







Surface defect classification and detection on extruded aluminum profiles using convolutional neural networks
基于卷积神经网络的挤压铝型材表面缺陷分类与检测
//2022.7.11上午8:49开始阅读笔记
速览
1.作者做了什么
使用CNN网络对铝型材表面进行特征提取和分类已经对视频帧中的缺陷进行检测
2.做这件事有什么意义
实现了铝型材表面的缺陷自动检测,对于工业领域实现自动化检测质量控制具有重要意义;
3.作者是用什么方法去做的
数据集采集:使用简单的相机在多个拍摄条件下对铝型材表面进行拍摄从而得到数据集,也就是从不同方向,从近距离和远距离拍摄缺陷
数据增强:813的训练集对于训练深度学习算法来说相当小。因此,数据增强(DA)是在训练集上执行的,在训练集中,我们对图像随机应用平移、旋转、水平翻转和垂直翻转的变换,以提供更多的看不见的训练数据。训练图像中产生的空白区域用零填充,并显示为黑色.
模型和方法:使用VGG16/ResNet50/GoogLeNet三种骨干网络模型
训练过程详解:数据分为三组:大小为813的训练集、大小为16的验证集和大小为80的测试集。有意将验证集大小设置为一个较小的数字,以保存用于训练和测试的重要数据。在训练期间,我们在验证集上监测网络的性能,以采用早期停止[20]。提前停止旨在减少训练数据可能的过度拟合。随着训练的进行,将监控验证集的准确性。当验证集精度突然开始下降时,训练停止。
迁移学习的使用:使用事先在ImageNet数据集上的预训练权重进行模型参数的初始化。
对网络结构的调整以适应灰度图像数据集:在将图像进行灰度化处理时,选择了蓝色通道进行保留,因为工业界中经常使用的就是蓝色通道进行缺陷检测。
骨干网络的改变:
VGG16:在前两个卷积层中应用2而不是1的步长来处理更高的图像分辨率。我们执行梯度反向传播,批量大小为8,学习率为10−5结合ADAM优化器[25]。
GoogLeNet:将第一卷积层的步长从2调整为4,将第二卷积层的步长从1调整为2,以应对更高的图像分辨率。此外,我们删除了GoogLeNet的中间分类器。我们执行梯度反向传播,批量大小为16,学习率为10−5和ADAM优化器。
ResNet50:在第一卷积层中应用4而不是2的步幅,在第一卷积块中应用2而不是1的步幅,以应对我们图像的更高分辨率。我们执行梯度反向传播,批量大小为16,学习率为10−4和ADAM优化器。
缺陷检测方法:使用Faster RCNN结合ResNet50骨干网络。仅采用随机水平翻转来扩充该数据集。在批量为1时进行网络优化,并采用学习率为:3.10^-4且使用动量优化器。
分析不同骨干网络训练的性能差异:ResNet50是性能最好的网络。它实现了0.98的测试集精度。GoogLeNet的测试集精度排名第二,为0.80,VGG16的测试性能排名第三,精度为0.76。ResNet50和GoogLeNet之间的性能差异相对较大,可能是因为在原始GoogLeNet架构中省略了内部分类器。
此外作者设计了有无迁移学习和有无数据增强的比较实验:
1.有TL和没有DA 的训练;
2.没有TL和有DA 的训练;
3.没有TL和没有DA的训练;
作者还展示了CNN中某些层的特征图(进行了可视化);
重点:缺陷检测方法所做的比较实验:
1.TL和DA(水平翻转)训练;
2.没有TL和DA(水平翻转)的训练;
缺陷检测训练代数设计:两种方案的批量大小均选择为1。培训在第一个场景中进行了30万次迭代,在第二个场景中进行了80万次迭代。
论文地址
论文贡献
本文提出了一种表面缺陷分类和检测方法,通过一个简单的摄像机记录生产过程中的挤压型材,并通过神经网络架构区分无瑕表面和包含各种常见缺陷的表面(表面缺陷分类)。此外,使用神经网络指出视频帧中的缺陷(表面缺陷检测)。在这项工作中,我们证明了人工智能方法与工业应用(如质量控制)高度兼容,即使在常见的工业约束条件下,例如训练神经网络的数据集大小非常有限。数据增强和转移学习是满足现代生产设施在检测表面缺陷方面的高要求的训练网络的关键组成部分,尤其是当对训练集的访问受到限制时。分类精度为0.98,检测设置的平均精度为0.47,同时在包含813幅图像的数据集上进行训练。实现了实时分类和检测代码,即使照明条件和摄像机方向发生变化,网络仍能可靠运行。
论文内容
1.介绍
挤压铝型材常用于车体零件、火车框架、窗框,和摩天大楼支撑结构,举几个例子。
常见的表面缺陷包括起泡、划痕和打滑痕迹[1]。
2.表面缺陷、数据采集和标记
在铝型材生产过程中,经常会出现三种不同的表面缺陷。图1显示了没有任何缺陷、有气泡、有打滑痕迹和划痕的轮廓。

