







一、引言
论文: DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR
作者: IDEA
代码: DAB-DETR
注意: 该算法是对DETR的改进,在学习该算法前,建议掌握多头注意力、Sinusoidal位置编码、DETR等相关知识。
特点: 将Decoder中Query的角色解耦为图像内容和物体位置,明确了DETR收敛慢的原因在于Query的物体位置部分没有提供目标位置的先验;提出输入位置先验并逐层微调的策略提升模型收敛速度,提出注意力调制方案使注意力可以适应不同形状的目标,提出缩小Sinusoidal位置编码时的Temperature使注意力时Query更加关注局部区域。
二、动机
2.1 对DETR收敛速度慢的原因进行了分析,将问题定位在了Decoder的Query部分。

由上图可知,在DETR中,编码器的自注意力模块和解码器的交叉注意力模块的主要差别在于Query的不同。自注意力模块的Query与Key一致,均为图像特征和位置编码的和,交叉注意力模块的Query与Key不一致,Key为解码器输出的图像特征和位置编码的和,而Query是解码器嵌入(初始化为0)和可学习查询(由nn.Embedding初始化)的和。
2.2 将Decoder中Query的角色解耦为图像内容和物体位置,将问题进一步定位在了Query的物体位置部分。
解码器嵌入被初始化为0,后续每层Decoder的输出都会作为新的解码器嵌入喂入下一层Decoder。在经过第一层映射后,解码器嵌入已经处于图像特征所在的空间内了,所以解码器嵌入所表达的信息为图像内容。则可学习查询就应该与物体位置相对应。
对剩余几个Decoder层来说,解码器嵌入已经处于图像特征所在的空间,因此与编码器的自注意力模块相比,表达物体位置信息的可学习查询成了唯一的不同之处,也就成了导致DETR收敛慢的罪魁祸首。
2.3 给出表达目标位置信息的可学习查询拖慢DETR的两个可能的原因,并将问题确定为可学习查询没有表达物体位置信息。
作者给出的两个可能的原因为(1) 可学习查询的参数学习难度高、(2) 可学习查询没有表达物体位置信息。
作者通过实验排除了第一种可能。如果是可学习查询的参数本身难以被学习,那么可以不让它学,而是直接初始化为已经学好的参数并固定,然后让模型学习其它模块的参数。下图为初始化并固定前后的训练曲线:

可见,初始化并固定的操作只稍稍提升了前25个epoch的收敛速度,后面的收敛速度基本一致。所以原因(1)被排除。
之后作者转向分析原因(2)。作者认为作为对位置信息的表达,可学习查询的作用应该是使模型关注某些特定目标区域,从而过滤无关区域。因此,作者可视化了Decoder中Query部分的可学习查询与Decoder中Key部分的位置嵌入间的注意力权重:

从上图能够看出,DETR的可学习查询没有表现出很优秀的定位能力,主要有两个不好的表现:多模式(multiple modes)和注意力权重几乎一致(nearly uniform attention weights)。简单来说,多模式就是说同一个查询所产生的关注点不只一个,如上面两个子图所示;注意力权重几乎一致就是说希望被关注的或不希望被关注的区域面积过大,没有聚焦,如下面两个子图所示。因此,可以确定主要问题出在可学习查询没有表达物体位置信息上。
2.4 指出提供位置先验能够避免这两大问题,但现有方法忽略了目标的尺寸信息,并提出宽高可调的多头交叉注意力机制(Width & Height Modulated Multi-Head Cross-Attention)。
Conditional DETR提出使用能够明确表达位置信息的可学习查询(或称位置先验)来进行训练,于是产生下图(b)中这种类高斯的注意力权重图:

