







目录
Single one-shot and uniform sample
论文地址如下:
Introduction
早期的NAS采用嵌套的方式进行网络搜索,首先定义一个有向无环图(DAG)来表征体系架构搜索空间A,通过采样的方式从A中获得子网络结构α,将得到的α从头开始训练直到收敛,最小化训练loss得到α的权重参数wα。后通过得到的权重参数wα在验证集上优化,得到最优的子网络结构α。这种方式需要从头训练网络,费时且开销大。
共享权重是另一个网络搜索的方式,即架构搜索空间A被编码在supernet中,其表示为N(A、W),其中W是超网的权重。这个supernet曾被训练过一次,搜索空间A中的所有架构都直接从训练得到的W中继承其权重而不需要从头训练。因此,它们共享其公共图节点中的权重。这种共享权重的架构搜索方式速度很快,适合于Imagenet等大型数据集。然而,共享权重带来了两个棘手的问题。首先就是supernet中的权重在优化的过程中深度耦合,我们还无法得知为什么这种继承权重的方式比随机更加有效,但是这种可解释性不足的特性令训练充满了不确定性。其次就是架构参数与权重的联合优化又引入了进一步的耦合。
one-shot是网络搜索定义的新范式,它继承了嵌套优化和联合优化的优点。它也采用了共享权重的方式,只需要训练一次supernet,由子网络架构继承supernet的权重。与联合优化不同的是,在one-shot中将supernet的训练和架构搜索解耦,也就是分成了两步。先对supernet训练,再搜索架构。由于子网的权重继承自超网,不需要额外的fine tuning,在inference的时候精度也是很OK的。然而one-shot还是没有解决权重在优化的过程中深度耦合的问题。有的论文提出采用dropout的方式去减轻权重之间深度耦合,然而这种随机dropout的方式是不稳定的,结果也是无法预测的。而本文中提出了一个单路径 One-Shot 模型,其核心思想是构建一个简化的超网络——单路径超网络(Single Path Supernet),该方法在大型数据集 ImageNet 上取得了当前最优结果。
One-shot NAS方法回顾
架构搜索和超网训练的深度耦合是存在一定的问题的。早期使用嵌套优化的 NAS 方法在于解决公式 (1) 和 (2) 的优化问题。这不禁引起思考,问题解耦和权重共享的优点是否可以兼得?
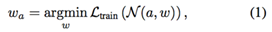
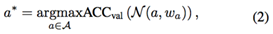
这一考虑诞生了所谓的 One-shot 。one-shot方法依然只训练一次超网络,并允许各个网络结构共享其中的权重。但是不同于嵌套优化或联合优化,在one-shot中超网络训练及模型搜索作为先后次序的两个步骤是解耦的。
首先,超网络权重被优化为(5)式,相比联合优化公式 (4) ,公式 (5) 已经不存在搜索空间的连续参数化,只有网络权重被优化:


其次,搜索部分被表示为:
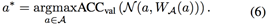
公式 (6) 与公式 (1) 、 (2) 的最大区别是其权重是预先初始化的。评估ACCval仅需要推理。没有微调或者再训练。因此搜索非常有效。通过借助进化算法,搜索同样非常灵活。像下式所示的等式(3)![]()
对模型结构进行的约束可以精确地满足。并且一旦训练好一个超网络,可在同一超网络内基于不同约束(比如 100ms 和 200ms 延迟)重复搜索。这些特性是先前方法没有提到过的,这将会使 One-Shot NAS 方法对实际任务更具吸引力。但依然存在一个问题。在等式 (5) 中,超网络训练的图节点权重是耦合的,复用权重是否适用于任意子结构尚不清楚。因此本文提出了单路径 One-Shot 模型,可以有效地缓解图节点权重深度耦合的问题。
Approach
Single one-shot and uniform sample
事实上,等式1和等式2中的训练方式是从头开始训练的,因此这种训练方式得到的评估是最准确的,然而却是不现实的,因为其开销过大,而我们要做的就是尽可能地去接近那个评估方式。在one-shot中,子网从超网中继承权重,我们要使得继承的权重尽可能地接近
,因此
与
相近似,近似的成效与Loss的最小化程度成正比。因此继承的超网络的权重
应与搜索空间中的所有子结构的优化同时进行,如下式所示:
![]() 。
。
这个式子是上文中式【5】的实现,在优化的每一步中,子结构是随机采样的,只有对应的权重被激活和更新。这不仅节省内存空间,而且高效。由此,超网络本身不再是一个有效的网络,而变成一个随机的网络。
为了减少节点权重之间的耦合,本文提出尽可能地简化搜索空间A,它只包含单一路径架构。如下图所示:

