







前言
最近还是在看一些医学图像分割的文章,由于在overall architecture中加入了transformer,考虑到transformer对于细节分割不太友好,并且local + global attention引入不利于结构分割的完整性。因此希望引入structure prior对local detail进行增强。看了两篇浙大GIVE lab提出的deep atlas prior文章,总结一下看看有没有改进的思路。- Paper 1:Semi-supervised Segmentation of Liver Using
Adversarial Learning with Deep Atlas Prior(MICCAI 2019) - Paper 2:Medical Image Segmentation with
Deep Atlas Prior (TMI 2020)
一、Probabilistic Atlas
提出Probabilistic Atlas的motivation比较简单,相对而言医学图像比自然图像具有更确定的位置以及形状信息。作者希望利用整个数据集的target的位置分布来对整体网络构成约束。
对于Probabilistic Atlas的定义也比较简单,作者在文中定义为:
Probabilistic atlas is obtained by averaging the manually segmented liver masks after registration of all annotated volumes.The value of each point represents the prior statistical probability that the liver appears at this space location
二、Deep Atlas Prior
1. Motivation
我们首先来回忆一下Focal loss,Focal loss是为了解决类别不平衡问题提出的,如下图所示,其中对于GT=1的样本来说,
p
t
p_t
pt趋近于1,则loss越低;对于GT=0的负样本来说,
1
−
p
t
1-p_t
1−pt越趋近于1,则loss越低。即相比交叉熵损失,Focal loss对于分类不准确的样本,损失没有改变,对于分类准确的样本,损失会变小。 整体而言,相当于增加了分类不准确样本在损失函数中的权重。

作者认为Focal loss是在训练过程中动态地调节难易样本的权重,而本文结合数据集的GT的分布特征,提前给出了难易样本定义,即利用前面提到的Probabilistic Atlas,将其转为相应样本在loss中占的权重,并约束为高斯分布,通过设置阈值0.5来区分正负样本,越接近0.5证明越难分,即:

同时作者提出了asymmetrical Gaussian function,即认为当预测概率
0
<
p
t
≤
0.5
0<p_t\le 0.5
0<pt≤0.5和
0.5
<
p
t
≤
1
0.5<p_t\le1
0.5<pt≤1服从的分布不相同,即:

其中
σ
1
\sigma_1
σ1和
σ
2
\sigma_2
σ2为超参数,并且
σ
1
<
σ
2
\sigma_1 < \sigma_2
σ1<σ2,保证正样本所占的权重大于负样本。
2. Overall Achitecture
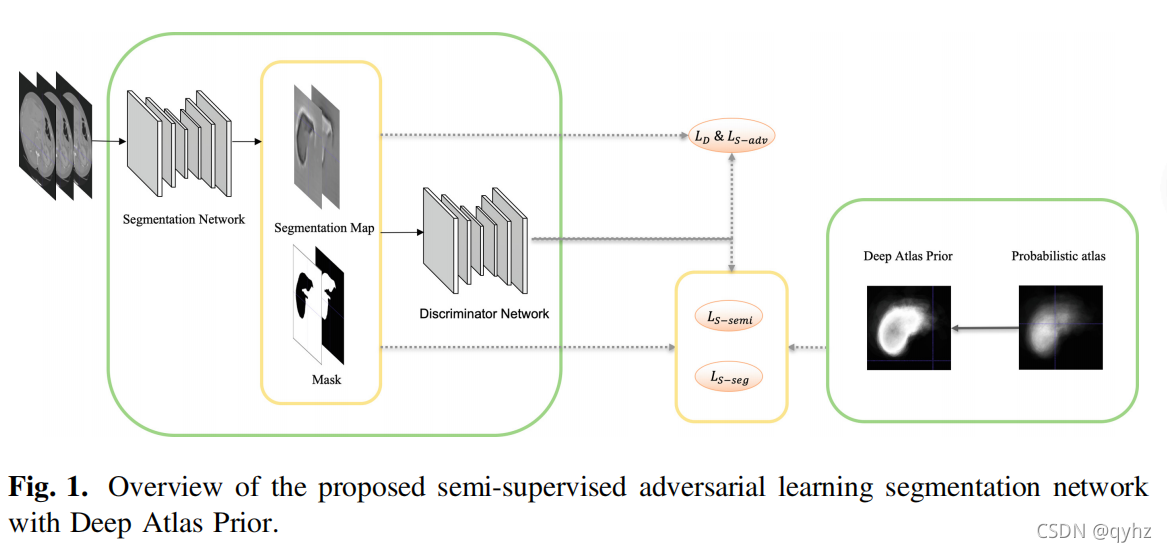
整体的网络结构是一个类似于GAN网络的结构,包括了生成器和判别器两部分,值得注意以下几点:
- 网络结构包括Segmentation Network和Discriminator Network两部分,其中Segmentation Network的输入为三通道,包括当前的slice和前面后面各一张slice,目的是为了捕捉z-axis的信息。
- 文章的题目为:Semi-supervised Segmentation of Liver Using
Adversarial Learning with Deep Atlas Prior,其中半监督体现在对于unannotated的数据,作者会根据经过带标签数据训练后的判别器去进行判别,保留高confidence的值进行回传。 - Loss计算包括几部分: L D L_D LD, L S a d v L_{S_{adv}} LSadv, L S − s e g L_{S-_{seg}} LS−seg and L S − s e m i L_{S-{semi}} LS−semi,其中前三个均针对于有标签的数据, L S − s e m i L_{S-{semi}} LS−semi针对无标签数据。
三、Objective Function
1.判别器损失
L
D
L_D
LD