由于反射引起的任意伪影与真实表面缺陷之间的区别,使得正确识别表面缺陷的任务更具挑战性。
收集了用于训练各种神经网络结构的数据集。总共使用了909张包含气泡、划痕、打滑痕迹或无缺陷铝表面的图像。为了使数据集尽可能广泛,在各种条件下拍摄了缺陷的图像。在高亮度和低亮度下,从不同方向,从近距离和远距离拍摄缺陷(见图2)。这一过程很重要,因此网络可以从以后使用网络进行推理时可能出现的各种曲面设置中学习。如果网络仅使用单个成像条件来训练其权重,则对于工业实施过程中可能遇到的这些表面设置的变化,网络将变得不稳定。
在目标检测中,除了为标记区域指定正确的缺陷类型外,网络训练还要求专家标记表面缺陷左上角和右下角的像素。图3显示了包含多个泡罩的图像的标签。泡罩有标记,标签与物体相关。物体检测的标记在LabelImg[14]中进行。总的来说,在总数据集中识别出2000个泡罩、1500个划痕和200个打滑痕迹。


3.模型和方法
3.1 CNN概述(略)
3.2 表面缺陷分类
使用VGG16/ResNet50/GoogLeNet三种骨干网络模型。
3.2.1数据预处理和增强
选择了灰度图像进行处理,并且将分辨率设置为:896 x 896。保持这个分辨率的原因:虽然RoI区域占原图像中的比例较小,但是不影响训练过程。
数据分为三组:大小为813的训练集、大小为16的验证集和大小为80的测试集。有意将验证集大小设置为一个较小的数字,以保存用于训练和测试的重要数据。在训练期间,我们在验证集上监测网络的性能,以采用早期停止[20]。提前停止旨在减少训练数据可能的过度拟合。随着训练的进行,将监控验证集的准确性。当验证集精度突然开始下降时,训练停止。
813的训练集对于训练深度学习算法来说相当小。因此,数据增强(DA)是在训练集上执行的,在训练集中,我们对图像随机应用平移、旋转、水平翻转和垂直翻转的变换,以提供更多的看不见的训练数据。训练图像中产生的空白区域用零填充,并显示为黑色。图5显示了四个增强图像。