每条路径上有若干个Choice Block块,在每个Choice Block块中有若干个选择,每次采样只能保留一个选择,且后续不进行任何调优。在优化时根据结构分布采样一个路径已经出现在之前的权重共享方法之中,区别在于,在本文的训练中分布T(A)是一个固定的先验,而在先前方法中,它是可学习和更新的,后者会使超网络权重和结构参数优化深度耦合。
Super Net and Choice Block
Choice Block用于构建一个超网络。一个Choice Block包含多个choice。对于本文提出的单路径超网络,每个选择单元一次只调用一个选择。一个路径的获得是通过随机采样所有选择单元实现的。本文方法的简易性允许定义不同类型的选择单元,以搜索不同的结构变量。具体而言,旷视研究院提出两个全新的选择单元,以支持复杂的搜索空间。
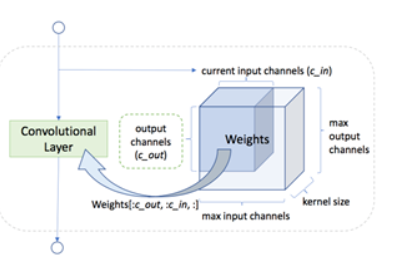
- 通道数搜索。选择单元旨在搜索一个卷积层的通道数。其主要思想是预先分配一个带有最大通道数的权重张量。在超网络训练期间,系统随机选择通道数并分割出用于卷积的相应的子张量,如下图所示:
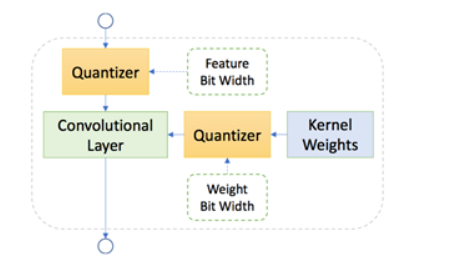
- 混合精度量化搜索。选择单元可以搜索卷积层权重和特征的量化精度。在超网络训练中,特征图的位宽和和权重被随机选取。如下图所示:
基于进化算法的模型搜索
针对等式 (6) 中的模型搜索,先前的 One-shot 工作使用随机搜索。这在大的搜索空间中并不奏效。因此,本文使用了进化算法,同时扬弃了从头开始训练每个子结构的缺点,只涉及推理部分,因此非常高效。详见算法 1如下所示。

Summary
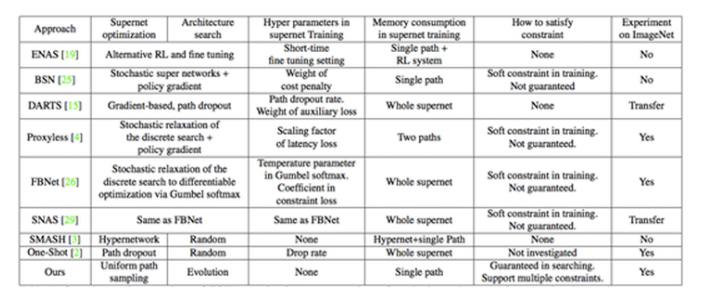
单路径超网络、均匀采样训练策略、基于进化算法的模型搜索、丰富的搜索空间设计,上述多种设计使得本文方法简单、高效和灵活。表 1 给出了本文方法与其他权重共享方法的一个全方位、多维度对比结果。















 2446
2446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









