







The Email address begins with shianlin2084.
随机投影集成分类
1. 论文泛读
1.1. 标题
随机投影集成分类
1.2. 摘要
1.2.1. 方案
这是一个通用方案:对高维数据分类,使用随机投影,将特征向量降维至低维空间,然后使用任意基分类器,选出合适的进行结合。将随机矩阵划分成不相关的组。在每个组里选出服从最小测试误差(?)的估计。然后集成这些结果,使用数据驱动型投票阈值决定最终结果。我们的理论结果阐明了增加投影数量对性能的影响。
1.2.2. 效果
1.我们的理论结果阐明了增加投影数量对性能的影响
2.此外,在充分降维假设所隐含的边界条件下,我们证明了随机投影集成分类器的测试超额风险可以由不依赖于原始数据维数的项来控制
3.随着预测数量的增加,一个项变得可以忽略不计
4.通过大量的模拟研究,将该分类器与其他几种常用的高维分类器进行了实证比较,显示出其优异的有限样本性能
1.3. 介绍
1.3.1. 前人方法
- 符号:p:矩阵维度;n(训练)样本数目
- LDA等一系列不适应高维
- 使用特征提取;也有使用软阈值获取稀疏边界
- 使用正则项
1.3.2. RPEnsemble
- 随机投影:the celebrated Johnson–Lindenstrauss Lemma
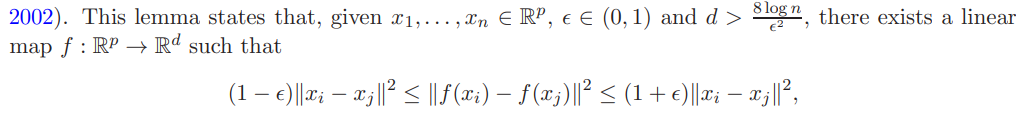
注意,在这个保证了对偶距离的函数f,可以使用哈尔测度上的随机投影分布,在随机多项式时间里找到【第三章证明,但是实际操作可以见公布的代码】。有趣的是,在该引理中的投影下界d,并不依赖于初始维度p。这个下界,常数因子是最优的 ===> 随机矩阵投影可以大量节约时间。当维度p大于log n的时候,使用随机矩阵投影可以有与原来矩阵具有相同甚至更好的统计意义上的表现。【这句后面有讲,只用一个随机投影矩阵的例子】 - 集成:

- 大概意思是说,第一个2011代指的那篇论文,用那个公式估计一个p*p大小的总体逆协方差。后面两个引用都用这篇论文的idea进行实验。这个地方,请注意,并不是限定为仅可以在分类上使用的
- bagging:

- 筛选数据的理论支持

这段就说怎么筛选,怎么确定阈值的 - 论文结构:
略。跳过理论部分
1.4. 小标题

通读可以发现,理论部分优先跳过,其他泛读,结合公布的代码与实验进行理解与模仿。第八节后都是附录,选择参数的要看
1.5. 结论和讨论
- 这玩意儿是个框架,啥分类器都可以往里面套
- 可以给投票加权重
- 面对多分类问题的拓展:

- 面对其他随机投影的选择
- 维度过高,例如是上千级别的,生成随机投影就很花时间,这个时候,就有

也就是使用一种矩阵A。A的每一行都只有一个非零元素(是1)。请注意A是d*p大小的。当然,这种方法丢失了RPEnsemble里面最有吸引力的地方(这个地方就是它与正交变换是等价的)。要证明相应的理论是可以的,但这种情况下,要获得良好的分类,就不可避免地需要更大的结构。【RNM】
- 虽然这玩意解释性不好,但选出来的随机投影暗含的权重表明了不同变量的相对重要性。也可以从这一方向来理解:RPEnsemble分类器生成了变量排序
- 类似于分抽样和自举抽样,我们可以认为对原始数据的每一个随机投影,以及在许多不同扰动下观察到的效果,往往是统计学家所寻求的“稳定”效果
- 为啥RPEnsemble对分类问题有吸引力?
a. 因为它们能够从数据中识别出“好的”随机预测
b. 我们可以从选定的预测中汇总结果
预计这两个以上特性将在确定相关方法的未来应用领域中发挥重要作用
1.6. 图表
- 分类器使用LDA,QDA,KNN
- fig 1是用200例50维的数据,分别随便投影和精挑细选(上下)成为2维,LDA,QDA,KNN(左右)来证明下面的比上面的好
- fig2 的黑线是平均误差,上下两个标准差(红线),在超过20组 B 1 B_1 B1, B 2 B_2 B2上得到的。使用模型是model 2,其他参数是n = 50,p = 100,d = 5, B 2 B_2 B2都是50。三张图是三个分类器
- fig3 中,变动的是样本数量KaTeX parse error: Undefined control sequence: \n at position 1: \̲n̲和 π i \pi_i πi。固定的分类器是QDA,样本维度 p p p = 100 =100 =100, d = 2 d = 2 d=2红线是估计,黑线是真实值。使用模型3
- fig4,5 是直方图,第10节的,先跳过;发现都是附录的内容,跳
- 实验的话是4个数值实验, n = 50 , 200 , 1000 n = 50,200,1000 n=50,200,1000, p = 100 , 1000 p = 100,1000 p=100,1000。有两种不同的先验概率。使用高斯投影,令 B 1 = 500 B_1 = 500 B1=500, B 2 = 50 B_2 = 50 B2=50。表格1和2是风险估计和标准差, p = 100 p = 100
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2409
2409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









