







在学习注意力机制的时候,可能需要用到nn.softmax来进行矩阵的乘法结果进行权重归一,但是对于nn.softmax的参数dim不知道具体的操作流程,于是自分别创建两个函数,对应dim=1和dim=2的时候的情况
softmax1 = nn.Softmax(dim=1)
softmax2 = nn.Softmax(dim=2)
然后创建一个实例tmp,它的shape是[batch, n, m]
tmp = torch.randn(2,3,4)
tmp是长这个样子的

然后开始扔进函数里面,并打印,得到如下
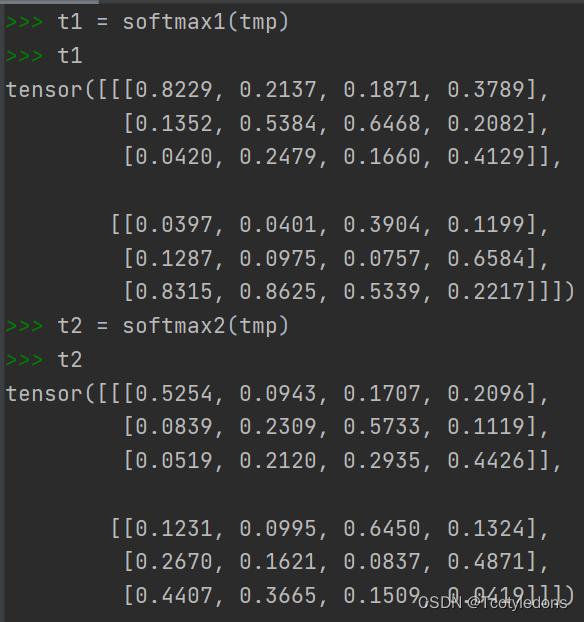
可以清晰的看到,dim=1是对n*m矩阵的逐列进行softmax,dim=2是对每行进行softmax操作,所有的操作对不同的batch都是独立进行的。















 4008
4008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









