






 本文介绍了如何处理MIMIC-CXR数据集,包括使用PIL和chardet库加载图像和文本描述,以及创建DatasetProcessor类来处理CSV文件中的元数据,筛选出训练集样本并展示图像及其对应的文本注释。
本文介绍了如何处理MIMIC-CXR数据集,包括使用PIL和chardet库加载图像和文本描述,以及创建DatasetProcessor类来处理CSV文件中的元数据,筛选出训练集样本并展示图像及其对应的文本注释。
MIMIC-CXR数据集文件目录格式
- MIMIC-CXR
- mimic-cxr-2.0.0-metadata.csv
- mimic-cxr-2.0.0-metadata.csv
- mimic-cxr-2.0.0-split.csv
- mimic-cxr-2.0.0-split.csv
- mimic-cxr-images
- files
- p10
- p10000032
- s50414267
- 4a0397d2-1c7cac8d-bd1e1991-d3459191-3e510506.jpg
...
...
...
- p11
...
- p19
- mimic-cxr-reports
- files
- p10
- p10000032
- s50414267.txt
...
...
- p11
...
- p19
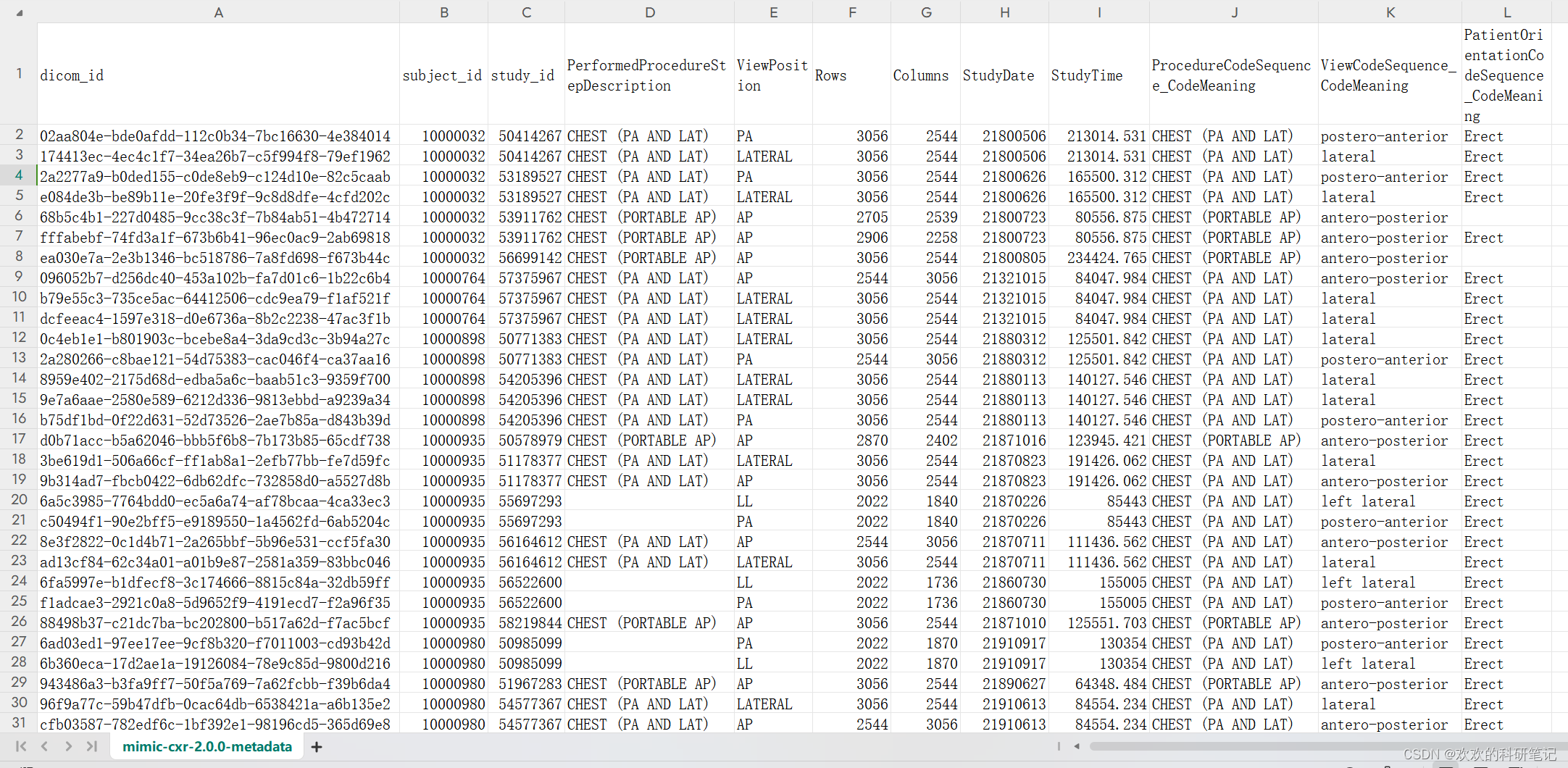
mimic-cxr-2.0.0-metadata.csv文件内容:
mimic-cxr-2.0.0-split.csv文件内容
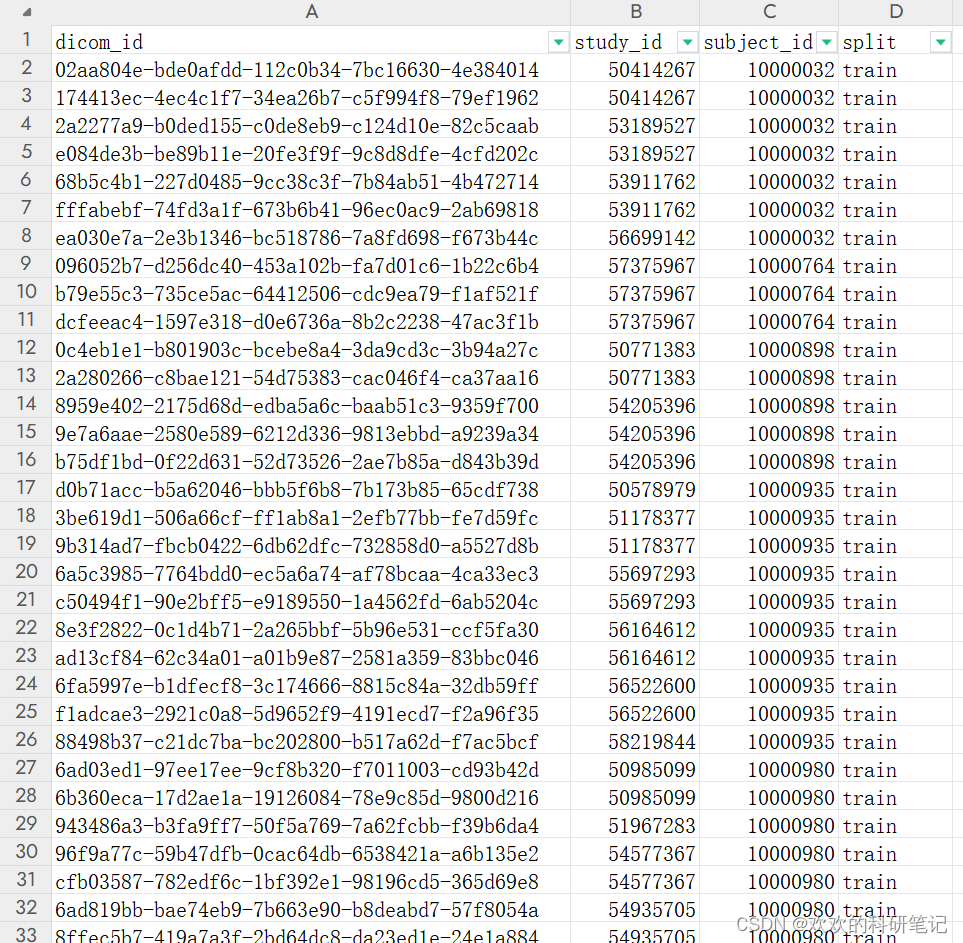
其中 dicom_id:图片名;s+study_id:图片的上级目录(病人在不同时期的检查);p+subject_id:图片的上上级目录也是病人的编码(这个文件夹内是这位病人在不同时期做的检查);split:分为train、validate和test
我的项目中需要图像以及图像的文本描述,所以我们要做的就是提取对应文件夹下的图像以及他的描述性文本,具体操作如下:
导入要用的库:
import csv
from collections import defaultdict
import chardet
from PIL import Image
import os图像加载及文本加载:
# 使用Pillow库加载一张图片,并将其转换为RGB模式
def pil_loader(path):
