







DeepAtlas: Joint Semi-Supervised Learning of Image Registration and Segmentation
Xu, Zhenlin and M. Niethammer. “DeepAtlas: Joint Semi-Supervised Learning of Image Registration and Segmentation.” MICCAI (2019).
Abstract
Deep convolutional neural networks (CNNs) are state-of-theart for semantic image segmentation, but typically require many labeled training samples. Obtaining 3D segmentations of medical images for supervised training is difficult and labor intensive. Motivated by classical approaches for joint segmentation and registration we therefore propose a deep learning framework that jointly learns networks for image registration and image segmentation. In contrast to previous work on deep unsupervised image registration, which showed the benefit of weak supervision via image segmentations, our approach can use existing segmentations when available and computes them via the segmentation network otherwise, thereby providing the same registration benefit. Conversely, segmentation network training benefits from the registration, which essentially provides a realistic form of data augmentation. Experiments on knee and brain 3D magnetic resonance (MR) images show that our approach achieves large simultaneous improvements of segmentation and registration accuracy (over independently trained networks) and allows training high-quality models with very limited training data. Specifically, in a one-shot-scenario (with only one manually labeled image) our approach increases Dice scores (%) over an unsupervised registration network by 2.7 and 1.8 on the knee and brain images respectively.
code
介绍
由于不存在变形场的 ground-truth,配准的训练要么使用基于优化的方法的估计结果,要么是无监督的1 。最近的工作2 表明,通过在配准中加入额外的图像分割损失作为弱监督,可以比仅依赖于图像的无监督训练得到更好的配准结果。
这两个工作都是 VoxelMorph,2019 年 VM 提出了可以使用分割网络作为辅助网络监督配准学习来提高配准性能。
在实践中,获得 3D 医学图像的分割标签是困难的和劳动密集型的(is difficult and labor intensive)。因此,大部分 3D 图像数据都没有标签用于有监督学习。
针对这样的情况,我们提出了 DeepAtlas,联合弱监督配准和半监督分割学习。我们有以下贡献:
-
我们是首个提出联合图像配准和分割学习的。 DeepAtlas 既可以联合训练,也可以单独训练和预测。
-
DeepAtlas 只需要少量的人工分割标签。我们使用结构相似性损失来相互指导分割和配准。它通过计算浮动图像( I m I_m Im)的分割标签被配准网络扭曲后与目标图像( I t I_t It)的分割标签的不相似度来指导分割和配准。
如果配准后的图像分割(通过分割网络生成的)本来也有标签的话,可以给配准网络提供一致性监督学习,以及使分割网络产生匹配配准后的分割标签的分割预测。
-
