







TransReID
这篇文章是首个将视觉Transformer的ViT应用在ReID领域的研究工作,在多个ReID基准数据集上取得了超过CNN的性能。
原文:TransReID: Transformer-based Object Re-Identification
代码:https://github.com/heshuting555/TransReID
作者:阿里巴巴&浙江大学
Contributions
- 以调整适用于ReID任务的ViT作为Backbone进行特征提取,提出了名为ViT-BoT的Baseline
- 针对图像的视角、相机风格变化问题在Baseline上引入了Side Information Embedding(SIE)模块
- 在Baseline上引入了一个并列的Jigsaw分支(JPM),对全局和局部特征进行融合
Vision Transformer(ViT)学习
Transformer来源于2017 年谷歌机器翻译团队发表的《Attention is All You Need》。它完全抛弃了传统RNN和CNN等网络结构,仅仅采用Attention机制来进行机器翻译任务,取得了当时SOTA的效果。
Transformer最初提出是针对NLP领域的,ViT是将Transformer应用到CV领域,也取得了很好的效果。
原文:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
代码:https://github.com/google-research/vision_transformer
作者:谷歌
具体方法
在模型设计中,使用到了原始的Transformer Encoder,ViT对Transformer使用了最少的修改就将其用于计算机视觉,将图像分成小的patch,类似于nlp中的token,然后使用有监督的方式对训练模型以对图像分类。
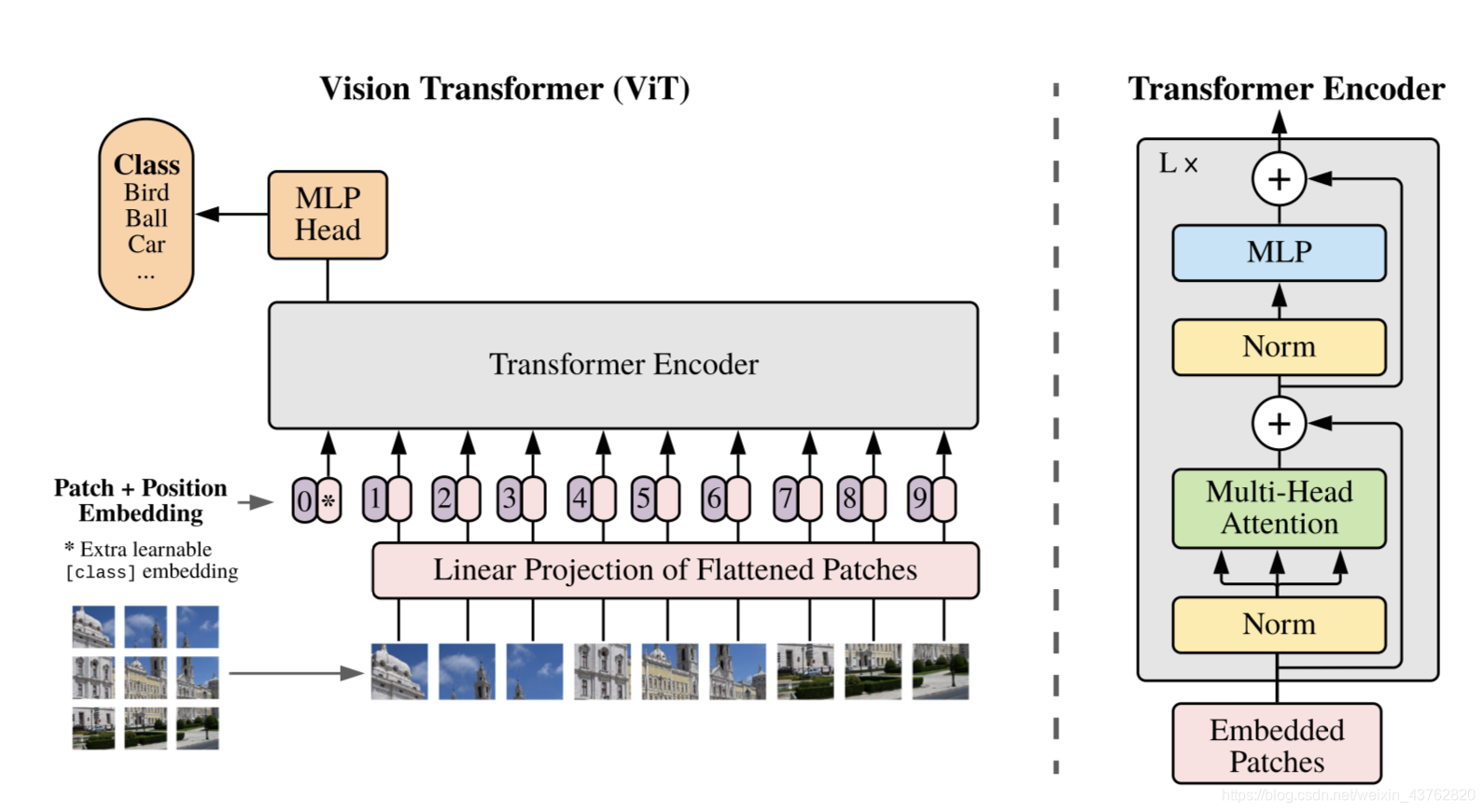
Patch Embedding
标准的Transformer以一串一维的token序列作为输入,为将图像变成对应的一维的序列patch embedding输入,将二维图像分成N个PxP大小的patch。本质就是对每一个展平后的 patch 向量做一个线性变换降维至 D 维,等同于对x进行P×P且步长为P的卷积操作
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1293
1293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