但是,图(b)的结果也有缺点,那就是每个查询所关注的区域虽然个数都是一个并且位置不同,但是其关注区域的大小基本是一致的。对于目标检测来说,同一个图上不同目标的尺寸应该是不同的,例如车是横着的,人是竖着的。
为了解决这个问题,作者在引入位置信息 ( x , y ) (x,y) (x,y)的基础上,又引入了宽高信息 ( w , h ) (w,h) (w,h),并提出可以对宽高进行调制的交叉注意力策略。效果上图(c)所示,每个查询所关注的区域位置、大小均有差异。
三、框架
DAB-DETR与DETR的主要差别集中在Decoder部分,DAB-DETR的Decoder的详细结构图如下:

DAB-DETR与DETR的差异简图如下:

可见,DAB-DETR与DETR的主要差别在于可学习查询的定义和是否逐层更新、自注意力中Query和Key用于表达目标位置信息的部分、交叉注意力的Query和Key以及是否尺寸调制。
3.1 可学习查询的定义和是否逐层更新
可学习查询作为对目标位置信息的表达,需要给出位置先验,DAB-DETR提供的是中心坐标 ( x , y ) (x,y) (x,y)。为了进行尺寸调制,DAB-DETR还引入了宽高 ( w , h ) (w,h) (w,h)。
DAB-DETR先用nn.Embedding初始化了300个可学习的 ( x , y , w , h ) (x,y,w,h) (x,y,w,h),Deformable DETR的查询个数也是300,而不是DETR中的100。为了避免测试时得到的 ( x , y ) (x,y) (x,y)集中出现在训练集的目标位置,或者说提升泛化能力,DAB-DETR用uniform(0, 1)将 ( x , y ) (x,y) (x,y)调整成了均匀分布,并消除了梯度(注意 ( w , h ) (w,h) (w,h)的梯度没有消除)。之后由Width & Height Modulated Multi-Head Cross-Attention的输出预测偏移量 ( Δ x , Δ y , Δ w , Δ h ) (\Delta x,\Delta y,\Delta w,\Delta h) (Δx,Δy,Δw,Δh),来逐层修正 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)。
从详细结构图可以看出,Width & Height Modulated Multi-Head Cross-Attention的输出之后跟了一个MLP才得到偏移量 ( Δ x , Δ y , Δ w , Δ h ) (\Delta x,\Delta y,\Delta w,\Delta h) (Δx,Δy,Δw,Δh),加在输入的 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)上,实现锚框中心坐标和宽高的更新。这个MLP是共享的,即每层输出后都跟同一个MLP,它的作用是将输出从D维降至4维,即MLP: R D → R 4 \mathbb{R}^{D}\rightarrow\mathbb{R}^4 RD→R4。
3.2 自注意力中Query和Key用于表达目标位置信息的部分
在DETR中,可学习查询与解码器嵌入的初始维度都是D维。在DAB-DETR中,输入变成了可学习锚框,即 ( x , y , w , h ) (x,y,w,h) (x,y,w,h),维度为4,没办法与D维的解码器嵌入相加。于是作者增加了两步操作,位置编码和MLP映射,定义如下:

其中, A q = ( x q , y q , w q , h q ) A_q=(x_q,y_q,w_q,h_q) Aq=(xq,yq,wq,hq)表示第 q q q个锚框; P q P_q Pq表示第 q q q个锚框经转换后得到的可学习查询,即自注意力中Query和Key用于表达目标位置信息的部分,维度为D; P E ( A q ) PE(A_q) PE(Aq)定义如下:

其中, P E ( ⋅ ) : R → R D / 2 PE(\cdot):\mathbb{R}\rightarrow\mathbb{R}^{D/2} PE(⋅):R→RD/2,表示Sinusoidal位置编码,即详细结构图中的归一化 ∼ ◯ + \textcircled{\sim}+ ∼◯+Anchor Sine Encodeings,将一个数映射到D/2维;Cat表示拼接操作,4个数的位置编码拼接到一起就是2D维;所以这里的MLP要将2D维映射到D维上,即MLP: R 2 D → R D \mathbb{R}^{2D}\rightarrow\mathbb{R}^{D} R2D→RD。
于是,我们可以得出Decoder中自注意力的Query、Key、Value,定义如下:

其中, C q C_q Cq是与可学习查询 P q P_q Pq对应的解码器嵌入,用于表达图像内容信息的部分,维度为D。
自注意力模块的输出与解码器嵌入相加再归一化,即详细结构图中的Add & \& &Norm操作,仍然被定义为 C q C_q Cq,之后喂入交叉注意力模块。
3.3 交叉注意力的Query和Key以及是否尺寸调制
与DETR中一样,DAB-DETR中交叉注意力的Value也是编码器输出的图像特征,定义为 F x , y F_{x,y} Fx,y。于是有 V x , y = F x , y V_{x,y}=F_{x,y} Vx,y=Fx,y。
Key部分虽然也是编码器输出的图像特征 F x , y F_{x,y} Fx,y和位置编码(仅编码 ( x , y ) (x,y) (x,y),定义为 P E ( x , y ) PE(x,y) PE(x,y)),但是DETR是将图像特征和位置编码相加,DAB-DETR却是将两者拼接,即详细结构图中的 c ◯ \textcircled{\text{c}} c◯。这样做的好处是可以通过多头注意力机制使注意力的计算解耦,简单来说,就是Query的图像特征与Key的图像特征计算注意力,Query的位置编码与Key的位置编码计算注意力。于是有 K x , y = C a t ( F x , y , P E ( x , y ) ) K_{x,y}=Cat(F_{x,y},PE(x,y)) Kx,y=Cat(Fx,y,PE(x,y))。
Query部分比较复杂, 它包括自注意力模块的输出,即用于表达图像内容信息的维度为D的 C q C_q Cq、与中心坐标 ( x , y ) (x,y) (x,y)对应的D维位置编码 P E ( x q , y q ) PE(x_q,y_q) PE(xq,yq)、 C q C_q Cq经MLP: R D → R D \mathbb{R}^{D}\rightarrow\mathbb{R}^{D} RD→RD得到的权重向量 MLP c s q ( C q ) \text{MLP}^{csq}(C_q) MLPcsq(Cq)。权重向量用于加权位置编码,采用对应元素相乘的方式。然后 C q C_q Cq与加权后的 P E ( x q , y q ) PE(x_q,y_q) PE(xq,yq)拼接即可得到交叉注意力模块的Query。于是有 Q q = C a t ( C q , MLP c s q ( C q ) ⋅ P E ( x q , y q ) ) Q_q=Cat(C_q,\text{MLP}^{csq}(C_q)\cdot PE(x_q,y_q)) Qq=Cat(Cq,MLPcsq(Cq)⋅PE(xq,yq))。
总结起来,交叉注意模块的Query、Key、Value分别如下:
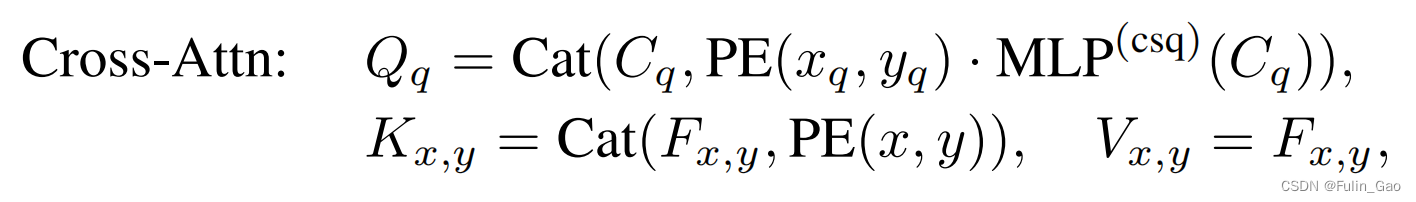
其中,Query Q q Q_q Qq来自Decoder,Key K x , y K_{x,y} Kx,y和Value V x , y V_{x,y} Vx,y来自Encoder。
此外,在交叉注意力模块DAB-DETR还引入了尺寸调制功能。回顾注意力计算公式:

