将输入的所有取值的集合称作输入空间
- 输出空间(Output Space):将输出的所有取值的集合称作输出空间
- 输入空间和输出空间可以是有限元素的集合,也可以是整个欧氏空间
- 输入空间和输出空间可以是连续值集合,也可以是离散值集合
- 输入空间和输出空间可以是同一个空间,也可以是不同的空间
- 通常输出空间比输入空间小
- 输入空间和输出空间可以是有限元素的集合,也可以是整个欧氏空间
- 特征(Feature):即属性。每个输入实例的各个组成部分(属性)称作原始特征,基于原始特征还可以阔震出更多的衍生特征
- 特征向量(Feature Vector):有多个特征组成的集合,称作特征向量
- 特征空间(Feature Space):将特征向量存在的空间称作特征空间
- 特征空间中每一维都对应了一个特征(属性)
- 特征空间可以和输入空间相同,也可以不同
- 需将实例从输入空间映射到特征空间
- 模型实际上是定义于特征空间之上的
- 假设空间(Hypothesis Space):由输入空间到输出空间的映射的集合,称作假设空间
- 监督学习的目的在于学习一个由输入到输出的映射,这一映射由模型来表示。换句话说,学习的目的就在于找到最好的这样的模型。模型属于由输入空间到输出空间的映射集合,这个集合就是假设空间。假设空间的确定意味着学习范围的的确定。——李航《统计学习方法》
- 假设空间指的是问题的所有假设组成的空间,我们可以把学习过程看作是在假设空间中搜索的过程,搜索目标是寻找于训练集“匹配”的假设。——周志华《机器学习》
- 针对每一种可能的输入,都能找到一个对应的映射,对应了输出空间中某个输出
- 假设空间H中假设的个数为:1为特殊的全空假设
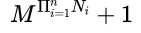
机器学习方法三要素
机器学习方法通常都是由模型、策略和算法三部分构成:方法=模型+策略+算法
-
模型:输入空间到输出空间的映射关系,学习过程即为从假设空间中搜索适合当前数据的假设。分析当前需要解决的问题,选择合适的模型。

-
策略:从假设空间众多的假设中选择到最优的模型的学习标准或规则
- 要从假设空间中选择一个最适合的模型出来,需要解决以下问题:
- 评估某个模型对单个训练样本的结果
- 评估某个模型对训练集的整体的效果
- 评估某个模型对包括训练集、预测集在内的所有数据的整体效果
- 定义几个指标用来衡量上述问题:
- 损失函数:0-1损失函数、平方损失函数、绝对损失函数、对数损失函数
- 风险函数:经验函数、期望函数、结构函数
- 要从假设空间中选择一个最适合的模型出来,需要解决以下问题:
-
算法:学习模型的具体的计算方法,通常是求解最优化问题
-
损失函数(Loss Function):用来衡量预测结果和真实结果之间的差距,其值越小,代表预测结果和真实结果越一致。通常是一个非负实值函数。通过各种方式缩小损失函数的过程被称作优化。损失函数记作 L(Y,f(x))。
-
0-1损失函数(0-1LF):预测值和真实值精确相等则“没有损失”为0,否则意味着“完全损失”为1;预测值和实际值精确相等有些过于严格,可以采用两者的差小于某个阈值的方式。
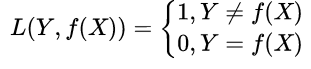
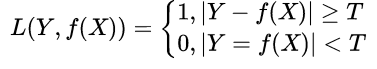
-
绝对值损失函数(Absolute LF):预测结果与真实结果差的绝对值。简单易懂,但是计算不方便
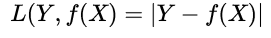
-
平方损失函数(Quadratic LF):预测结果与真实结果差的平方
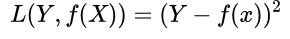
- 平方损失函数的优势:
- 每个样本的误差都是正的,累加不会被抵消
- 平方对于大误差的惩罚小于小误差
- 数学计算简单友好,导数为一次函数
- 平方损失函数的优势:
-
对数损失函数(Logarithmic LF):或者对数似然损失函数(log-likehood loss function):对数函数具有单调性,在求解最优化问题时,结果与原始目标一致。可将乘法转化为加法,简化计算:
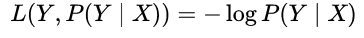
-
指数损失函数(Exponential LF):单调性、非负性的优良性质,使得越接近正确结果误差越小
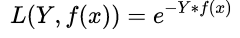
-
折叶损失函数(Hinge LF):也称铰链损失,对于判定边界附近的点的惩罚力度较高,常见于SVM
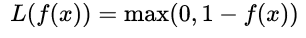