3.2.2 迁移学习
使用事先在ImageNet数据集上的预训练权重进行模型参数的初始化。
在将图像进行灰度化处理时,选择了蓝色通道进行保留,因为工业界中经常使用的就是蓝色通道进行缺陷检测。
3.2.3 VGG16网络.
在前两个卷积层中应用2而不是1的步长来处理更高的图像分辨率。我们执行梯度反向传播,批量大小为8,学习率为10−5结合ADAM优化器[25]。
3.2.4 GoogLeNet网络
将第一卷积层的步长从2调整为4,将第二卷积层的步长从1调整为2,以应对更高的图像分辨率。此外,我们删除了GoogLeNet的中间分类器。我们执行梯度反向传播,批量大小为16,学习率为10−5和ADAM优化器。
3.2.5 ResNet50网络
在第一卷积层中应用4而不是2的步幅,在第一卷积块中应用2而不是1的步幅,以应对我们图像的更高分辨率。我们执行梯度反向传播,批量大小为16,学习率为10−4和ADAM优化器。
3.3表面缺陷检测
使用Faster RCNN结合ResNet50骨干网络。仅采用随机水平翻转来扩充该数据集。在批量为1时进行网络优化,并采用学习率为:3.10^-4且使用动量优化器。
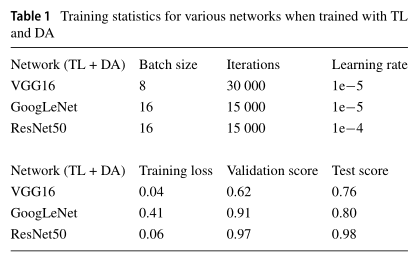
训练情况统计表如下:
4.结果
4.1 分类结果
4.1.1迁移学习和数据增强培训
表1总结了批量大小、训练的迭代次数、学习率、平均训练损失以及本研究中检查的三个网络实现的验证和测试精度。ResNet50和GoogLeNet的批量大小选择为16,VGG16的批量大小只能设置为8,因为它需要训练的重量很大,且GPU也有很大的内存花销。
分析不同骨干网络训练的性能差异:ResNet50是性能最好的网络。它实现了0.98的测试集精度。GoogLeNet的测试集精度排名第二,为0.80,VGG16的测试性能排名第三,精度为0.76。ResNet50和GoogLeNet之间的性能差异相对较大,可能是因为在原始GoogLeNet架构中省略了内部分类器。
4.1.2 有无迁移学习和数据增强的训练程序比较
1.有TL和没有DA 的训练;
2.没有TL和有DA 的训练;
3.没有TL和没有DA的训练;
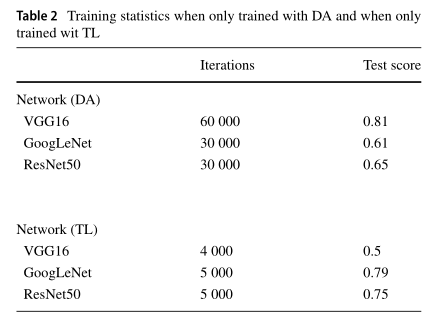
第三种情况导致训练不稳定,本研究未对此进行进一步研究。小数据集不允许没有TL和DA的训练。表2显示了第一个和第二个场景的训练统计信息。当使用DA进行训练时,GoogLeNet的测试集精度为0.61,ResNet50的测试集精度为0.65。因此,单靠数据增强无法正确训练网络。当GoogLeNet和ResNet50使用TL而不是DA进行训练时,他们的测试集分数分别为0.79和0.75。与TL和DA训练相比,DA引入的旋转不变性可能导致较小的精度。当使用DA(0.81)进行训练时,只有VGG16的准确度与之前使用TL和DA的情况相似,但当仅使用TL(0.5)进行训练时失败。
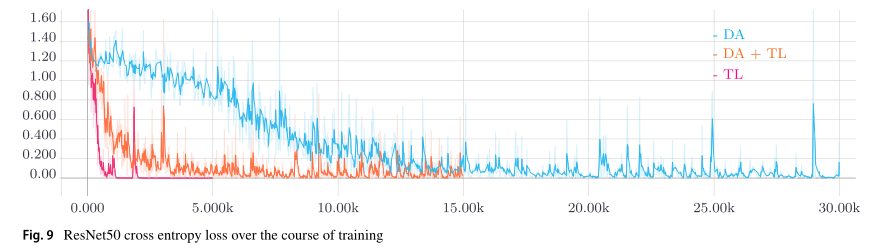
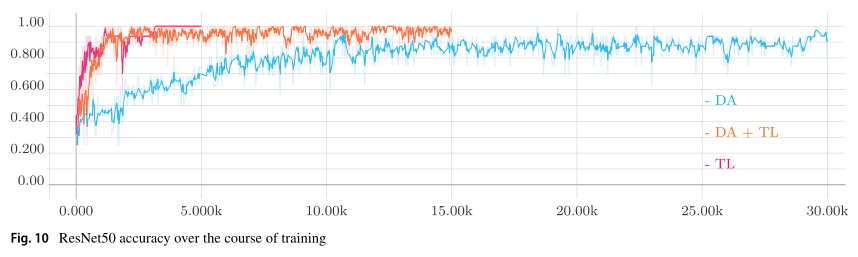
TL和DA是在我们的小数据集上训练深度神经网络的基础。这一说法也得到图9和10的支持。绘制了平滑的训练损失和训练过程中的验证精度。当不使用TL且仅使用DA时,与使用TL的训练相比,训练过程需要更长的时间(见图9)。当仅使用TL而不使用DA进行训练时,可以实现训练损失的最快最小化。然而,对小数据集的过度拟合发生得很快,这表现在测试集精度较低。从整个训练过程中的验证集精度来看,可以得出类似的结论(见图10)。当仅使用TL进行训练时,由于训练集大小不够大而导致的不稳定训练因验证集精度的突然中断而变得明显。当仅使用DA进行训练时,当同时使用TL和DA进行训练时,验证集精度饱和远低于相应的精度。
4.1.3 ResNet50权重和特征图(TL+DA)
为了可视化ResNet50架构在训练过程中学习到的内容,在训练过程结束后,在图11a中绘制了第一卷积层内核。该图像包含64个子图像,通过灰度强度表示核心值。像素越亮,对应的核值越高。
图11b证实了前面的陈述。它显示了当第一卷积层的特征映射在其深度上对一批所有图像进行平均时获得的值。定向边缘(如轮廓边缘或划痕)显示为亮白色。水泡等圆形形状也清晰可见为白点。图11b中的红色箭头指向由内核激活的轮廓边缘、划痕和水泡。