可知,Value前的注意力权重是Query和Key的点积,再除以token长度 d k d_k dk。因为表达目标位置信息和图像内容信息的部分是拼接起来的,所以多头交叉注意力的权重是位置与位置,内容与内容相互计算的。所以,目标位置部分对应的注意力权重应该是两个坐标的点积和,计算公式如下:

其中 ( x , y ) (x,y) (x,y)为Key中的坐标, ( x r e f , y r e f ) (x_{ref},y_{ref}) (xref,yref)是Query中的坐标(其实当成前面 A q A_q Aq中的 ( x q , y q ) (x_q,y_q) (xq,yq)就行),D是 P E ( x , y ) PE(x,y) PE(x,y)的维度。
尺寸调制则是将上述公式变为了如下公式:

其中, ( w q , h q ) (w_q,h_q) (wq,hq)就是 A q A_q Aq中的宽高, ( w q , r e f , h q , r e f ) (w_{q,ref},h_{q,ref}) (wq,ref,hq,ref)由编码器嵌入 C q C_q Cq经MLP和激活函数 σ \sigma σ得到,公式如下:

其实,实际的交叉注意力执行过程并没有被改变,可以看出这里只是多了权重 w q , r e f w q \frac{w_{q,ref}}{w_{q}} wqwq,ref和 h q , r e f h q \frac{h_{q,ref}}{h_{q}} hqhq,ref。它与权重向量 MLP c s q ( C q ) \text{MLP}^{csq}(C_q) MLPcsq(Cq)都是乘在 P E ( x q , y q ) PE(x_q,y_q) PE(xq,yq)上的,不过 MLP c s q ( C q ) \text{MLP}^{csq}(C_q) MLPcsq(Cq)是逐元素相乘,而这里的权重只有两个值分别乘上 P E ( x q ) PE(x_q) PE(xq)和 P E ( y q ) PE(y_q) PE(yq)的所有元素。两次加权操作都可以在交叉注意力模块之外完成,然后再执行标准多头交叉注意力即可。
通过调制之后,不同宽高的目标会获得不同尺寸的注意力权重,如下图所示:

3.4 Sinusoidal位置编码中的Temperature
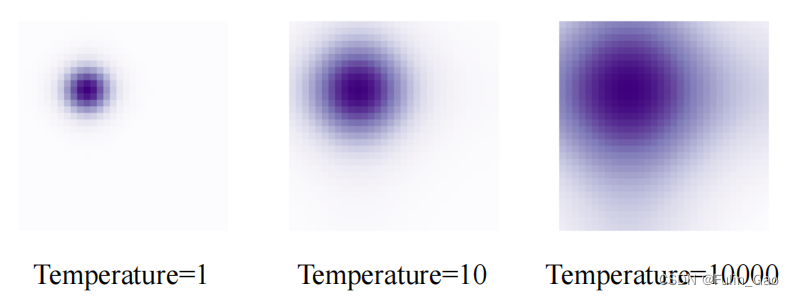
做了归一化 ∼ ◯ \textcircled{\sim} ∼◯后,中心坐标 ( x , y ) (x,y) (x,y)会缩放至 [ 0 , 1 ] [0,1] [0,1]的浮点数,与NLP中使用整数代表每个词(token)在句子中的位置有较大差异。原本Sinusoidal位置编码使用大的Temperature(10000)是为了避免位置编码的重复,现在的值只在 [ 0 , 1 ] [0,1] [0,1]范围内,基本不会出现重复问题。所以作者提出缩小Sinusoidal位置编码时的Temperature(20)。
这样做还有一个好处,就是使注意力更加关注局部区域,如下图所示:
致谢:
本博客仅做记录使用,无任何商业用途,参考内容如下:
找到 DETR 慢收敛的罪魁祸首了!
















 1668
1668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











