







PaStaNet: Toward Human Activity Knowledge Engine
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
1.Abstract
现有的基于图像的活动理解方法主要采用直接映射,即从图像到活动概念的映射,由于差距巨大,可能会遇到性能瓶颈。有鉴于此,我们提出了一种新的方法:首先推断人的部件状态,然后根据部件级语义推理出活动。人体部分状态是细粒度的动作语义标记,例(hand、hold、something),它可以组成活动并帮助我们走向人类活动知识引擎。为了充分利用PaSta的力量,我们构建了一个大规模的知识库PaStaNet,其中包含了7M+的PaSta注释。并提出了两个相应的模型:首先,我们设计了一个名为Activity2Vec的模型来提取PaSta特征,该模型旨在作为各种活动的通用表示。其次,我们使用基于意大利面的推理方法来推断活动。在PaStaNet的推动下,我们的方法取得了显著的改进,例如,在监督学习中,HICO的完整集和单次集的mAP分别为6.4和13.9,在迁移学习中,V-COCO和基于图像的A VA的mAP分别为3.2和4.2。代码和数据可在http://hake-mvig.cn/.获得
创新点:
- 首先推断人的部件状态
- 然后根据部件级语义推理出活动
2.Introduction
我们提出两个强大的工具来促进基于图像的活动理解:1) Activity2V ec:使用PaStaNet,我们将人类实例转换成由PaSta表示组成的向量。Activity2V ec通过PASs识别提取零件级语义表示,并组合其语言表示。由于PaSat编码活动的公共知识,Activity2V ec作为一个通用的特征提取器,用于可见和不可见的活动。2)提出了基于零件状态的推理方法。我们构建了一个由人类实例和部件语义表示组成的层次活动图,并通过结合实例和部件级子图状态来推断活动
- 优点有两个方面:1)可重用性和可移植性:PaSta是动作的基本组成部分,它们的关系可以类比于氨基酸和蛋白质、字母和单词等。因此,PaSta是可重用的,例如hhand,hold,我通过各种动作共享的东西,如“牵马”和“吃苹果”。因此,我们有能力用一组小得多的面食来描述和区分大量的活动,即一次性标签和可转移性。对于少镜头学习,可重用性可以大大减轻其学习难度。因此,我们的方法显示出显著的改进,例如,我们在HICO [3]的单次集合上提升了13.9 mAP。2)可解释性:我们不仅获得了更强大的活动表示,还获得了更好的解释。当模型预测一个人在做什么时,我们很容易知道原因:身体部位在做什么。
- 主要贡献有:1)我们构建了PaStaNet,这是第一个带有细粒度PaSta标注的大规模活动知识库。2)提出了一种新的提取零件级活动表示的方法Activity2V ec和一种基于意大利面的推理方法。3)在监督学习和迁移学习中,我们的方法在大规模活动基准上实现了显著的改进,例如在HICO [3]和HICO-DET [4]上分别实现了6.4%(16%)、5.6%(33%)的mAP改进。
3.Related Works
- Activity Understanding
- Human-Object Interaction
- Body Part based Methods
- Part States
4.Constructing PaStaNet
PaStaNet寻求探索人类对作为原子元素的PaSta的常识,以推断活动。
- PaSta 定义:我们把人体分解成十个部分,分别是头,两个上臂,两只手,臀部,两条大腿,两只脚。零件状态(PaSat)将被分配给这些零件。每个PaSta代表目标零件的描述。比如“手”的PaSta可以是“拿东西”或“推东西”,而“头”的PaSta可以是“看东西”、“吃东西”。
- Data Collection 通过众包收集以人为中心的活动图像(30K图像与粗略的活动标签配对)以及现有的设计良好的数据集[3,4,25,32,66,35] (185K图像),这些数据集是围绕丰富的语义本体、多样性和活动可变性构建的。他们所有带注释的人和物都被提取出来供我们构建。最后,我们收集了超过20万张不同活动类别的图片。
- Activity Labeling 从118K图像中选择了156个活动,包括人-物体交互和身体运动。根据他们的说法,我们首先从现有的数据集和众包中清理和重组带注释的人和对象。然后,我们在其余的图像中标注活跃的人和交互的对象。因此,PaStaNet包括156个活动的所有活动的人类和对象边界框。
- Body Part Box 为了定位人体部位,我们使用姿势估计[13]来获得所有被注释的人的关节。然后我们根据[14]生成十个身体部位框。估算误差通过手动方式解决,以确保高质量的注释。每个Body Part Box都以一个关节为中心,并且通过缩放颈部和骨盆关节之间的距离来预定义箱的大小。置信度高于0.7的关节将被视为可见。当不能检测到所有关节时,我们使用基于身体知识的规则。也就是说,如果颈部或骨盆是不可见的,我们根据其他可见的关节组(头部、主体、手臂、腿)来配置零件盒,例如,如果只有上半身是可见的,我们将手盒的大小设置为瞳孔距离的两倍。
- PaSta Annotation
- Activity Parsing Tree 为了说明PaSta 和活动之间的关系,我们使用它们的统计相关性来构建一个图(图2):活动是根节点,PaSta 是子节点,边缘是共现的。
5.Activity Representation by PaStaNet

PaStaNet范式。我们提出了一个新的范例来利用一般的零件知识:1)对一个人和一个交互的对象进行PASs识别和特征提取:
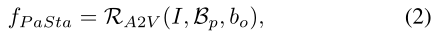
2)基于PaSta的推理(PaStaR),即从PaSta到活动语义:
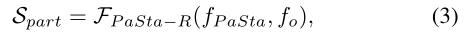
6.Part State Recognition

如图3,有了对象和身体部位框B0,Bp,我们就可以进行如图3所示的PaSta识别。具体来说,COCO [34]预先训练的faster R-CNN [49]被用作特征提取器。对于每个零件,我们将零件特征f(i) p与b(i)p相连接,并将对象特征fo与boas输入相连接。对于仅身体运动,我们输入整个图像特征fcas fo。
所有特征将首先输入到零件相关性预测器。部件相关性表示身体部件对动作的重要性。例如,脚通常与“用杯子喝水”相关性较弱。而在“吃苹果”中,只有手和头是必不可少的。这些相关性/注意标签可以直接从PaSta标签转换而来,即注意标签将是一个,除非它的PaSta标签是“无动作”,这意味着这一部分对动作推理没有任何贡献。以零件注意标签作为监督,我们使用由FC层和Sigma组成的零件相关性预测器来推断每个零件的注意{ ai } 10i = 1。只要PaSta label中有对该bodypart的描述,那么此bodypart的attention label就为1,否则为0。从形式上来说,对于一个人和一个互动的对象:
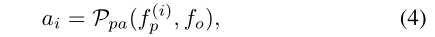
计算出attention后会乘回原part feature。
也就是对每一个bod ypart与之相关联的物体做body part的状态识别,这里需要注意的一点是由于一个bodypart可能有几个状态,所以用多个Sigmoids去做multi-label的classification。
最终的loss如下图,包含两部分,一部分是attention的loss,一部分是PaSta recognition的loss。
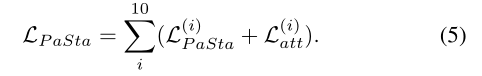
7.PaSta-based Activity Reasoning
通过上述得到的feature,构建Hierarchical Activity Graph (HAG)去model activities。
构建的方式包含Linear Combination,MLP,Graph Convolution Network,Sequential Model,Tree-Structured Passing。

















 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