-
-
不同的损失函数有不同的特点,适用于不同的场景:
- 0-1:理想状况模型
- Log:逻辑回归、交叉熵
- Squared:线性回归
- Exponential:AdaBoosting
- Hinge:SVM、soft margin
-
经验风险(Empirical Risk):损失函数度量了单个样本的预测结果,要想衡量整个训练集的预测值与真实值的差异,将整个训练集所有记录均进行一次预测,求取损失函数,将所有值累加,即为经验风险。经验风险越小说明模型 f(x) 对训练集的拟合程度越好。
- 公式为:
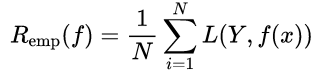
- 公式为:
-
风险函数(Risk Function):又称损失期望、期望风险。所有数据集(包括训练集和预测集,遵循联合分布 P(X,Y))的损失函数的期望值。
- 公式为:
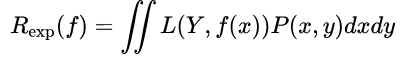
- 经验风险vs期望风险:
- 期望风险是模型对全局(所有数据集)的效果;经验风险是模型对局部(训练集)的效果
- 期望风险往往是无法计算,即联合分布P(X,Y)通常是未知的;经验风险可以计算
- 当训练集足够大时,经验风险可以替代期望风险,即局部最优替代全局最优
- 经验风险的问题
- 在样本较小时,仅关注经验风险,很容易导致过拟合
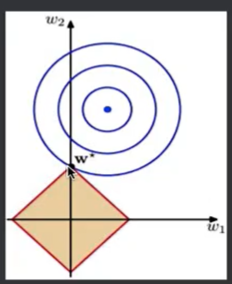
- 结构风险(Structural Risk):在经验风险的基础上,增加一个正则化项(Regularizer)或者叫惩罚项(Penalty Term)公式为
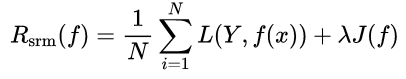
其中为一个大于0的系数。J(f)表示模型f(x)的复杂度。
- 公式为:
-
结构风险VS经验风险:
- 经验风险越小,模型决策函数越复杂,其中包含的参数越多
- 当经验函数小到一定程度就出现了过拟合现象
- 防止过拟合现象的方式,就要降低决策函数的复杂度,让惩罚项J(f)最小化
- 需要同时保证经验风险函数和模型决策函数的复杂度都达到最小化
- 把两个式子融合成一个式子得到结构风险函数然后对这个结构风险函数进行最小化
-
正则化项(Regularizer):即惩罚函数,该项对模型向量进行惩罚,从而避免过拟合问题。正则化方法会自动削弱不重要的特征变量,自动从许多的特征变量中“提取”重要的特征变量,减少特征变量的数量级。
-
范数:规范化函数
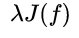
有多种选择,一般地,它是模型复杂程度的单调递增函数,模型越复杂,该函数的值就越大,惩罚力度相应的越大。常用模型的参数向量的范数。常用的有零范数、一范数、二范数、迹范数、Frobenius范数和核范数等。 -
范数(Norm):是数学中的一个基本概念,他定义在赋范线性空间中,满足1非负性;2齐次性;3三角不等式等条件的量。常用来度量向量的长度或者大小。
-
L0范数:非零的元素的个数。使用L0范数,期望参数大部分为0,既让参数是稀疏的。
-
L1范数:(绝对值)各个元素的绝对值之和,使用L1范数,会让参数稀疏。L1也被称为系数规则算子。
-
L2范数:(模)各元素的平方和求平方根,使得每个元素都很小,但不会等于零,而是接近零。
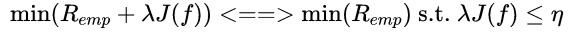
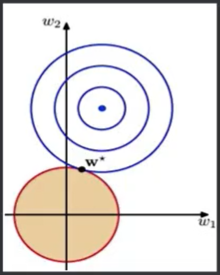
-















 685
685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