with open(path, 'rb') as f:
img = Image.open(f)
return img.convert('RGB')
# 找到txt文件中文本描述部分
def mimix_reports_loader(path_reports):
with open(path_reports, 'r') as file:
content = file.read()
start_index_findings = content.find('FINDINGS:') + len('FINDINGS:')
end_index_findings = content.find('IMPRESSION:')
findings_text = content[start_index_findings:end_index_findings].replace('\n', '').strip()
return findings_text定义一个名为DatasetProcessor的类用来加载数据集:
class DatasetProcessor:
def __init__(self, dataset, metadata):
self.dataset = dataset
self.metadata = metadata
self.samples = []
def process_dataset(self):
if self.dataset == 'mimic-cxr':
samples = defaultdict(list)
with open(metadata, 'rb') as f:
# 使用chardet检测文件编码格式
file_content = f.read()
encoding = chardet.detect(file_content)['encoding']
with open(self.metadata, mode='r', encoding=encoding) as f:
reader = csv.DictReader((line.replace('\0', '') for line in f))
print(reader.fieldnames) # 打印列名
for row in reader:
if row['split'] == 'train': # 仅处理split为train的样本
key = (row['dicom_id'], row['study_id'], row['subject_id'], row['split'])
samples[key].append(None) # 添加一个空值作为占位符
self.samples = list(samples.keys()) # 仅保存键值对的键这里我只需要用训练集,所以只加载了train
设置文件路径:
# metadata是mimix数据集的CSV文件路径
metadata = '/.../MIMIC-CXR/mimic-cxr-2.0.0-split/mimic-cxr-2.0.0-split.csv'
# root是mimix数据集路径
root = "/.../data/MIMIC-CXR"输出:
# 创建数据集处理器实例
processor = DatasetProcessor('mimic-cxr', metadata)
# 处理数据集
processor.process_dataset()
# 输出
for i in range(len(processor.samples)):
dicom_id, study_id, subject_id, split = processor.samples[i]
print(f"dicom_id: {dicom_id}, study_id: {study_id}, subject_id: {subject_id}, split: {split}")
path = os.path.join(root, 'mimic-cxr-images/files', f'p{subject_id[:2]}', f'p{subject_id}', f's{study_id}', f"{dicom_id}.jpg")
img = pil_loader(path)
img.show() # 显示图片
path_reports = os.path.join(root, 'mimic-cxr-reports/files', f'p{subject_id[:2]}', f'p{subject_id}', f"s{study_id}.txt")
caption = mimix_reports_loader(path_reports)
print(caption)输出结果:
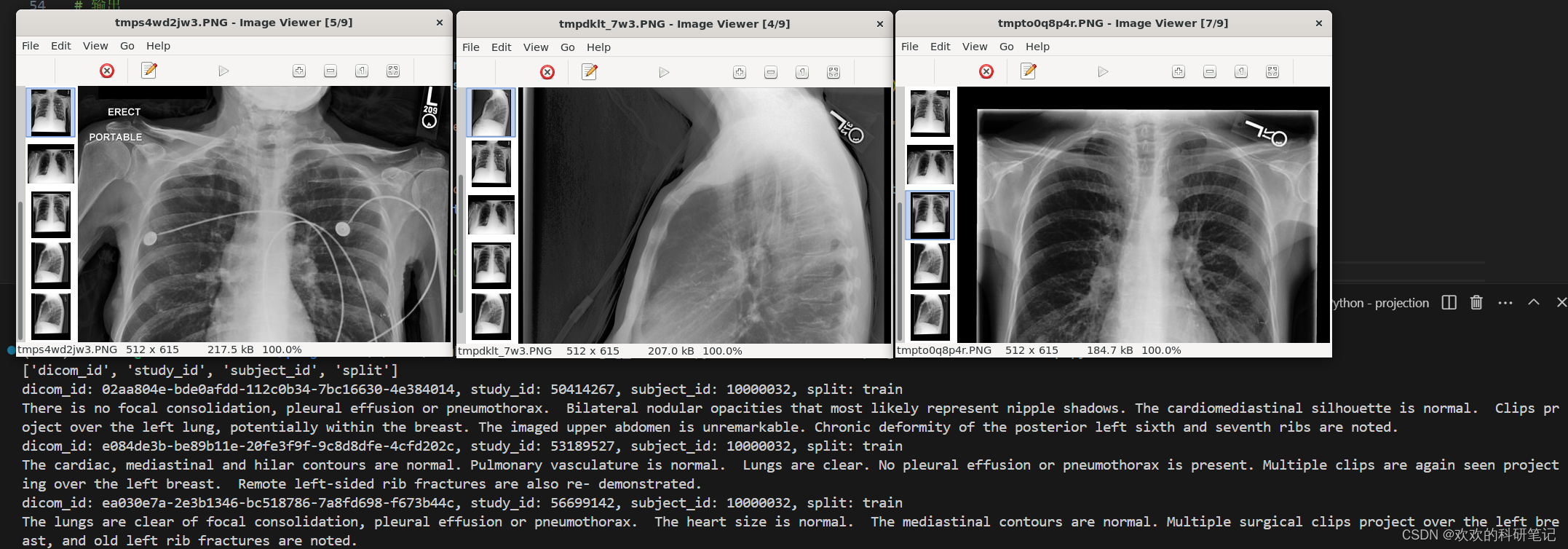
这里我修改了mimic-cxr-2.0.0-split.csv文件,只留下了三个数据以便于展示。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