4.1.4 VGG16特征图(TL+DA)

图12中第一列显示输入图像,第二列和第三列描述了在训练过程结束时平均值深度在第四和第十一卷积层的特征图。
可以看出,原始图像中的缺陷在更深的网络层中被激活。事实上,在图12的最后一列中,它们是可见的亮点和条纹。图12a至c显示了挤压铝型材上泡罩的激活。在最初的图像中,科学家的脚可以在左上角看到。
在第四层,轮廓中间的水泡已经被激活,站在轮廓旁边的科学家的脚仍然可见。在第11层中,只有水泡保持激活状态,脚消失。图12d t o f显示了一个类似的场景,其中表面上的水泡在网络的深层中被激活。滑动标记的激活如图12g至图12i所示,划痕的激活如图12j至图12l所示。特征图强调网络在静止时学习了有意义的内核以及数据的底层结构且排除图像中的任意瑕疵(如眩光或员工脚)。
4.2 物体检测结果
接下来,我们将讨论通过目标检测程序实现的性能。已经测试了两种场景:
-
TL和DA(水平翻转)训练。
-
没有TL但有DA(水平翻转)的训练
两种方案的批量大小均选择为1。培训在第一个场景中进行了30万次迭代,在第二个场景中进行了80万次迭代。
下面两幅图展示了训练过程中的loss和mAP针对于ResNet50骨干网络且在迁移学习和未在迁移学习下的训练过程统计结果。
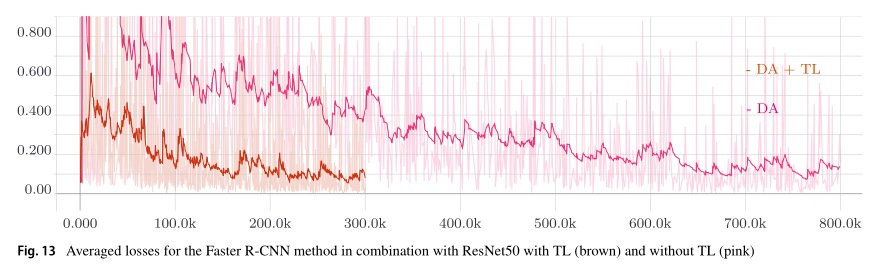
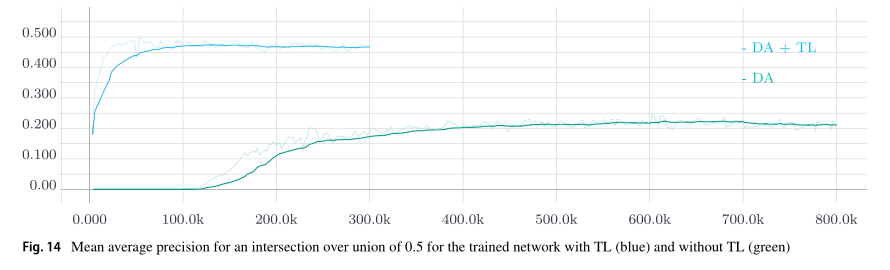
5.实时实现
在测试过程中,我们发现结果与照明条件、摄像机方向和摄像机到铝型材的距离无关。图15a给出了实时分类推理的示例,图15b给出了缺陷检测推理的示例。

6.总结
强烈建议在数据集小的时候使用数据增强和迁移学习。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