2.对抗损失
L
S
−
a
d
v
L_{S-_{adv}}
LS−adv

3.分割损失
L
S
−
s
e
g
L_{S-_{seg}}
LS−seg
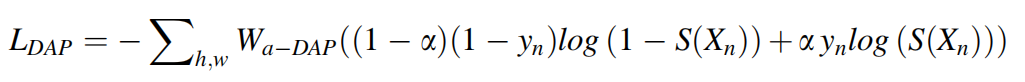
和一般的二分类交叉熵损失不同,这里用前面提到的
W
a
−
D
A
P
W_{a-{DAP}}
Wa−DAP对各个样本进行了加权,并且引入了超参数
α
\alpha
α平衡正负样本的数量。
对于有标签的数据来说,总的训练损失定义为:

作者将
L
S
−
s
e
g
L_{S-_{seg}}
LS−seg定义为Bayesian loss,包含先验损失
L
D
A
P
L_{DAP}
LDAP以及似然损失
L
f
o
c
a
l
L_{focal}
Lfocal,其中
δ
\delta
δ为调节两者的权重的超参数,实验中设置为2。
4.半监督分割损失
L
S
−
s
e
m
i
L_{S-{semi}}
LS−semi

其中
T
s
e
m
i
T_{semi}
Tsemi设置为0.3,即经过判别器判别出的结果,正确率高于0.3的进行回传操作。注意由于没有标签,因此
f
b
c
e
f_{bce}
fbce中的
y
n
y_n
yn设置为Segmentation Network的预测结果。
总的损失函数为:

实验中
λ
s
e
m
i
\lambda_{semi}
λsemi 设置为0.01 and
λ
S
−
a
d
v
\lambda_{S-{adv}}
λS−adv 设置为0.05。
四、Experiment Results
1.Settings
4. Dataset: ISBI LiTS 2017 Challenge(including 131 volumes with 103 training volumes and 28 testing volumes
5. Segmentation Network: DeepLab (Resnet101)
6. Discriminator Network: CNN with four convolutional layers and an up-sample layer, and the activation function is the Leaky ReLU.
7. Training Strategy:We first trained the model with the annotated images and then re-trained the model by unannotated images and annotated images alternately.
2. Experiments
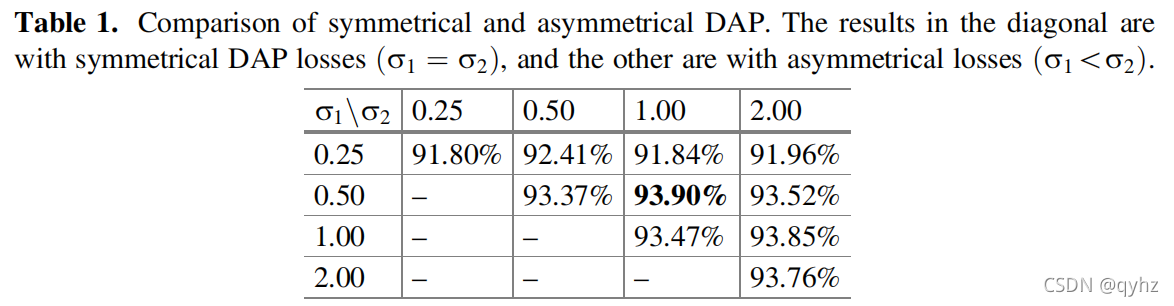
实验只做了
σ
1
≤
σ
2
\sigma_{1} \le \sigma_{2}
σ1≤σ2的部分,作者认为positive samples的权重需要大于negative samples的权重,实验发现
σ
1
=
0.5
\sigma_{1} =0.5
σ1=0.5同时
σ
2
=
1
\sigma_{2}=1
σ2=1时效果最好。
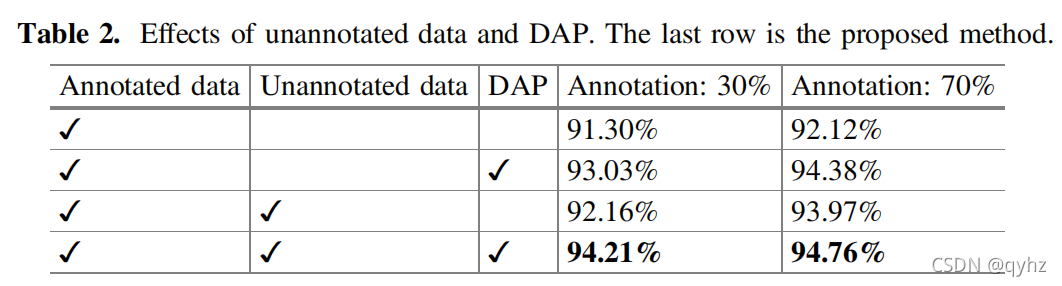
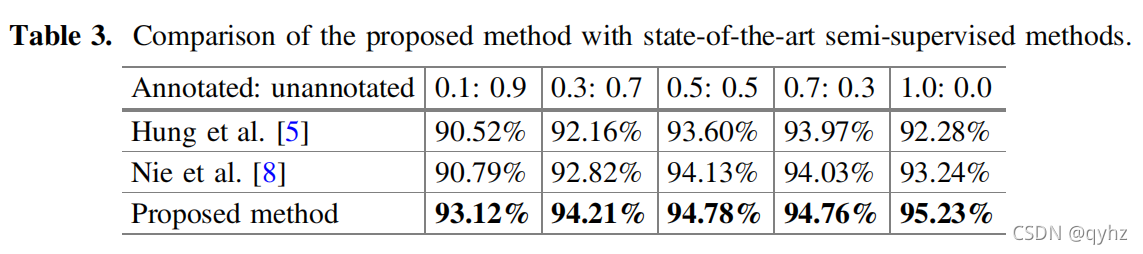
整体来说,作者做的实验非常充分,Table 2显示了分别在包含不同比例的annotated data和unannotated data以及是否有DAP的情况下精度的变化,证明了引入DAP的有效性以及本文中提出的半监督方法的有效性。
五、Analysis
1.作者提出的DAP本身是为了充分利用医学图像分割目标位置以及形状相对固定的特点,从而利用已有数据集的分布特征作为loss来对整体构成约束,将分割目标在整个数据集上出现的位置的频率作为先验信息,也作为难易样本划分的先验,和focal loss结合。
2.由于医学图像数据集比较小,因此计算的Probabilistic Atlas是不准确的,或者说只是对于高频的位置比较准确,并且作者将整个难易样本的权重设置强制约束为了高斯分布,比focal loss的条件要强了些。总体来说小编认为这种做法对于比较简单的二分类任务比较work,像对于一些多器官分割或者在一些分割目标的shape,position不太固定的情况下可能就不太明显了,而且作者对于有标签的数据训练的损失函数设置为:
实验中作者将
δ
\delta
δ的值设置为2,因此实际在训练过程中
L
D
A
P
L_{DAP}
LDAP始终要占据一部分loss对整个网络产生一定影响,正如我们前面提到的先验信息有可能是不准确的,这样会影响整个网络性能。因此后面改进可以将两者进行加权即设置为
δ
\delta
δ和
1
−
δ
1-\delta
1−δ会防止loss变化比较剧烈。
3.关于Probabilistic Atlas的计算问题,由于数据集比较小,可能计算不是很准确,需要筛选主要的一些点,作者在文中并未详细说明计算过程。
第二篇文章是在第一篇的基础上进行进一步的思考,主要解决了我上面提出的几点问题。 留到下次更新吧,请持续关注!!














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