我们在大型 3D 大脑和膝关节 MRI 数据集上评估了我们方法的有效性。使用少量手动分割,我们的方法优于单独学习的配准和分割网络。在极端情况下,如果只有一个手动分割的图像可用,我们的方法有助于 one-shot 分割,同时提高配准性能。
方法
我们的目标是通过联合学习一个分割和一个配准网络,在训练数据只有少量手动分割标签时,提高配准和分割精度。
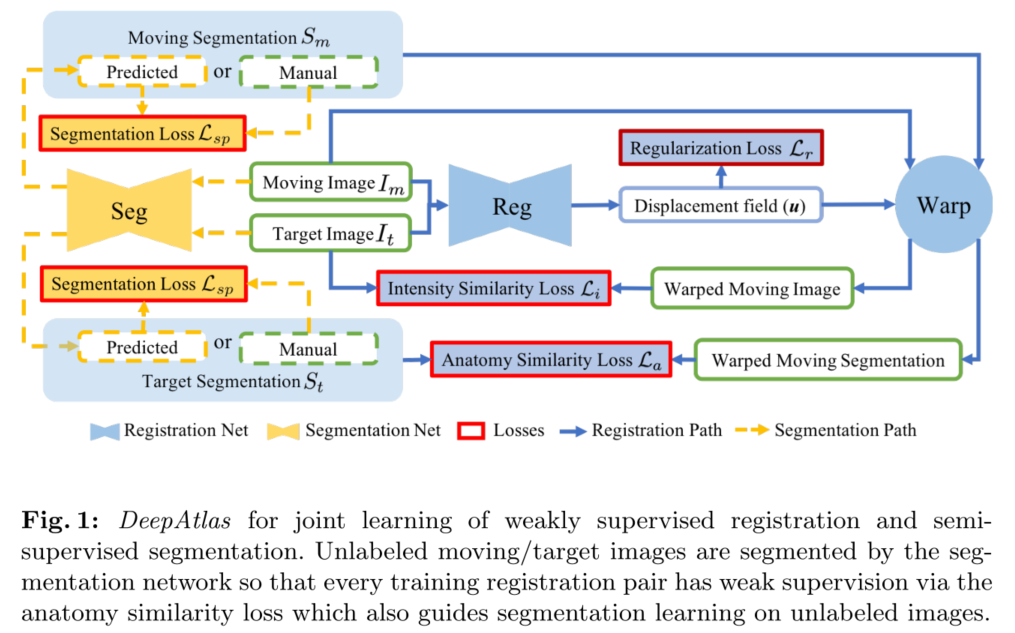
如上图所示,DeepAtlas 包含两个部分:
- 弱监督配准学习(蓝色实线)
由配准正则损失( L r L_r Lr)、图像相似性损失( L i L_i Li)、soft multi-class Dice loss( L a L_a La)的加权相加来训练配准。 - 半监督分割学习(黄色虚线)
由典型的有监督分割损失( L s p L_{sp} Lsp)、soft multi-class Dice loss( L a L_a La)的加权相加来训练分割。
1. Weakly-supervised Registration Learning
输入浮动图像 I m I_m Im 和目标图像 I t I_t It,配准网络 F R \mathcal{F}_{R} FR 及其参数 θ r \theta_r θr 预测出位移场(displacement field) u = F R ( I m , I t ; θ r ) \mathbf{u}=\mathcal{F}_{R}\left(I_{m}, I_{t} ; \theta_{r}\right) u=FR(Im,It;θr)。
经过变形场扭曲的浮动图像为 I m w = I m ∘ Φ − 1 I_{m}^{w}=I_{m} \circ \Phi^{-1} Imw=Im∘Φ−1,其中, Φ − 1 = u + id \Phi^{-1} = \mathbf{u} + \text{id} Φ−1=u+id 为变形场(deformation map),id is the identity transform。
无监督配准学习过程中, L i L_i Li 损失惩罚 I t I_t It 和 I m w I^w_m Imw 的不相似性,正则损失 L r L_r Lr 鼓励生成更加平滑的位移场 u \mathbf{u} u。通过加入定制的 Dice loss L a L_a La 惩罚分割网络得到的伪标签扭曲之后与目标标签的 dice 来达到弱监督配准学习。
Weakly-supervised registration learning is then formulated as:
θ r ⋆ = argmin θ r { L i ( I m ∘ Φ − 1 , I t ) + λ r L r ( Φ − 1 ) + λ a L a ( S m ∘ Φ − 1 , S t ) } \theta_{r}^{\star}=\underset{\theta_{r}}{\operatorname{argmin}}\left\{\mathcal{L}_{i}\left(I_{m} \circ \Phi^{-1}, I_{t}\right)+\lambda_{r} \mathcal{L}_{r}\left(\Phi^{-1}\right)+\lambda_{a} \mathcal{L}_{a}\left(S_{m} \circ \Phi^{-1}, S_{t}\right)\right\} θr⋆=θrargmin{Li(Im∘Φ−1,It)+λrLr(Φ−1)+λaLa(Sm∘Φ−1,St)}
与现有的工作不同,对于没有分割标签的图像,我们通过分割网络预测浮动图像或目标图像的分割。因此,我们对每个训练图像对提供弱监督配准训练。
2. Semi-supervised Segmentation Learning
输入图像 I I I,分割网络 F S \mathcal{F}_{S} FS 及其参数 θ s \theta_s θs 预测出语义分割图: S ^ = F S ( I ; θ s ) \hat{S} = \mathcal{F_S}(I; \theta_s) S^=FS(I;θs)。
对于有手动分割标签 S S S 的图像,使用有监督分割损失 L s p ( S ^ , S ) L_{sp}(\hat{S}, S) Lsp(S^,S) 来衡量。用于配准的定制 Dice loss 也可通过衡量扭曲后的分割和真实标签的相似性 L a ( S m ∘ Φ − 1 , S t ) L_a(S_m \circ \Phi^{-1}, S_t) La(Sm∘Φ−1,St) 来指导半监督分割训练。
总的分割损失定义如下:
