







核心思路:直接从图像推理activity会有鸿沟,因此首先推理human part states(即PaSta,形式如<hand,hold,something>),再用part-level的语义去推理动作。首先用一个叫Activity2Vec的模型去提取PaSta特征,再用一个基于PaSta的方法去推理activity。
以往的工作主要利用部件的外观和位置,但很少有研究试图将实例动作划分为离散的part-level语义标记,并将其作为活动概念的基本组件。相比之下,我们的目标是将人体part语义构建为可重用和可转移的知识。
一、构建PaStaNet
1.PaSta定义:将human body分为10个part,头、两条上臂、双手、臀部、两条大腿、双脚。
2.共包括156种activity
3.做实验验证了PaSta覆盖了大部分的activity,且具有learned和transferred的属性。
二、PaStaNet表示activity
1.流程
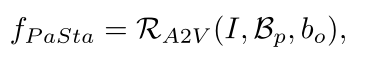
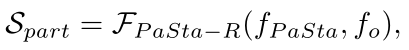
其中I是输入图像,Bp是10个part的box,bo是与人交互的object的box;
fo是object的特征,如果没有交互的object,就用整张图像的ROI pooling特征作为fo,如果有多个object,则分别处理每个human-object对
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1943
1943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