L s e g = { λ a L a ( S m ∘ Φ − 1 , F S ( I t ) ) + λ s p L s p ( F S ( I m ) , S m ) , if I t is unlabeled λ a L a ( F S ( I m ) ∘ Φ − 1 , S t ) + λ s p L s p ( F S ( I t ) , S t ) , if I m is unlabeled; λ a L a ( S m ∘ Φ − 1 , S t ) + λ s p L s p ( F S ( I m ) , S m ) , if I m and I t are labeled 0 , if both I t and I m are unlabeled. \mathcal{L}_{s e g}=\left\{\begin{array}{l} \lambda_{a} \mathcal{L}_{a}\left(S_{m} \circ \Phi^{-1}, \mathcal{F}_{\mathcal{S}}\left(I_{t}\right)\right)+\lambda_{s p} \mathcal{L}_{s p}\left(\mathcal{F}_{\mathcal{S}}\left(I_{m}\right), S_{m}\right), \text { if } I_{t} \text { is unlabeled } \\ \lambda_{a} \mathcal{L}_{a}\left(\mathcal{F}_{\mathcal{S}}\left(I_{m}\right) \circ \Phi^{-1}, S_{t}\right)+\lambda_{s p} \mathcal{L}_{s p}\left(\mathcal{F}_{\mathcal{S}}\left(I_{t}\right), S_{t}\right), \text { if } I_{m} \text { is unlabeled; } \\ \lambda_{a} \mathcal{L}_{a}\left(S_{m} \circ \Phi^{-1}, S_{t}\right)+\lambda_{s p} \mathcal{L}_{s p}\left(\mathcal{F}_{\mathcal{S}}\left(I_{m}\right), S_{m}\right), \text { if } I_{m} \text { and } I_{t} \text { are labeled } \\ 0, \text { if both } I_{t} \text { and } I_{m} \text { are unlabeled. } \end{array}\right. Lseg=⎩ ⎨ ⎧λaLa(Sm∘Φ−1,FS(It))+λspLsp(FS(Im),Sm), if It is unlabeled λaLa(FS(Im)∘Φ−1,St)+λspLsp(FS(It),St), if Im is unlabeled; λaLa(Sm∘Φ−1,St)+λspLsp(FS(Im),Sm), if Im and It are labeled 0, if both It and Im are unlabeled.
在目标图像 I t I_t It 没有手动分割标签的情况下, L a L_a La 相当于有监督分割损失,其中 single-atlas 分割 S m ∘ Φ − 1 S_m \circ \Phi^{-1} Sm∘Φ−1 是噪声标签(noisy true label)。
注意,当浮动图像和目标图像都有真实标签的情况下, L a L_a La 不监督分割网络,即 L a L_a La 衡量的是两个真实标签的相似度 L a ( S m ∘ Φ − 1 , S t ) L_a(S_{m} \circ \Phi^{-1}, S_{t}) La(Sm∘Φ−1,St)。
总的来说, I m I_m Im 、 I t I_t It 谁没有手动分割标签,谁就通过分割网络来生成伪标签然后用于半监督训练,最少也要有一个手动分割标签(one-shot)。
实现细节
1. Losses:
-
结构相似性损失( L a L_a La)和有监督分割损失( L s p L_{sp} Lsp):我们使用 soft multi-class Dice loss:3
L dice ( S , S ⋆ ) = 1 − 1 K ∑ k = 1 K ∑ x S k ( x ) S k ⋆ ( x ) ∑ x S k ( x ) + ∑ x S k ⋆ ( x ) \mathcal{L}_{\text {dice }}\left(S, S^{\star}\right)=1-\frac{1}{K} \sum_{k=1}^{K} \frac{\sum_{x} S_{k}(x) S_{k}^{\star}(x)}{\sum_{x} S_{k}(x)+\sum_{x} S_{k}^{\star}(x)} Ldice (S,S⋆)=1−K1k=1∑K∑xSk(x)+∑xSk⋆(x)∑xSk(x)Sk⋆(x)
其中 k 表示一个分割标签(K 个标签中的一个),x 表示体素位置。S 和 S* 是要比较的两个分割。 -
图像相似性损失( L i L_i Li):我们使用归一化互相关(NCC),损失值将在 [0, 2] 区间,鼓励配准图像达到最大相关性。
L i ( I m w , I t ) = 1 − N C C ( I m w , I t ) \mathcal{L_i}(I^w_m, I_t) = 1 - NCC(I^w_m, I_t) Li(Imw,It)=1−NCC(Imw,It) -
正则损失( L r L_r Lr):We use the bending energy:4
L r ( u ) = 1 N ∑ x ∑ i = 1 d ∥ H ( u i ( x ) ) ∥ F 2 \mathcal{L}_{r}(\mathbf{u})=\frac{1}{N} \sum_{\mathbf{x}} \sum_{i=1}^{d}\left\|H\left(u_{i}(\mathbf{x})\right)\right\|_{F}^{2} Lr(u)=N1x∑i=1∑d∥H(ui(x))∥F2
2. 交替训练
在交替训练时,一个固定,一个训练。由于分割网络收敛更快,分割:配准网络交替训练步数为 1 : 20。由于从零开始联合训练是很困难的,所以我们首先分别对单个分割、配准网络进行预训练。
当真实标签数量极少时,比如只有一个,那么从零开始单独训练分割网络是很难的,所以我们最先使用无监督预训练好配准网络,然后再使用这个配准网络从头训练分割网络。直到分割网络能得到合理的结果后,才开始联合训练(交替训练)
3. 网络
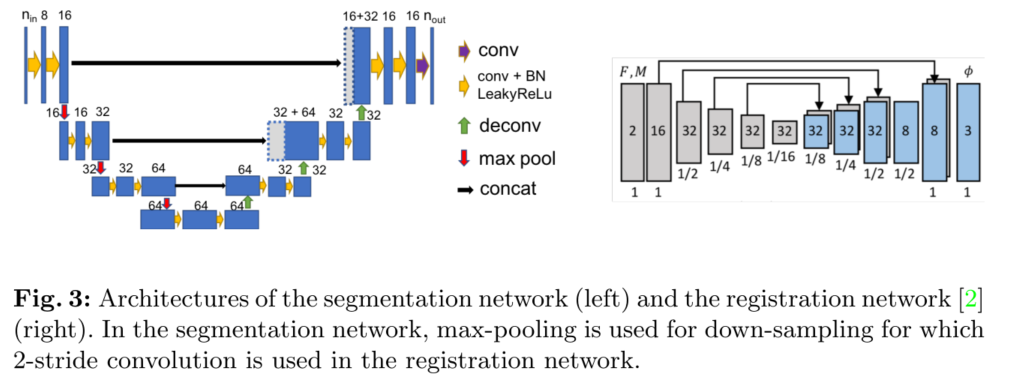
DeepAtlas 可以使用任何 CNN 架构进行配准和分割。我们使用2 的 VoxelMorph 网络进行配准;使用定制的轻量 3D U-Net 网络,结合 LeakyReLU 而不是 ReLU 进行分割。由于 GPU 显存限制,特征图尺寸更小。
实验结果
N of M images are labeled (N << M)。
1. Mono-network:
我们使用单独预训练的分割、配准网络作为 baseline。
以验证这个方法的有效性,而不是因为它能达到 SOTA 性能。
- 对于分割网络:使用全部 N 个有标签图像进行全监督训练。
- 对于配准网络:使用全部 M 个图像进行训练。结构相似性 Dice loss( L a L_a La)只用在当输入的两个图像都真实标签的情况下。
2. DeepAtlas(DA):
我们使用以上单独训练的 mono-network 来初始化用于联合训练的模型。
考虑 one-shot 的情况(N = 1),我们设计了 Semi-DeepAtlas(Semi-DA):固定无监督(N = 0)预训练好的配准模型,用于从零训练分割网络(N = 1)。
最终,DA 模型使用 Semi-DA 训练好的分割模型和无监督预训练好的配准模型来初始化。
3. Brain MRI experiment:
我们在带有 32 个皮质区域的 Mindbooggle101 5 脑部 MRI 上评估了我们的方法。我们融合了左右脑半球相应的分割标签。
MindBoogle101 由来自多个数据集的图像组成,例如 OASIS-TRT-20、MMRR-21 和 HLN-12。删除带有不正确标签的图像后,我们总共获得 85 幅图像。
我们使用来自 OASIS-TRT-20 的 5 幅图像作为验证集,15 幅图像作为测试集。我们使用剩下的 65 幅图像进行训练。N = 1 和 N = 21 实验中的真实标签仅来自 MMRR-21 子集;这模拟了一个常见的实际用例:我们只有一个数据集的真实标签用于训练,但希望处理一个不同的没有标签的新数据集。
所有图像均为 1mm 各向同性,仿射对齐,直方图匹配,裁剪为 168×200×169 大小。我们采用矢量翻转(sagittal flipping)来增强数据。除了
λ
r
=
5000
λ_r = 5000
λr=5000 外,我们使用与膝关节 MRI 实验相同的损失权重,因为跨受试者大脑配准需要大变形,因此正则化权重较低。
4. Optimizer:
我们用 Adam。Mono-network 的初始学习速率为 1e-3。配准网络的初始学习率为 5e-4,Semi-DA 和 DA 的分割网络的初始学习率为 1e-4。在实验的不同时期,学习率下降 0.2。使用 PyTorch,在 Nvidia V100 GPU 上训练,显存为 16GB。
5. Results:
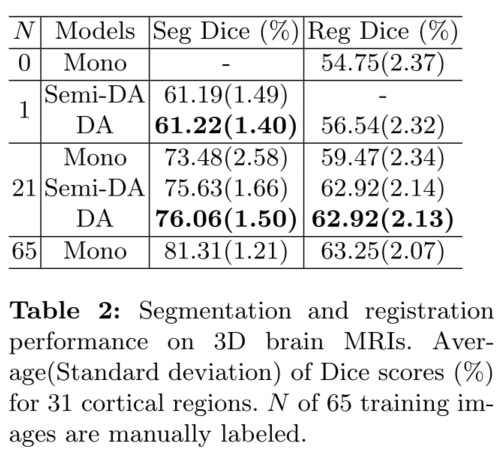
分割网络的 Dice 值都是计算真实标签和分割标签的 Dice 重叠分数;配准网络的 Dice 值都是计算目标图像真实标签和浮动图像扭曲后的分割标签的 Dice 重叠分数。
-
General results:在少量标签的情况下,相对于 Mono-network,Semi-DA 能提升 Dice 值,而 DA 更比 Semi-DA 强。这表明,分割和配准确实可以通过对无标签数据提供伪标签而起到相互监督的效果。
-
Brain results:对于 Brain MRI 的皮层结构,分割和配准的 Dice 值分别增加了约 2.6 和 3.5。
-
One-shot learning:在两个数据集上的 one-shot 实验中,都取得了合理的分割性能;此外,DA 在膝盖和大脑数据上的 Dice 分数比无监督配准分别增加了约 2.7 和 1.8。这证明了我们的框架在 one-shot 情况下的有效性。
结论
我们提出了 DeepAtlas 框架,用于仅使用少量标注图像的分割和配准网络的联合学习。通过引入结构相似性损失 L a L_a La,学习到的配准在解剖学上更加一致。此外,分割网络得益于在无标签图像上预训练好的配准网络提供的数据增强。
当只给出一个真实分割标签时,我们的方法提供了 one-shot 分割学习,大大提高了配准效果。这表明,一个网络可以受益于对另一个网络提供的无标签数据的不完善监督。我们的方法为训练分割和配准网络时缺少真实分割标签提供了一个通用的解决方案。
在未来的工作中,为分割和配准网络引入不确定性评估可能有助于缓解一个网络对另一个网络提供不佳预测的影响。通过分割和配准网络的层间共享来研究多任务学习也很有意义。这可能进一步提高性能并减小模型尺寸。
引入模态独立自相似性 MIND-SSC Loss 来实现多模态配准6 7(把图像强度相似性度量 L i L_i Li 换成 MIND-SSC)、引入不确定性评估8 9、层间共享来研究多任务学习10、 L r L_r Lr 或许也需要换成
diffusion regularisation loss,见 pdd2.5。
Balakrishnan, G., Zhao, A., Sabuncu, M.R., Guttag, J., Dalca, A.V.: An unsupervised learning model for deformable medical image registration. In: CVPR. pp. 9252–9260 (2018) ↩︎
Balakrishnan, G., Zhao, A., Sabuncu, M.R., Guttag, J., Dalca, A.V.: Voxelmorph: a learning framework for deformable medical image registration. IEEE TMI (2019) ↩︎ ↩︎
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: MICCAI. pp. 234–241. Springer (2015) ↩︎
Rueckert, D., Sonoda, L.I., Hayes, C., Hill, D.L.G., Leach, M.O., Hawkes, D.J.: Nonrigid registration using free-form deformations: application to breast mr images. IEEE TMI 18(8), 712–721 (Aug 1999). https://doi.org/10.1109/42.796284 ↩︎
Klein, A., Tourville, J.: 101 labeled brain images and a consistent human cortical labeling protocol. Frontiers in Neuroscience 6, 171 (2012). https://doi.org/10.3389/fnins.2012.00171 ↩︎
Heinrich, M., and L. Hansen. “Highly Accurate and Memory Efficient Unsupervised Learning-Based Discrete Ct Registration Using 2.5d Displacement Search.” Paper presented at the Medical Image Computing and Computer Assisted Intervention(MICCAI), 2020. ↩︎
Ge, Yixiao, Da-peng Chen, and Hongsheng Li. “Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-Identification.” International Conference on Learning Representations(ICLR) (2020). ↩︎
Yu, Lequan, Shujun Wang, X. Li, C. Fu, and P. Heng. “Uncertainty-Aware Self-Ensembling Model for Semi-Supervised 3d Left Atrium Segmentation.” Paper presented at the MICCAI, 2019. ↩︎
Théo Estienne, et al. “Deep Learning-Based Registration Using Spatial Gradients and Noisy Segmentation Labels.” MICCAI 2020 ↩︎
















 4587
4587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











